







1 ACGAN基本原理
1.2 ACGAN模型解释
ACGAN相对于CGAN使的判别器不仅可以判别真假,也可以判别类别 。通过对生成数据类别的判断,判别器可以更好地传递loss函数使得生成器能够更加准确地找到label对应的噪声分布,通过下图告诉了我们ACGAN与CGAN的异同之处 :
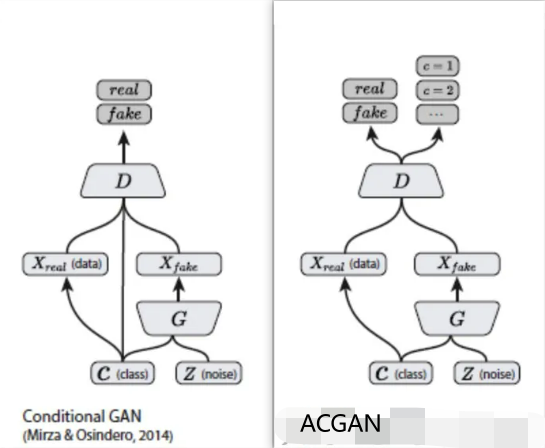
对于CGAN和ACGAN,生成器输入均为潜在矢量及其标签,输出是属于输入类标签的伪造数据。对于CGAN,判别器的输入是数据(包含假的或真实的数据)及其标签, 输出是图像属于真实数据的概率。对于ACGAN,判别器的输入是数据,而输出是该图像属于真实数据的概率以及其类别概率。
在ACGAN中,对于生成器来说有两个输入,一个是标签的分类数据c,另一个是随机数据z,得到生成数据为 ;对于判别器,产生跨域标签和源数据的概率分布
1.2 ACGAN损失函数
对于判别器而言,即希望分类正确,有希望能正确分辨数据的真假;对于生成器而言,也希望分类正确,但希望判别器不能正确分辨真假。因此在训练判别器的时候,我们希望LSE+LCS最大化;在训练生成器的时候,我们希望LCS-LSE最大化。

logP(SR = real | Xreal)表示鉴别器将真实样本源正确分类为真实样本的对数似然;logP(SR = fake | Xfake)表示鉴别器正确地将假样本的来源分类为假样本的对数似然E[.]表示所有样本的平均值logP(CS = CS | Xreal)表示鉴别器正确分类真实样本的对数似然logP(CS = CS | Xfake)表示鉴别器正确分类具有正确类别标签的假样本的对数似然
判别器的损失函数 = LSE + LCS;生成器的损失函数 = LCS - LSE
- LSE测量鉴别器正确区分样本是真还是假的程度。这有助于鉴别器熟练地识别来源(真实的或生成的)。
- LCS确保生成的样本不仅看起来真实,而且携带正确的类信息。它引导生成器在不同的类中产生多样化和现实的样本。
2 ACGAN pytorch代码实现
完整代码链接:https://github.com/znxlwm/pytorch-generative-model-collections/tree/master
(但是这个代码我训练的时候损失函数也对应的上,得到的图片是黑乎乎的一片,也不知道是什么原因,如果知道的师傅可以麻烦告知一下吗?)
这个代码在训练ACGAN模型的时候加载数据集的时候会出现问题,因为我使用的是minist数据集,所以应该改为单通道的:

import utils, torch, time, os, pickle
import numpy as np
import torch.nn as nn
import torch.optim as optim
from dataloader import dataloader
class generator(nn.Module):
# Network Architecture is exactly same as in infoGAN (https://arxiv.org/abs/1606.03657)
# Architecture : FC1024_BR-FC7x7x128_BR-(64)4dc2s_BR-(1)4dc2s_S
def __init__(self, input_dim=100, output_dim=1, input_size=32, class_num=10):
super(generator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.input_size = input_size
self.class_num = class_num
self.fc = nn.Sequential(
nn.Linear(self.input_dim + self.class_num, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * (self.input_size // 4) * (self.input_size // 4)),
nn.BatchNorm1d(128 * (self.input_size // 4) * (self.input_size // 4)),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
utils.initialize_weights(self)
def forward(self, input, label):
x = torch.cat([input, label], 1)
x = self.fc(x)
x = x.view(-1, 128, (self.input_size // 4), (self.input_size // 4))
x = self.deconv(x)
return x
class discriminator(nn.Module):
# Network Architecture is exactly same as in infoGAN (https://arxiv.org/abs/1606.03657)
# Architecture : (64)4c2s-(128)4c2s_BL-FC1024_BL-FC1_S
def __init__(self, input_dim=1, output_dim=1, input_size=32, class_num=10):
super(discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.input_size = input_size
self.class_num = class_num
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc1 = nn.Sequential(
nn.Linear(128 * (self.input_size // 4) * (self.input_size // 4), 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
)
self.dc = nn.Sequential(
nn.Linear(1024, self.output_dim),
nn.Sigmoid(),
)
self.cl = nn.Sequential(
nn.Linear(1024, self.class_num),
)
utils.initialize_weights(self)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * (self.input_size // 4) * (self.input_size // 4))
x = self.fc1(x)
d = self.dc(x)
c = self.cl(x)
return d, c
class ACGAN(object):
def __init__(self, args):
# parameters
self.epoch = args.epoch
self.sample_num = 100
self.batch_size = args.batch_size
self.save_dir = args.save_dir
self.result_dir = args.result_dir
self.dataset = args.dataset
self.log_dir = args.log_dir
self.gpu_mode = args.gpu_mode
self.model_name = args.gan_type
self.input_size = args.input_size # 输入图像的尺寸
self.z_dim = 62 # 潜在向量维度
self.class_num = 10
self.sample_num = self.class_num ** 2 # 总样本的数量
# load dataset
self.data_loader = dataloader(self.dataset, self.input_size, self.batch_size) # 加载数据集
data = self.data_loader.__iter__().__next__()[0] # 获得第一个批次的数据,data 的形状通常是 (batch_size, channels, height, width)
# networks init
self.G = generator(input_dim=self.z_dim, output_dim=data.shape[1], input_size=self.input_size)
self.D = discriminator(input_dim=data.shape[1], output_dim=1, input_size=self.input_size)
self.G_optimizer = optim.Adam(self.G.parameters(), lr=args.lrG, betas=(args.beta1, args.beta2))
self.D_optimizer = optim.Adam(self.D.parameters(), lr=args.lrD, betas=(args.beta1, args.beta2))
# 查看是否启用了gpu模式
if self.gpu_mode:
self.G.cuda()
self.D.cuda()
self.BCE_loss = nn.BCELoss().cuda() # 将交叉熵损失加载到GPU
self.CE_loss = nn.CrossEntropyLoss().cuda() # 将二元交叉熵损失加载到GPU
else:
self.BCE_loss = nn.BCELoss()
self.CE_loss = nn.CrossEntropyLoss()
print('---------- Networks architecture -------------')
utils.print_network(self.G)
utils.print_network(self.D)
p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









