







1、增加数据集
2、正则化(Regularization)
正则化:得到一个更加简单的模型的方法。
以一个多项式为例:![]()
随着最高次的增加,会得到一个更加复杂模型,模型越复杂就会更好的拟合输入数据的模型(图-1),拟合的程度越大,表现在参数上的现象就是高次的系数趋近于0,如果直接将趋近于0的高次去掉,就可以得到一个更加简单的模型,这种方法称为正则化。
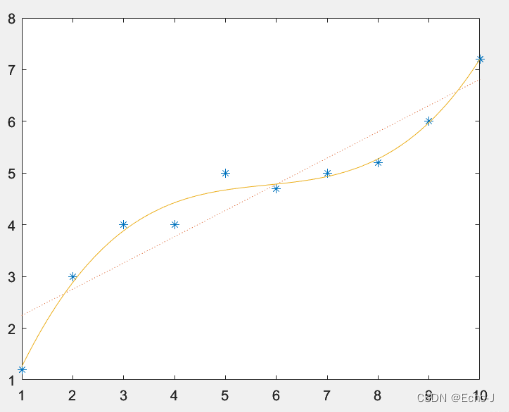
直观的看,经过正则化的模型更加平滑(图-2).
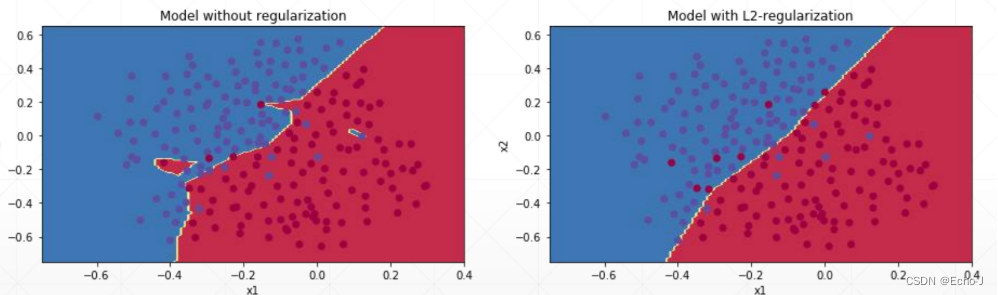
正则化的方法:
(1)L1-正则化:在原来的模型基础上加上一个 1-范数(这里使用二分类模型作为示例):
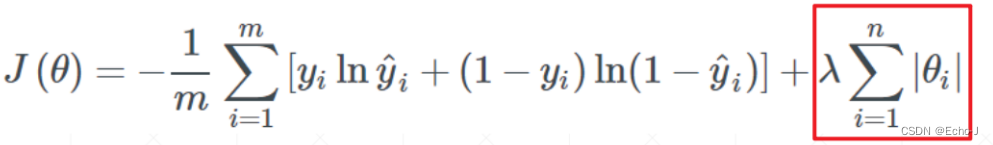
(2)L2-正则化:在原来的模型基础上加上一个 2-范数(这里使用二分类模型作为示例):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









