






1.数据清洗
去掉数据中的噪声(无关数据,重复数据,平滑噪声数据,处理缺失值、异常值)
1.缺失值处理
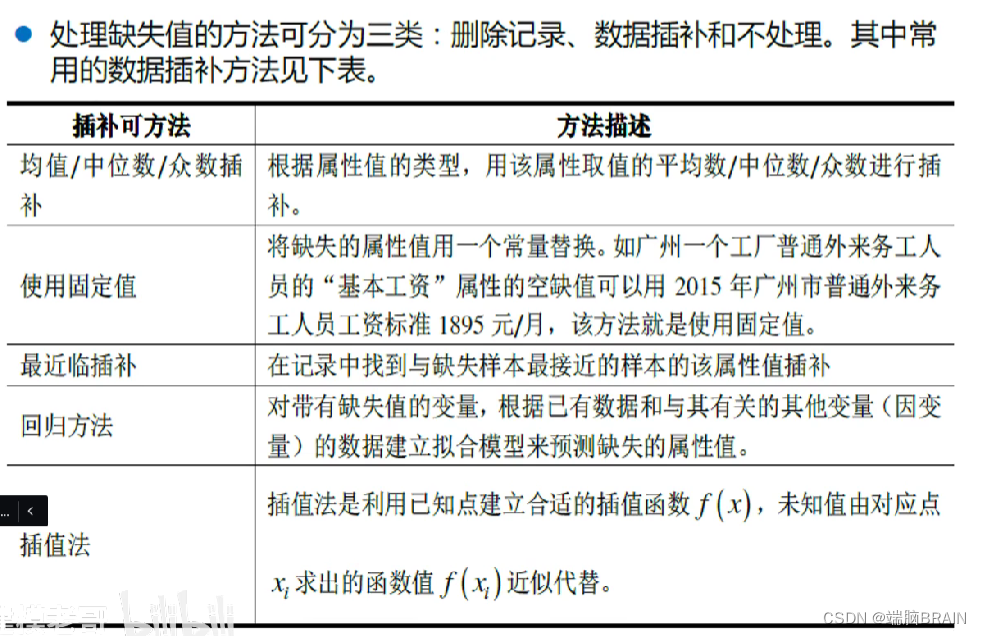
缺失值识别
isnan得到逻辑索引,1表示NaN,用find得到NaN的坐标(c第一列为横坐标,第二列纵坐标)
a=[1 2 3 4 5 NaN; 6 4 NaN 2 1 1;2 3 4 5 6 7];
b=isnan(a);
[c(:,1),c(:,2)]=find(b==1);
最近邻插补
根据“物以类聚,人以群分”这样的规律,一种运用广泛的方法是,借助与缺失样本最邻近(相似度最高)的K个样本的属性值,加权平均后插补。当K=1时,最近邻插补法又被称为热卡填充法。举个简单的例子,如某地某年GDP数据缺失,则可以用当地前后K年GDP值的平均值为其赋值。如果数据是二维或二维以上的,则需要先测算出所有样本两两之间的相似度距离,找到与其“最像”的K个样本,再计算它们的加权平均值。这个方法在图像处理领域也会被运用到。
容易发现,在使用最近邻插补法的时候,我们可能会产生这样两个问题:第一,用什么方法度量相似性,以及需要达到多大的相似性,是我们在应用中需要仔细考虑的问题;第二,当迎来大数据集的时候,时间复杂度也将是我们必须面临的难题。
说到这里,可能有人会问,其中的加权到底是什么意思呢?如果认为随着(时间、空间或样本之间)相邻程度的不同,其他数据对当前缺失值的相对影响程度不同,就可以通过设置权重,对这个取平均的过程进行一定的“人性化”。如在上面GDP的例子中,如果认为缺失年份的上一期数据对其的参考作用最大,下一期在其次,那么可以人为地分别赋权0.6和0.4,以示其相对重要性,再令缺失值在数值上等于”上一期GDP×0.6+下一期GDP×0.4”,就能够提升结果的可解释性和合理性。
 除了缺失数据的一维,把其它维看作点的坐标算出欧氏距离
除了缺失数据的一维,把其它维看作点的坐标算出欧氏距离
回归法
数据较少时不适用

插值法
拉格朗日插值
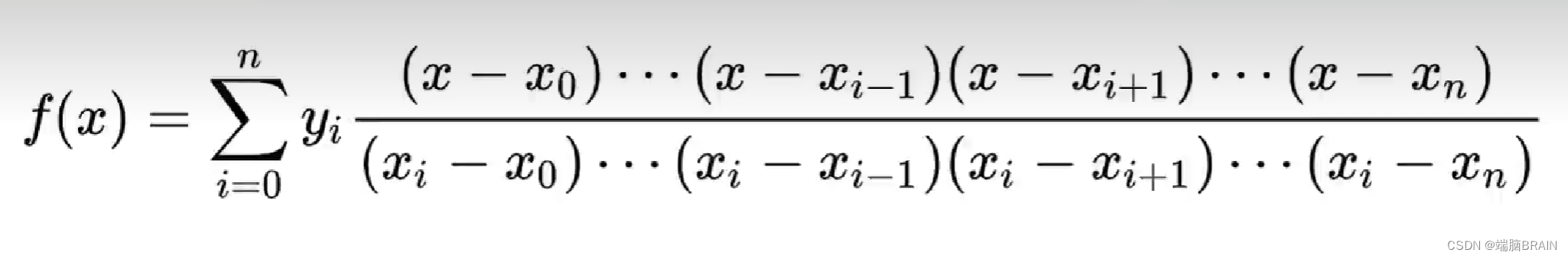
牛顿插值

interp1插值
%{
MATLAB中的插值函数为interp1,其调用格式为: yi= interp1(x,y,xi,'method')
其中x,y为插值点,yi为在被插值点xi处的插值结果;x,y为向量,
'method'表示采用的插值方法,MATLAB提供的插值方法有几种:
'nearest'是最邻近插值, 'linear'线性插值; 'spline'三次样条插值; 'pchip'立方插值.缺省时表示线性插值
注意:所有的插值方法都要求x是单调的,并且xi不能够超过x的范围。
%}
x = 0:2*pi;
y = sin(x);
xx = 0:0.5:2*pi;
% interp1对sin函数进行分段线性插值,调用interp1的时候,默认的是分段线性插值
y1 = interp1(x,y,xx,'linear');
subplot(2,2,1);
plot(x,y,'o',xx,y1,'r')
title('分段线性插值')
% 临近插值
y2 = interp1(x,y,xx,'nearest');
subplot(2,2,2); %subplot(m,n,p) 将当前图形划分为 m×n 网格,并在 p 指定的位置创建坐标轴
plot(x,y,'o',xx,y2,'r');
title('临近插值')
%球面线性插值
y3 = interp1(x,y,xx,'spline');
subplot(2,2,3);
plot(x,y,'o',xx,y3,'r')
title('球面插值')
%三次多项式插值法
y4 = interp1(x,y,xx,'pchip');
subplot(2,2,4);
plot(x,y,'o',xx,y4,'r');
title('三次多项式插值')
2.异常值处理

异常值的发现
1.正态分布图
3z之外异常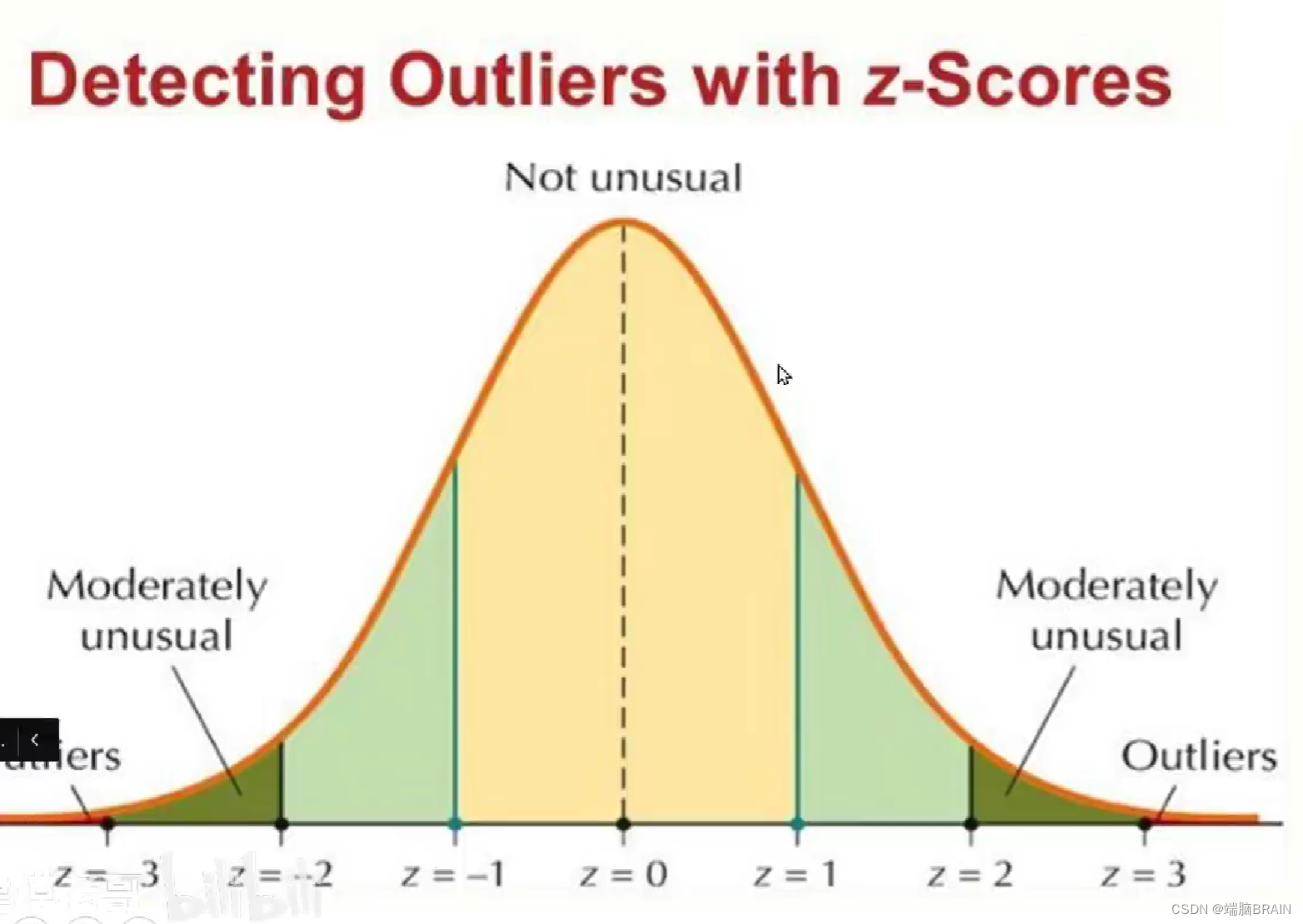
for i=(1:size(a,2))
b=a(:,i); %取出每一列
m_b=mean(b); %求均值
s_b=std(b); %求标准差
c(:,i)=(abs(b-m_b)>3*s_b); %3sigma原则
end
大量数据时3sigma才能有效,少量数据直接看。
2.箱线图
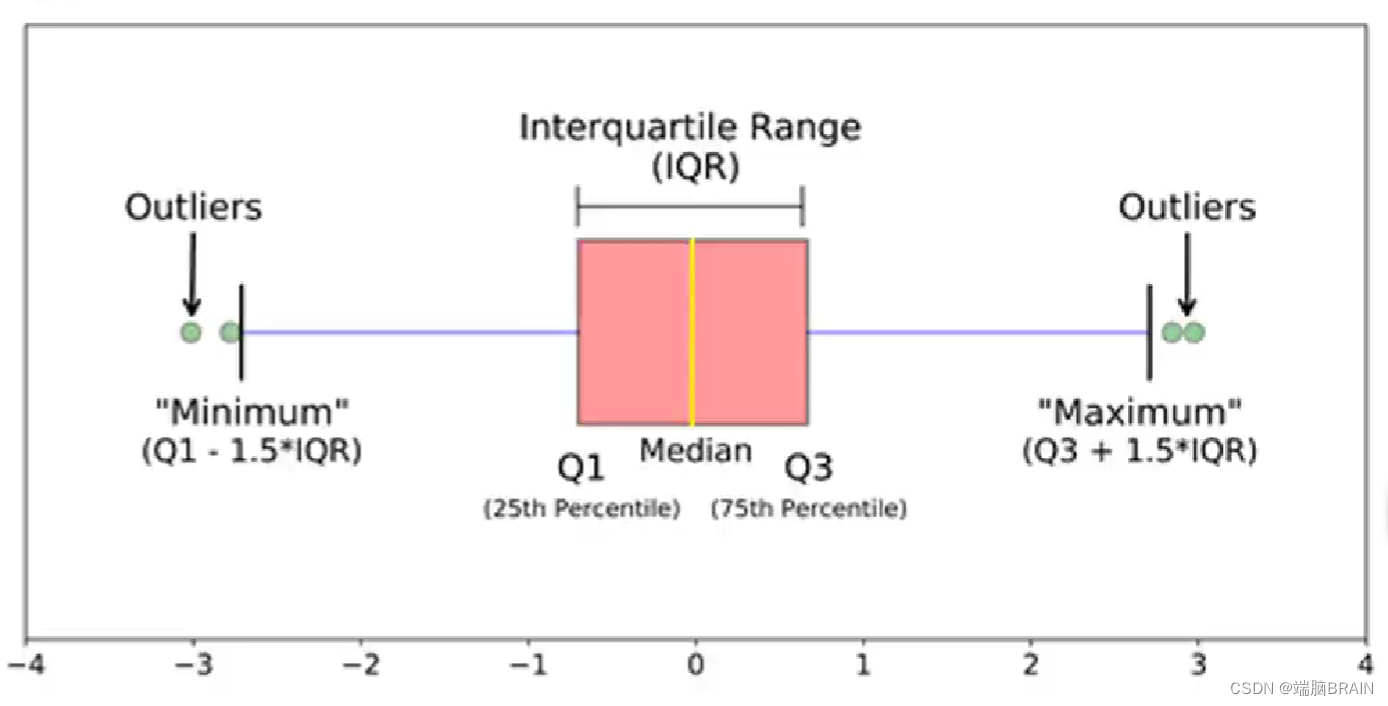
a = randi([0 100], 30, 1); %0~100选30个点
a(16:20,1) = randi([100 200],5,1);
a(21:25,1) = randi([-100 0],5,1);
x = int16(rand(30,1));
x = categorical(x);
boxchart(x,a);
hold on
plot(x,a,'x');%iris四个指标的箱线图
data = readmatrix('iris.csv', 'OutputType', 'string');
data=str2double(data);
data(:,1)=[];
data(:,5)=[];
q=boxchart(data); %不能在原数据t上使用句柄
q.MarkerStyle = '+';
q.MarkerColor = 'r'; %r为紫色,a为蓝色
q.BoxFaceColor = [0.5 0.1 0.9];
q.WhiskerLineColor = [0.2 0.6 0.4];
title('BOX');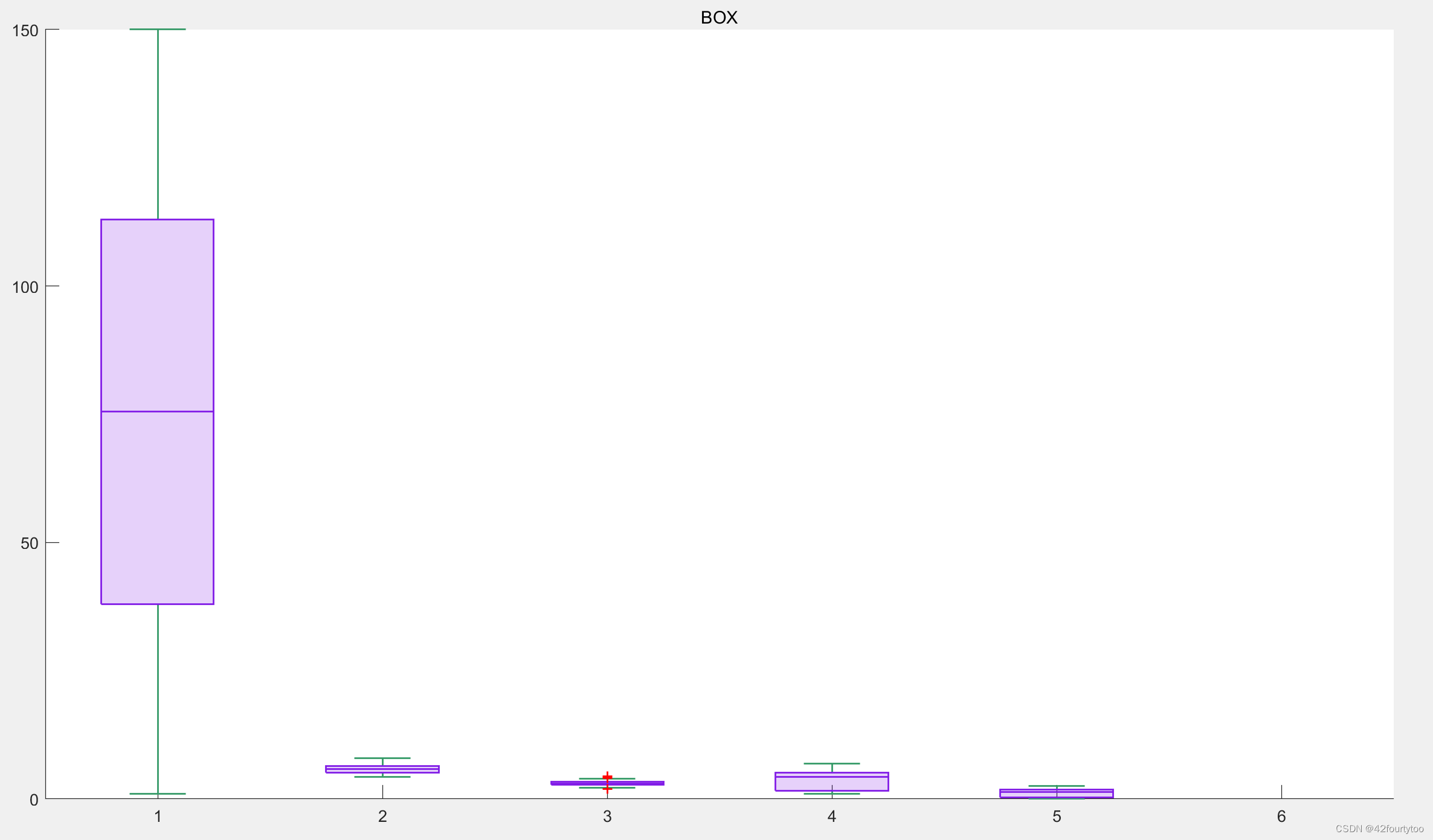
但箱线图仅反映一维的情况,可能检测不出高维离群点: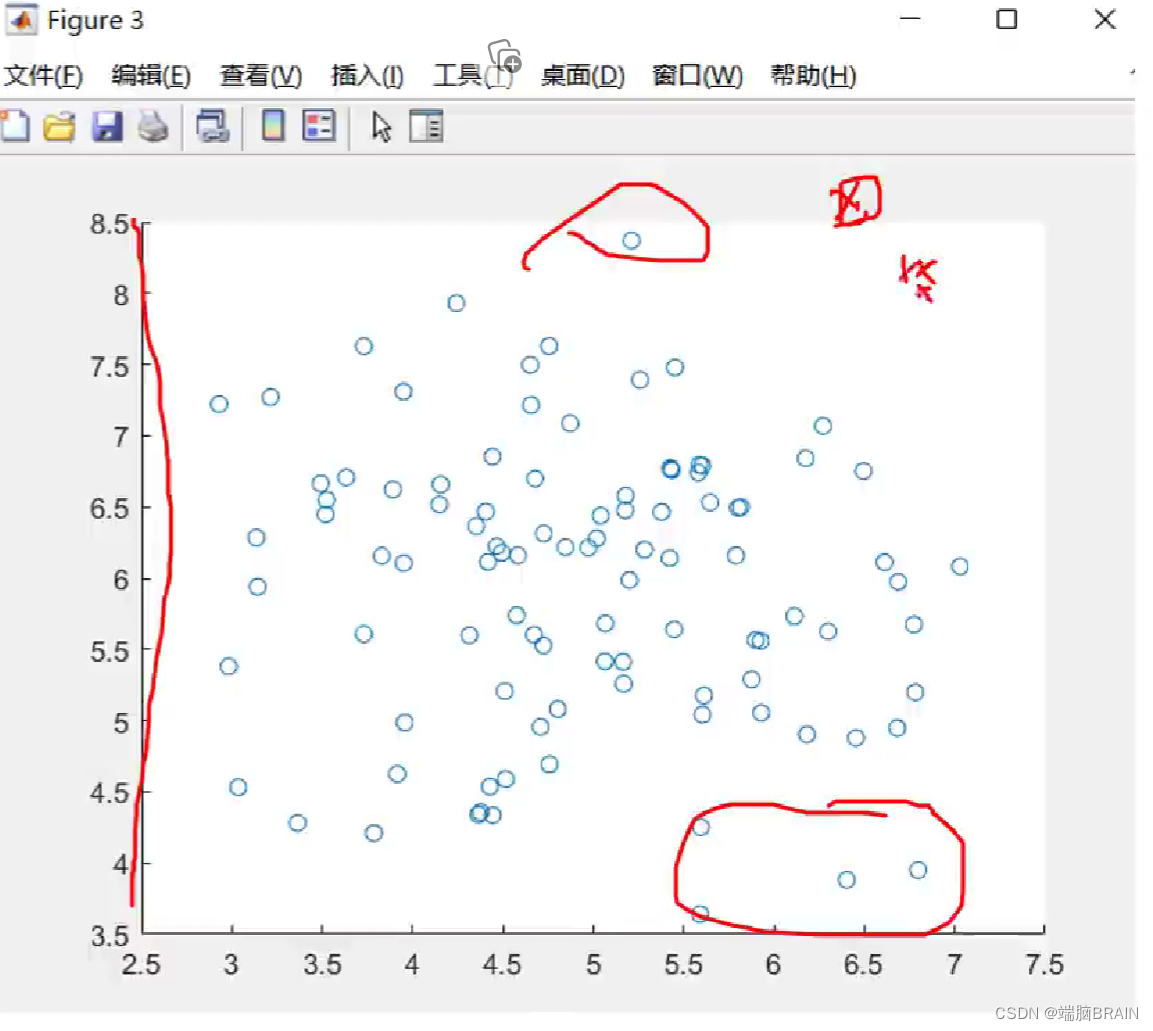 解决方法:
解决方法:
计算欧氏距离,选出大于阈值的数值多于等于p(横加纵)的数据,即为噪声数据。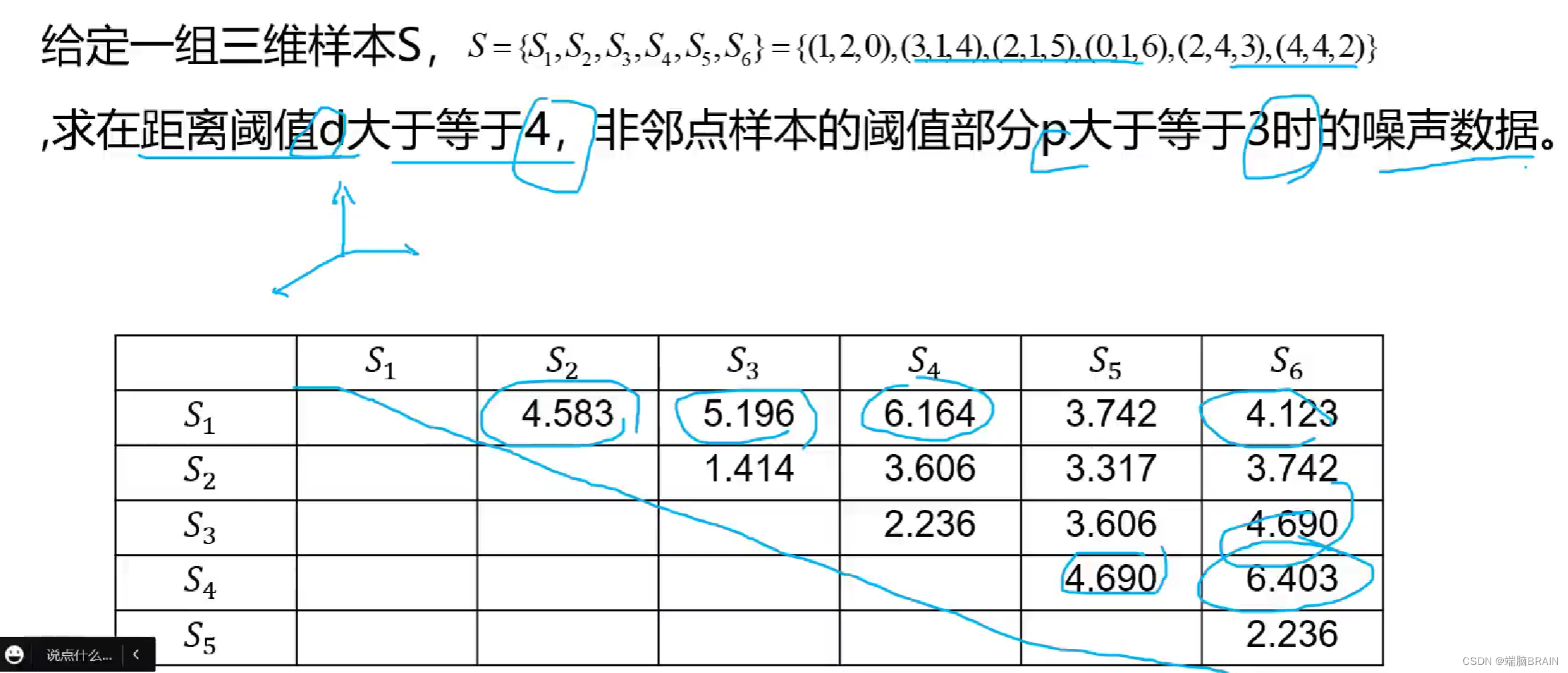
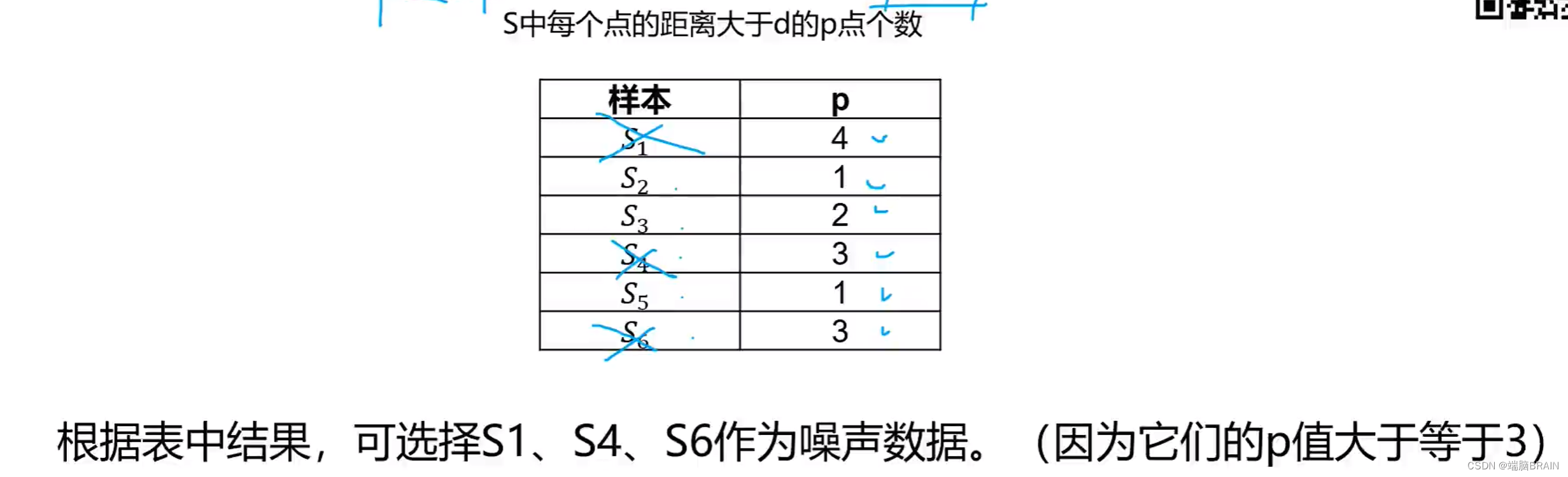
阈值和p值自己选定。
2.数据集成
将多个数据源合并
3.数据归约(消减)
聚集,删除冗余属性,压缩数据
4.数据变换
数据的格式转化,如规范化
1.正态偏态
正态分布是指多数频数集中在中央位置,两端的频数分布大致对称。一个标准的正态分布是u(均值)=0,σ(标准差)=1。
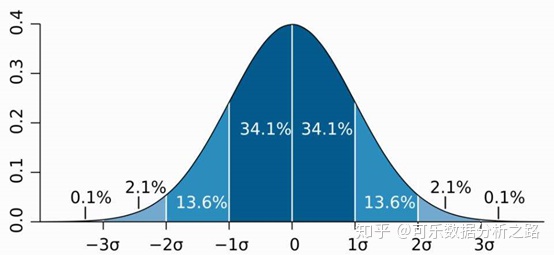
右偏(正偏态),偏度>0,频数分布的高峰向左偏移。
左偏(负偏态),偏度<0,频数分布的高峰向右偏移。
|偏度|>1,呈高度偏态,0.5<|偏度|<1,呈中等偏态。
检测是否为正态分布: Q-Q图_百度百科
2.简单函数变换
log(峰值右偏),对数转换(峰值左偏)(数据必须大于0)
还有:
平方根转换
倒数转换
平方根后取倒数
平方根后再取反正弦
幂转换
3.归一化
消除指标之间量纲和大小的影响

5.特征工程
数据预处理一定要有,特征工程看情况



过滤法
检测各特征的相关性,正负相关性强就可以合二为一,降维。
包装法
每次选择若干特征进行评价,筛选出影响力大的特征,排除影响力小的特征。
主成分分析法
PCA求解iris:
load fisheriris; %导入数据集
X = meas; % n = 150, m = 4
meanX = ones(size(X,1), 1) * mean(X); % 中心化处理
centredX = X - meanX;
C = cov(centredX); % 直接调用cov直接计算协方差矩阵即可
[W, Lambda] = eig(C); % W是特征向量组成的矩阵(4×4),Lambda是特征值组成的对角矩阵
ev = (diag(Lambda))'; % 提取特征值
ev = ev(:, end:-1:1); % eig计算出的特征值是升序的,这里手动倒序(W同理)
W = W(:, end:-1:1);
sum(W.*W, 1) % 可以验证每个特征向量各元素的平方和均为
Wr = W(:, 1:2); % 提取前两个主成分的特征向量
Tr = centredX * Wr; % 新坐标空间的数据点
% 作图
figure;
stairs(cumsum(ev)/sum(ev), 'LineWidth',1.5);
axis([1 4 0 1]);
xlabel('$ k $', 'Interpreter', 'latex');
ylabel('$ f(k)=\frac{\sum _{i=1}^i \lambda_k}{\sum_{i=1}^m \lambda_i} $',...
'Interpreter', 'latex');
hold on;
plot([1 4], [0.95 0.95], '--'); % 从图中可以看出,r为方差贡献率,取r = 2
figure;
scatter(Tr(:,1), Tr(:,2), 130, categorical(species), '.');
colormap(winter);
xlabel('Principal Component 1');
ylabel('Principal Component 2');
[U, Sigma, V] = svd(X); % 可以检验,W和V完全相同(向量的正负号不影响)
Vr = V(:, 1:2); % 提取前两个主成分的特征向量
Tr = X * Vr; % 新坐标空间的数据点
% 画图部分同上
[loadings, scores] = pca(X, 'NumComponents', r);
[Wr, Tr, ev] = pca(X, 'NumComponents',2); % 画图部分
傻瓜攻略(一)——MATLAB主成分分析(PCA)代码及结果分析实例_佟湘玉滴玉的博客-CSDN博客(4条消息) 【主成分分析】PCA降维算法及Matlab代码实现_matlabpca降维_Lil_Yau的博客-CSDN博客
Pearson相关系数:
x=[2 2 3 4 5 6 6 6 7 7;
50 51 52 53 53 54 55 56 56 57 ];
p=corrcoef(x');注意:同一种类数据要按列计算,别忘转置
如果readtable别忘了转成array!
T=readmatrix('iris.csv'); %貌似只有csv能读入
T(:,1)=[]; %删掉文字
T(:,5)=[];
%T=table2array(T); table转array!
P=corr(T); %P=corr(T,'Type','Pearson');
%P=corrcoef(T);














 7870
7870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









