






 本文详细介绍了如何利用YOLO目标检测算法进行一个项目,包括Python环境配置、数据集准备(包括标注和划分)、模型训练(涉及参数设置和优化)、以及测试评估(计算准确率和性能指标)。
本文详细介绍了如何利用YOLO目标检测算法进行一个项目,包括Python环境配置、数据集准备(包括标注和划分)、模型训练(涉及参数设置和优化)、以及测试评估(计算准确率和性能指标)。
一、项目背景
随着人工智能技术的发展,计算机视觉任务在各个领域中的应用日益广泛。目标检测是计算机视觉领域的一个重要任务,旨在从图像中识别并定位出感兴趣的目标对象。近年来,随着深度学习技术的飞速发展,目标检测算法取得了显著进步。YOLO(You Only Look Once)作为一种实时目标检测算法,因其高速度和良好性能和精度的优势而受到了广泛的关注和应用。本文将详细介绍一个基于YOLO的目标检测项目,包括项目环境搭建、数据集准备、模型训练以及测试评估等方面。
二、项目环境搭建
安装Python和必要的库,此实验需要使用Python和PyTorch框架进行实现使用pip安装所需的库,如TensorFlow、Keras、OpenCV等。这些库将用于构建和运行YOLO目标检测模型并且确保计算机拥有足够的GPU与内存资源,以便进行模型训练和测试。为了训练和验证YOLO模型,需要准备一个包含标注目标对象的数据集。通常,这些数据集由一系列图像和相应的标注文件组成,标注文件包含了图像中目标对象的位置和类别信息。利用软件labellmg标注好的数据集,提前找好一百张以上的训练照片,并将其按照YOLOv4的格式进行转换。
数据集准备:
收集数据集:根据项目需求,收集包含目标对象的图像数据集。确保数据集的多样性和丰富性,以提高模型的泛化能力。
数据标注:使用标注工具对收集到的图像进行标注,生成包含目标对象位置和类别的标签文件。这些标签文件将用于模型训练时的监督学习。
数据划分:将数据集划分为训练集、验证集和测试集。通常,训练集用于训练模型,验证集用于调整超参数和监控训练过程,测试集用于评估模型的性能。
三、实验步骤
(一)开源代码准备
检测开始之前需要先获取开源代码,包括YOLO算法代码“yolov4-pytorch-master”和框图程序“labelImg_exe”两部分。
(二)搭配环境
1.安装相关库
确认计算机已经安装了较新版本的Python和PyTorch。在开始之前,需要安装一些必要的Python库。安装这些库的相关命令:
pip install opencv-python:用于图像处理和目标检测结果的可视化
pip install pillow:用于图像处理和转换
pip install numpy:用于数值计算和数组操作
pip install onnx:用于模型转换和部署
pip install tensorboard:用于可视化训练过程中的损失和准确率等指标
pip install tqdm:一个快速、可扩展的Python进度条库,用于显示循环的进度
2.准备数据集
将训练集图片保存至代码文件的JPEGImages目录文件中:
yolov4-pytorch-master\VOCdevkit\VOC2007\JPEGImages
3.图像标注
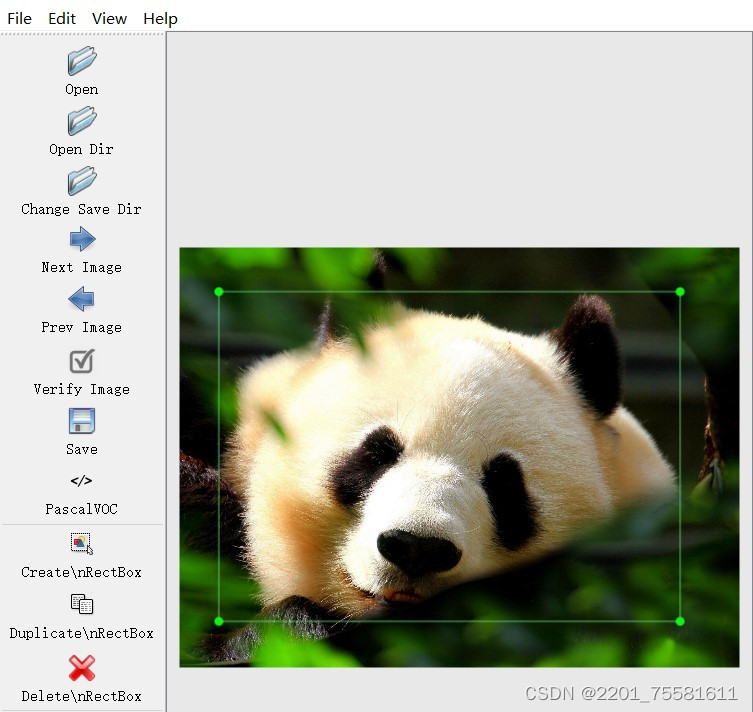
①打开框选软件labelImg.exe作为标注工具;
②首先打开“Change Save Dir”选择框选完的图片保存位置:
yolov4-pytorch-master\VOCdevkit\VOC2007\Annotations
“open”打开JPEGImages文件夹选择图片;
③使用“Create\nRectBox”框选目标,且输入识别标签并保存,保存好的图片就会生成对应的xml文件,其中包含目标物体的边界框坐标、类别等信息。
(三)运行代码
1.修改检测类别名文件:coco_classes.txt和voc_classes.txt文本文件,将里面的标签名改为自己前面设置的标签名,每个类别占一行,确保类别的命名准确且一致;
2.数据处理:需要使用voc_annotation.py脚本来生成训练所需的2007_train.txt和2007_val.txt文件。这两个文件包含了训练集和验证集中图片的路径以及对应的标注信息。运行结果如下:
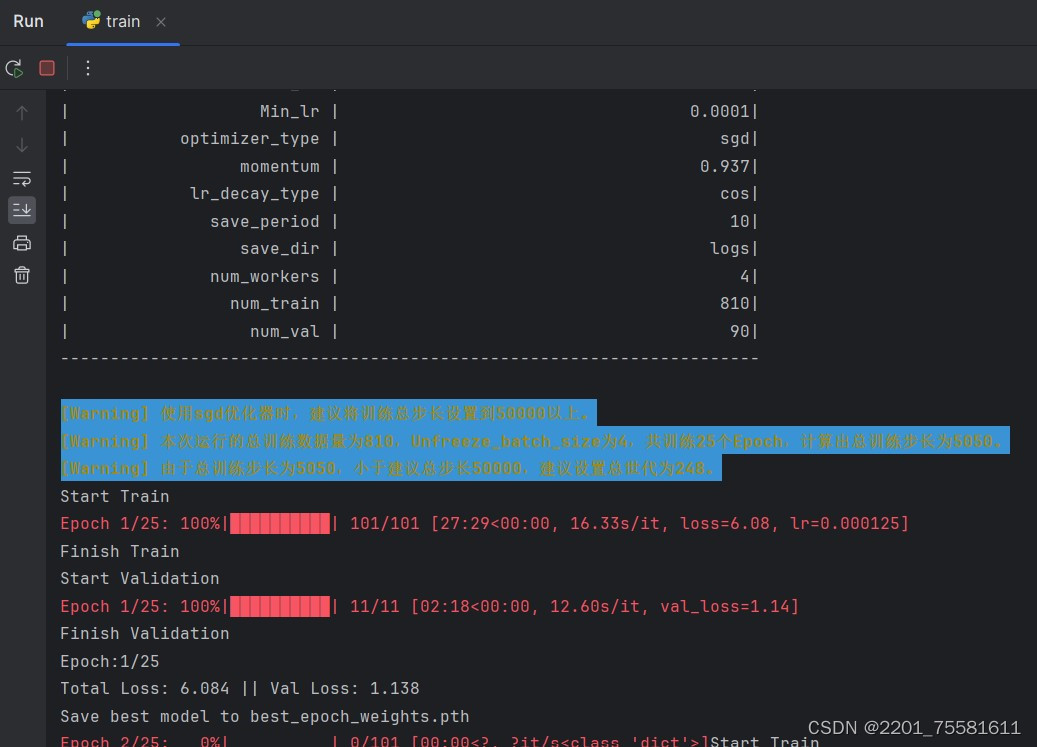
3.训练模型:运行代码train.py。可以根据选择训练的次数,但是训练次数过少会导致,无法选中图像。
(四)训练结果预测
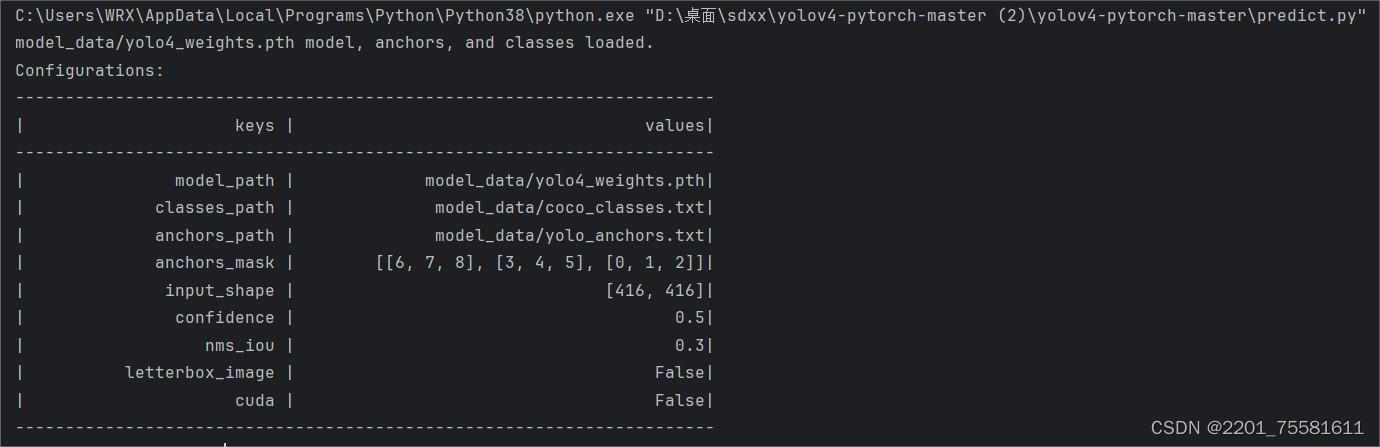
1.主要文件:预测时,运行预测使用yolo.py和predict.py。在yolo.py中,需要修改model_path和classes_path使其对应自己的数据集。model_path指向训练好的权重文件;classes_path指向类别文本文件(.txt)。
2.训练权重: 在yolo.py文件里面,在如下部分修改model_path和classes_path使其对应自己需要训练好的文件就可以运行predict.py文件来进行预测了。
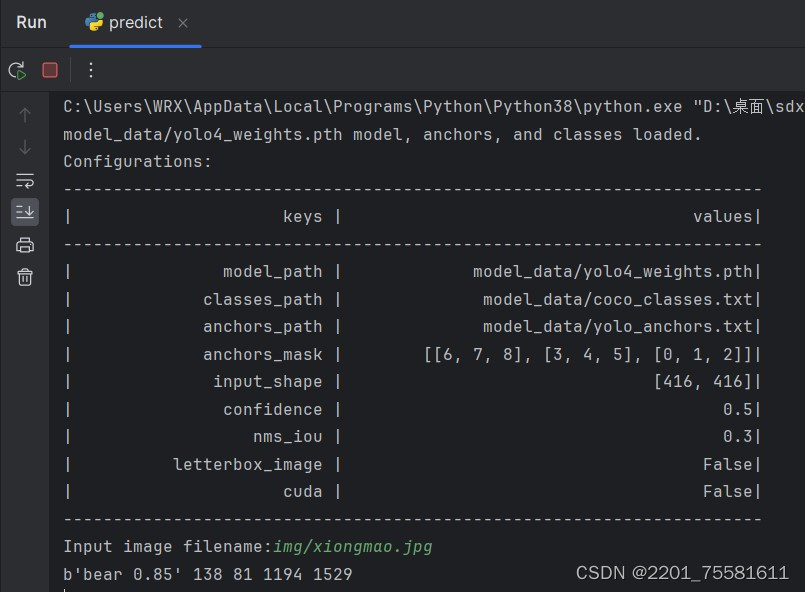
3.输入预测图片:最后选择需要预测的图片就能预测结果了

四、模型训练
配置训练参数:根据实际需求,设置训练过程中的超参数,如学习率、批次大小、训练轮数等。
加载预训练模型:加载下载的YOLO预训练模型,将其作为起点进行微调训练。
训练模型:使用训练集和验证集对模型进行训练。在训练过程中,监控模型的损失和准确率等指标,以及时调整训练参数和防止过拟合。
使用准备好的数据集,我们可以开始训练YOLO模型。在训练过程中,我们采用了随机梯度下降(SGD)等优化算法来最小化损失函数。为了提高模型的性能,我们还采用了多种优化策略,如学习率衰减、正则化等。此外,我们还对模型的结构和超参数进行了调整,以找到最佳的配置。
五、测试评估
在模型训练完成后,我们在测试集上进行了评估,并得到了模型的准确率和性能指标(如mAP、FPS等)。通过与其他目标检测算法的比较,我们发现YOLO算法在保持较高准确率的同时,还具有较快的运行速度。此外,我们还对实验结果进行了详细的分析和讨论,探讨了模型在不同场景下的性能表现和潜在改进空间。
加载训练好的模型:训练完成后,加载保存的训练好的模型。
测试模型性能:使用测试集对模型进行测试,计算模型的准确率、召回率、F1值等性能指标。同时,可以绘制PR曲线和ROC曲线等可视化工具来评估模型的性能。
目标检测效果展示:对测试集中的图像进行目标检测,并展示检测结果。可以通过绘制边界框和标注类别等方式来直观地展示目标检测的效果。















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









