







摘要:
近年来,图像修复取得了重大进展。然而,恢复具有生动纹理和合理结构的损坏图像仍然具有挑战性。由于卷积神经网络 (CNN) 的感受野有限,一些特定方法只能处理常规纹理,同时失去整体结构。另一方面,基于注意力的模型可以更好地学习结构恢复的长程依赖性,但它们受到大图像尺寸推理的大量计算的限制。为了解决这些问题,我们建议利用一个额外的结构恢复器来促进图像的增量修复。所提出的模型在固定的低分辨率草图空间中,通过强大的基于注意力的转换器模型恢复整体图像结构。这样的灰度空间很容易被上采样到更大的比例,以传达正确的结构信息。我们的结构恢复器可以通过零初始化残差添加有效地与其他预训练修复模型集成。此外,利用掩蔽位置编码策略来提高大型不规则掩码的性能。在各种数据集上进行的广泛实验验证了我们的模型与其他竞争对手相比的有效性
代码![]() https://github.com/DQiaole/ZITS_inpainting
https://github.com/DQiaole/ZITS_inpainting
解决问题:
-
有限的接受场:传统的卷积神经网络(CNNs)由于局部归纳先验和卷积操作的狭窄接受场,难以学习语义一致的纹理。即使是扩张卷积,也难以处理大面积损坏区域或高分辨率图像。
-
缺失整体结构:恢复场景中的关键边缘和线条,尤其是纹理较弱的场景时,缺乏对大图像的整体理解是非常困难的。这导致在复杂场景下的结构恢复不充分。
-
计算量大:训练生成对抗网络(GANs)需要较大的图像尺寸,这不仅成本高昂,而且在高分辨率图像上的图像修复性能可能会下降。
-
掩蔽区域无位置信息:传统的图像修复模型在大型不规则掩蔽区域容易重复无意义的伪影,因为没有明确的位置线索来指导修复过程。
论文方法:
- 本文提出了一种名为ZITS(ZeroRA based Incremental Transformer Structure)的渐进式结构增强图像修复模型。该模型利用基于Transformer的结构恢复器逐步修复图像,并使用零初始化残差添加(ZeroRA)技术将辅助结构信息集成到预训练的图像修复模型中。
- ZITS模型包括四个主要组件:Masking Positional Encoding (MPE)、Transformer Structure Restorer (TSR)、Fourier CNN Texture Restoration (FTR)和Structure Feature Encoder (SFE)。MPE用于在掩蔽区域提供位置编码,以改善大尺寸高分辨率图像中掩蔽区域的处理。TSR负责恢复图像的整体结构,而FTR和SFE则分别处理纹理恢复和特征编码。此外,通过实验验证了ZITS模型在多个数据集上的性能,显示其在结构和纹理恢复方面均优于现有最先进的方法。
- 文章还讨论了图像修复中的结构信息的引入方式,指出现有的一些方法依赖于复杂的多阶段或多模型设计,这些设计成本高昂且难以从零开始训练。因此,ZITS采用增量式训练策略,使得模型可以在较少的训练步骤中快速收敛,并且能够有效地将结构信息融入到预训练的图像修复模型中。
方法:
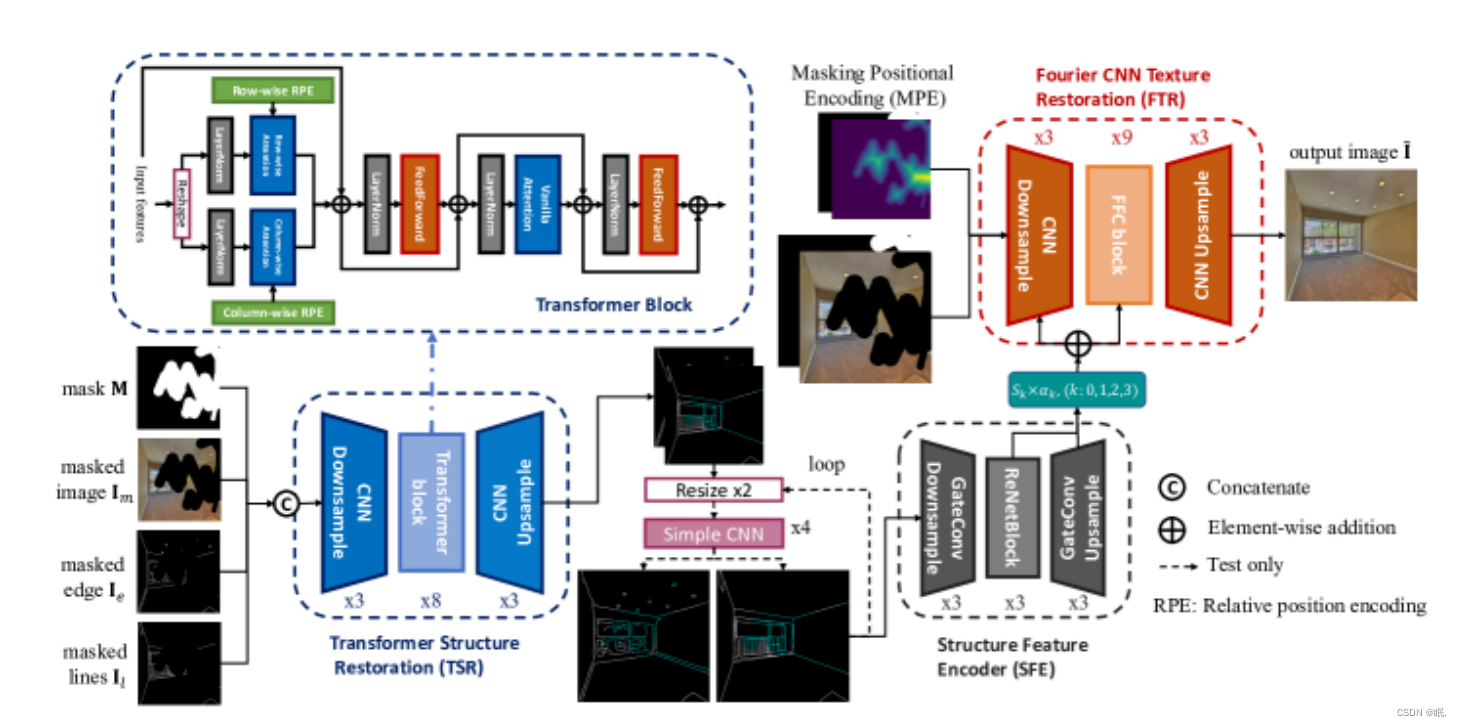 首先,TSR模型用于恢复低分辨率的结构。然后利用简单的基于CNN的上采样器对边图和线图进行上采样。此外,上采样的草图空间由 SFE 模型编码,并通过 ZeroRA 添加到 FTR 中以恢复纹理。左上角显示有关变压器块的详细信息。输入特征分别通过逐行和逐列注意力学习,然后由标准注意力模块编码。
首先,TSR模型用于恢复低分辨率的结构。然后利用简单的基于CNN的上采样器对边图和线图进行上采样。此外,上采样的草图空间由 SFE 模型编码,并通过 ZeroRA 添加到 FTR 中以恢复纹理。左上角显示有关变压器块的详细信息。输入特征分别通过逐行和逐列注意力学习,然后由标准注意力模块编码。
MPE(Masking Positional Encoding)
本文中提出的一种用于图像修复模型中掩蔽区域的编码方法。在处理大型不规则掩蔽区域时,MPE能够改善模型的性能。
MPE的实现过程如下:
-
掩蔽距离和方向的计算:给定一个反转的256×256二值掩蔽图,其中1表示未掩蔽区域,0表示掩蔽区域。使用一个3×3全为1的核来计算每个掩蔽区域内的位置相对于未掩蔽区域的距离(masking distance),然后通过Sinusoidal Positional Encoding (SPE)对距离进行裁剪和映射。
-
掩蔽方向的编码:使用4个不同的二值核来获取掩蔽区域内每个位置的掩蔽方向(masking directions),这些方向指示了从掩蔽位置到未掩蔽位置的最近方向。掩蔽方向由最近的核覆盖决定,并通过学习得到的嵌入参数将它们映射到固定维度的特征空间中。
-
特征融合:在结构特征编码器(SFE)中,通过门控卷积(GCs)有选择地传递有用特征。从SFE的中间层和解码器层中选择4个粗粒度到细粒度的特征图,然后将这些特征传递给FTR以恢复纹理。
什么是反转掩码图:"反转的256×256二值掩蔽图"指的是一个特定的图像,该图像是一个256×256像素的二值图像,其中1代表未被掩蔽的区域,0代表已经被掩蔽的区域。这种掩蔽图通常用于图像修复任务中,特别是在处理大型不规则掩蔽区域时。在本文的背景下,这个掩蔽图用于指导ZITS模型中的结构恢复过程,帮助模型区分哪些区域是重要的结构信息需要恢复,而哪些区域是需要被掩盖或填充的。通过使用这种掩蔽图,模型可以更精确地集中在需要修复的结构上,从而提高修复质量和效率。
TSR(Transformer Structure Restoration)

FTR(Fourier CNN Texture Restoration)
FTR的工作原理主要包括两个分支:一个局部分支使用常规卷积,另一个全局分支在快速傅立叶变换后对特征进行卷积。这两个分支结合起来,可以在图像修复过程中获得更大的感受野和局部不变性。然而,尽管FTR在结构恢复方面表现出色,它仍然无法学习合理的整体结构。因此,本文提出了一系列新的组件来改进FTR,包括Structure Feature Encoder (SFE)等。
SFE(Structure Feature Encoder)
SPE被应用于MPE中,用于生成与掩蔽区域相关的相对位置编码。具体来说,给定一个反转的256×256二值掩蔽图,SPE通过计算掩蔽区域内每个位置相对于未掩蔽区域的距离,并使用正弦函数将这些距离映射到一定范围内,从而生成具有位置信息的编码。这有助于模型在修复过程中更好地理解和利用掩蔽区域周围的结构信息,特别是在处理大型不规则掩蔽区域时。















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









