









文章目录
大家好,为了让大家更好的学习大模型,接下来我会系列分享大模型常考的面试知识,喜欢本文记得收藏、关注、点赞。更多技术、面试交流,加入文末我们的社群。
1. 主流结构
目前LLM(Large Language Model)主流结构包括三种范式,分别为Encoder-Decoder、Causal Decoder、Prefix Decoder,如下图所示:
-
Encoder-Decoder
结构特点:输入双向注意力,输出单向注意力
代表模型:T5、Flan-T5、BART -
Causal Decoder
结构特点:从左到右的单向注意力
代表模型:LLaMA1/2系列、LLaMA衍生物 -
Prefix Decoder
结构特点:输入双向注意力,输出单向注意力
代表模型:ChatGLM、ChatGLM2、U-PaLM
2. 结构对比
三种结构主要区别在于Attention Mask不同,如下图所示:

-
Encoder-Decoder
特点:在输入上采用双向注意力,对问题的编码理解更充分;
缺点:在长文本生成任务上效果差,训练效率低;
适用任务:在偏理解的 NLP 任务上效果好。 -
Causal Decoder
特点:自回归语言模型,预训练和下游应用是完全一致的,严格遵守只有后面的token才能看到前面的token的规则;
优点:训练效率高,zero-shot 能力更强,具有涌现能力;
适用任务:文本生成任务效果好 -
Prefix Decoder
特点:Prefix部分的token互相能看到,属于Causal Decoder 和 Encoder-Decoder 的折中;
缺点:训练效率低。
3. 训练目标
- 语言模型
根据已有词预测下一个词,即Next Token Prediction,是目前大模型所采用的最主流训练方式,训练目标为最大似然函数:
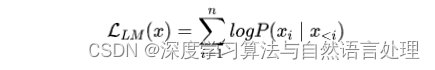
训练效率:Prefix Decoder < Causal Decoder
Causal Decoder 结构会在所有token上计算损失,而Prefix Decoder只会在输出上计算损失。
- 去噪自编码器
随机替换掉一些文本段,训练语言模型去恢复被打乱的文本段,即完形填空,训练目标函数为:

去噪自编码器的实现难度更高,采用去噪自编码器作为训练目标的任务有GLM-130B、T5等。
根据 OpenAI 联合创始人 Andrej Karpathy 在微软 Build 2023 大会上所公开的信息,OpenAI 所使用的大规模语言模型构建流程如下图1所示。主要包含四个阶段:预训练、有监督微调、奖励建模、强化学习。这四个阶段都需要不同规模数据集合以及不同类型的算法,会产出不同类型的模 型,同时所需要的资源也有非常大的差别。

4、预训练(Pretraining)
该阶段需要利用海量的训练数据,包括互联网网页、维基百科、书籍、GitHub、 论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。利用由数千块高性能 GPU 和高速网络组成超级计算机,花费数十天完成深度神经网络参数训练,构建基础语言模型 (Base Model)。**基础大模型构建了长文本的建模能力,使得模型具有语言生成能力,根据输入的提示词(Prompt),模型可以生成文本补全句子。也有部分研究人员认为,语言模型建模过程中也隐含的构建了包括事实性知识(Factual Knowledge)和常识知识(Commonsense)在内的世界知识(World Knowledge)。**根据文献 [1] 介绍,GPT-3 完成一次训练的总计算量是 3640PFlops,按照 NVIDIA A100 80G 和平均利用率达到 50% 计算,需要花费近一个月时间使用 1000 块 GPU 完成。
由于 GPT-3 训练采用了 NVIDIA V100 32G,其实际计算成本远高于上述计算。文献 [2] 介绍了参数量同样是 1750 亿的 OPT 模型,该模型训练使用了 992 块 NVIDIA A100 80G,整体训练时间将近 2 个月。BLOOM[3] 模型的参数量也是 1750 亿,该模型训练一共花费 3.5 个月,使用包含 384 块 NVIDIA A100 80G GPU 集群完成。可以看到大规模语言模型的训练需要花费大量的计算资源和时间。包括 LLaMA 系列、Falcon 系列、百川(Baichuan)系列等在模型都属于此阶段。由于训 练过程需要消耗大量的计算资源,并很容易受到超参数影响,如何能够提升分布式计算效率并使得模型训练稳定收敛是本阶段的重点研究内容。
5、有监督微调(Supervised Finetuning)
该阶段也称为指令微调(Instruction Tuning),利用少量高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务。
例如:
提示词(Prompt):复旦大学有几个校区?
理想输出:复旦大学现有 4 个校区,分别是邯郸校区、新江湾校区、枫林校区和张江校区。
其中邯郸校区是复旦大学的主校区,邯郸校区与新江湾校区都位于杨浦区,枫林校区位于徐汇区,张江校区位于浦东新区。
利用这些有监督数据,使用与预训练阶段相同的语言模型训练算法,在基础语言模型基础上再进行训练,从而得到有监督微调模型(SFT 模型)。经过训练的 SFT 模型具备了初步的指令理解能力和上下文理解能力,能够完成开放领域问题、阅读理解、翻译、生成代码等能力,也具备了一定的对未知任务的泛化能力。由于有监督微调阶段的所需的训练语料数量较少,SFT 模型的训练过程并不需要消耗非常大量的计算。根据模型的大小和训练数据量,通常需要数十块 GPU,花费数天时间完成训练。SFT 模型具备了初步的任务完成能力,可以开放给用户使用,很多类 ChatGPT的模型都属于该类型,包括:Alpaca[4]、Vicuna[5]、MOSS、ChatGLM-6B 等。很多这类模型效果也非常好,甚至在一些评测中达到了 ChatGPT 的 90% 的效果[4, 5]。当前的一些研究表明有监督微调阶段数据选择对 SFT 模型效果有非常大的影响[6],因此如何构造少量并且高质量的训练数据是本阶段有监督微调阶段的研究重点。
6、奖励建模(Reward Modeling)
该阶段目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。奖励模型(RM 模型)可以通过二分类模型,对输入的两个结果之间的优劣进行判断。RM 模型与基础语言模型和 SFT 模型不同,RM 模型本身并不能单独提供给用户使用。 奖励模型的训练通常和 SFT 模型一样,使用数十块 GPU,通过几天时间完成训练。由于 RM 模型的准确率对于强化学习阶段的效果有着至关重要的影响,因此对于该模型的训练通常需要大规模的训练数据。 Andrej Karpathy 在报告中指出,该部分需要百万量级的对比数据标注,而且其中很多标注需要花费非常长的时间才能完成。下图2给出了 InstructGPT 系统中奖励模型训练样本标注示例[7]。可以看到,示例中文本表达都较为流畅,标注其质量排序需要制定非常详细的规范,标注人员也需要非常认真的对标规范内容进行标注,需要消耗大量的人力,同时如何保持众包标注人员之间的一致性,也是奖励建模阶段需要解决的难点问题之一。 此外奖励模型的泛化能力边界也在本阶段需要重点研究的另一个问题。如果 RM 模型的目标是针对所有提示词系统所生成输出都能够高质量的进行判断,该问题所面临的难度在某种程度上与文本生成等价,因此如何限定 RM 模型应用的泛化边界也是本阶段难点问题。

7、强化学习(Reinforcement Learning)
该阶段根据数十万用户给出的提示词,利用在前一阶段训练的 RM 模型,给出 SFT 模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。该阶段所使用的提示词数量与有监督微调阶段类似,数量在十万量级,并且不需要人工提前给出该提示词所对应的理想回复。使用强化学习,在 SFT 模型基础上调整参数,使得最终生成的文本可以获得更高的奖励(Reward)。该阶段所需要的计算量相较预训练阶段也少很多, 通常也仅需要数十块 GPU,经过数天时间的即可完成训练。文献 [7] 给出了强化学习和有监督微调的对比,在模型参数量相同的情况下,强化学习可以得到相较于有监督微调好得多的效果。关 于为什么强化学习相比有监督微调可以得到更好结果的问题,截止到 2023 年 9 月也还没有完整和得到普遍共识的解释。此外,Andrej Karpathy 也指出强化学习也并不是没有问题的,它会使得基础模型的熵降低,从而减少了模型输出的多样性。** 在经过强化学习方法训练完成后的 RL 模型,就是最终提供给用户使用具有理解用户指令和上下文的类 ChatGPT 系统。**由于强化学习方法稳定性不高,并且超参数众多,使得模型收敛难度大,再叠加 RM 模型的准确率问题,使得在大规模 语言模型如何能够有效应用强化学习非常困难。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了大模型算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
用通俗易懂方式讲解系列
参考文献
[1] Brown T B, Mann B, Ryder N, et al. Language models are few-shot learners[J]. arXiv preprint arXiv:2005.14165, 2020.
[2] Zhang S, Roller S, Goyal N, et al. Opt: Open pre-trained transformer language models[J]. arXiv preprint arXiv:2205.01068, 2022.
[3] Scao T L, Fan A, Akiki C, et al. Bloom: A 176b-parameter open-access multilingual language model[J]. arXiv preprint arXiv:2211.05100, 2022.
[4] Taori R, Gulrajani I, Zhang T, et al. Stanford alpaca: An instruction-following llama model[J/OL].
GitHub repository, 2023. https://github.com/tatsu-lab/stanford_alpaca.
[5] Chiang W L, Li Z, Lin Z, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality[J]. See https://vicuna. lmsys. org (accessed 14 April 2023), 2023.
[6] Zhou C, Liu P, Xu P, et al. Lima: Less is more for alignment[J]. arXiv preprint arXiv:2305.11206, 2023.
[7] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35:27730-27744.


















 7209
7209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









