






本文主要侧重介绍新的prompt内容,在原来的prompt的中,我们是基于原.ann格式文件进行prompt的编写,其详情可以见该博客基于autodl与llama-factory微调llama3(二)-CSDN博客
对于我们新的json格式内容,我们还需要使大模型能够提供对应的输出,因此我们采用如下重新设计好的prompt内容:
Extract the following data from the given medical abstract and output in the specified JSON format: Fixed Data: - Total participants: The total number of participants in the study. - Intervention participants: The number of participants in the intervention group. - Control participants: The number of participants in the control group. - Age: The age range or average age of participants. - Intervention age: The age range or average age of participants in the intervention group. - Control age: The age range or average age of participants in the control group. - Eligibility: The eligibility criteria for participants. - Condition: The medical condition or conditions being studied. - Location: The location(s) where the study was conducted. - Ethnicity: The ethnicity of participants. - Intervention: The type of intervention used. - Control: The type of control used. - Outcome measure: The primary outcome measure(s) of the study. - Conclusion: The conclusion of the study. Variable Data (for each outcome event): - Outcome: The outcome event being described. - IV Bin Abs: The absolute number of intervention group participants with the outcome. - CV Bin Abs: The absolute number of control group participants with the outcome. - IV Bin Percent: The percentage of intervention group participants with the outcome. - CV Bin Percent: The percentage of control group participants with the outcome. - IV Cont Mean: The mean value of the outcome measure for the intervention group. - CV Cont Mean: The mean value of the outcome measure for the control group. - IV Cont Median: The median value of the outcome measure for the intervention group. - CV Cont Median: The median value of the outcome measure for the control group. - IV Cont SD: The standard deviation of the outcome measure for the intervention group. - CV Cont SD: The standard deviation of the outcome measure for the control group. Note: The variable_data array can contain multiple outcome objects. Output in the following JSON format: { "fixed_data": { "total-participants": "", "intervention-participants": "", "control-participants": "", "age": [], "intervention-age": "", "control-age": "", "eligibility": "", "condition": [], "location": "", "ethnicity": "", "intervention": "", "control": "", "outcome-measure": "", "conclusion": "" }, "variable_data": [ { "outcome": "", "iv-bin-abs": "", "cv-bin-abs": "", "iv-bin-percent": "", "cv-bin-percent": "", "iv-cont-mean": "", "cv-cont-mean": "", "iv-cont-median": "", "cv-cont-median": "", "iv-cont-sd": "", "cv-cont-sd": "" } ] }
具体组成为:
文字提示要求——各属性含义——所需要格式
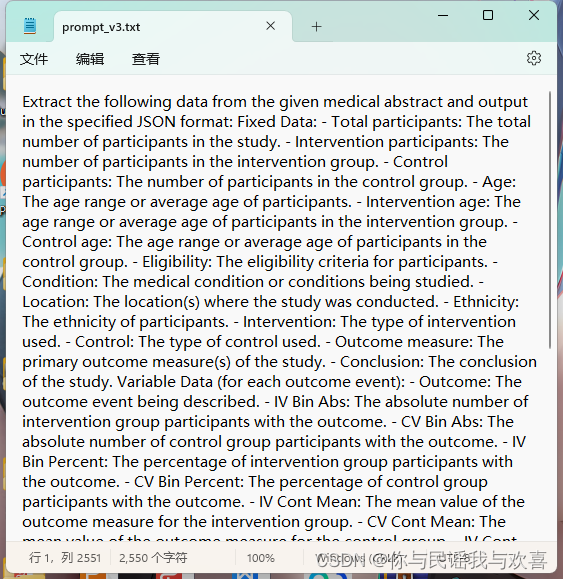
1.对于文字提示:我们初步的设定为,“从给定的医学摘要中提取以下数据,并以指定的JSON格式输出:”
2.各属性含义:
固定数据:
-干预参与者:干预组的参与者人数。
-控制组人数:控制组的人数。
-年龄:参与者的年龄范围或平均年龄。
-干预年龄:干预组参与者的年龄范围或平均年龄。
-对照组年龄:对照组参与者的年龄范围或平均年龄。
-资格:参与者的资格标准。
-状况:正在研究的医疗状况。
-地点:进行研究的地点。
-种族:参与者的种族。
-干预:使用的干预类型。
-Control:使用的控件类型。
-结局指标:研究的主要结局指标。
-结论:研究的结论。
可变数据(每个结果事件):
-结局:描述的结果事件。
- IV Bin Abs:具有结果的干预组参与者的绝对数量。
- CV Bin Abs:具有结果的对照组参与者的绝对数量。
- IV Bin Percent:干预组参与者达到结果的百分比。
- CV Bin Percent:对照组参与者与结果的百分比。
- IV均值:干预组结果测量值的平均值。
- CV均值:对照组结果测量值的平均值。
- IV Cont Median:干预组结果测量值的中位数。
- CV Cont Median:对照组结果测量值的中位数。
- IV Cont SD:干预组结果测量的标准差。
- CV Cont SD:对照组结果测量值的标准差。
提示:variable_data数组可以包含多个结果对象
3.格式说明:
输出以下JSON格式:(注意,在数据集的脚本中,一定要用转义字符去表示所有的双引号,否则会使其无法表示成一个string数据)
{" fixed_data ":{“总参与”:“”,“intervention-participants”:“”,“控制组”:“”,“年龄”:[],“intervention-age”:“”,“control-age”:“”,“资格”:“”,“条件”:[],“位置”:“”,“种族”:“”,“干预”:“”,“控制”:“”,“测量结果”:“,”的结论 ": "" }, " variable_data”:[{“结果”:“”,“iv-bin-abs”:“”,“cv-bin-abs”:“”,“iv-bin-percent”:“”,“cv-bin-percent”:“”,“iv-cont-mean”:“”,“cv-cont-mean”:“”、“iv-cont-median”:“”,“cv-cont-median”:“”,“iv-cont-sd”:cv-cont-sd”“。 ": "" } ] }
结果:
基于该prompt,llama3模型的输出结果整体能够呈现出我们需要的格式,但是在诸如年龄提取、结果提取以及对于abs和percent的判断,很存在一些比较明显的偏差。除此以外,我们归纳出了模型输出最最严重的三类问题:
幻觉输出:大模型出现幻觉,简而言之就是“胡说八道”。即模型生成的内容与现实世界事实或用户输入不一致的现象。幻觉的三大来源:数据源、训练过程和推理。
无中生有:即大模型会突然出现任何地方都没有出现过的内容,自我生成崭新的不符合要求的内容。
提取对应不正确:即对应的属性无法匹配上对应的原文结果。
针对此次实验后,我们已经发现我们的模型输出结果有了显著的样式提升。因此我们的微调数据集将在此基础上不再额外做过多的修改,解决上述三种现象将是我们后续优化的前进方向。















 2383
2383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









