






目录
前言
当谈到大数据处理时,Hadoop 是一个经常被提及的重要工具。而 MapReduce 则是 Hadoop 的核心组件之一,为大规模数据处理提供了一种简单而有效的编程模型。本文就介绍了 MapReduce 的基础内容。
一、 MapReduce 是什么?
MapReduce 的概念源自于函数式编程的思想,它将数据处理任务分为两个主要阶段:Map 和 Reduce。首先,数据被分割成若干个小块,然后这些小块分别经过 Map 阶段的处理,生成中间结果。接着,这些中间结果被整合、排序、分组,最终经过 Reduce 阶段的处理,得到最终的输出结果。

二、MapReduce的结构
在 Hadoop 中,MapReduce 由一个 Master 节点和多个 Worker 节点组成。Master 负责任务的调度和监控,而 Worker 则负责实际的数据处理。用户只需编写 Map 和 Reduce 函数,以及指定输入数据和输出数据的位置,Hadoop 就会自动管理数据的分发、任务的调度和失败的处理,从而实现分布式的大规模数据处理。
下面具体介绍下各个阶段的作用:
1.Map 阶段的结构:
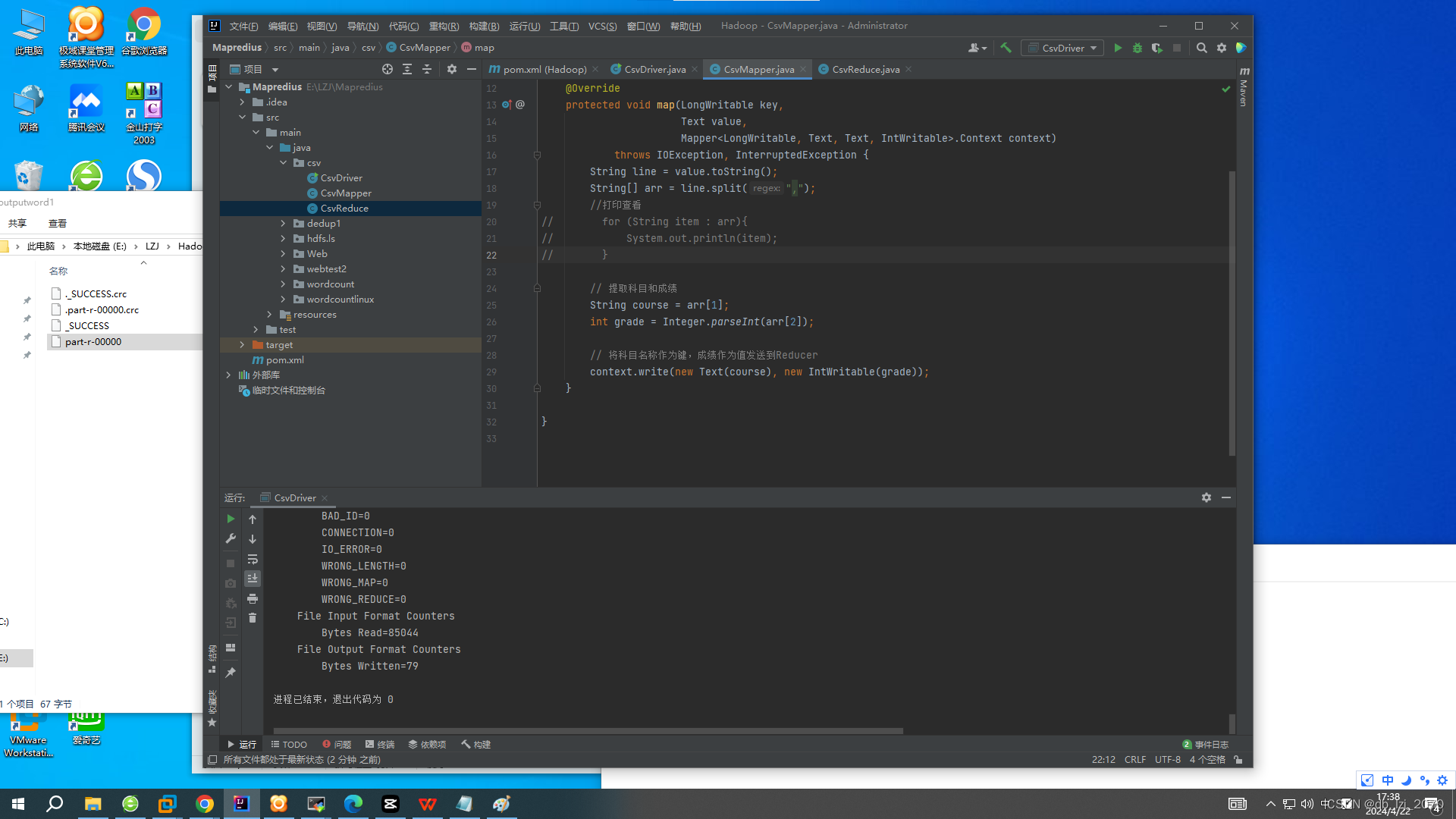
MapReduce 的 Mapper 阶段是整个 MapReduce 任务中的第一个阶段,负责处理输入数据并生成中间键值对作为输出,供 Reducer 阶段进一步处理。
-
输入数据划分(Input Data Splitting):
- 在 Mapper 阶段开始之前,输入数据将会被划分成若干个输入分片(input splits)。每个输入分片对应一个 Mapper 实例处理。这个过程是由 Hadoop 框架自动完成的,它根据输入数据的大小和 HDFS 存储的块大小等因素来进行划分。
-
Mapper 初始化(Mapper Initialization):
- 在 Mapper 阶段开始之前,每个 Mapper 实例会被初始化。在初始化过程中,可以执行一些准备工作,比如设置初始状态或加载必要的资源。
-
数据映射(Data Mapping):
- 对于每个输入分片,Mapper 实例会被调用一次。在这个阶段,Mapper 将对输入数据进行处理,并生成中间键值对作为输出。这个过程通常包括数据解析、数据清洗、数据转换等操作,根据具体需求来生成键值对。
-
中间结果输出(Intermediate Output):
- 在 Mapper 阶段处理完所有输入数据后,生成的中间键值对将会被输出到临时的中间结果文件。这些中间结果文件将会被分发给相应的 Reducer 实例进行处理。
-
Mapper 结束(Mapper Termination):
- 当 Mapper 完成对所有输入数据的处理后,Mapper 实例将进入结束阶段。在这个阶段,可以进行一些清理工作,释放资源或执行其他必要的操作。
import java.io.IOException;
import java.util.StringTokenizer;
// Mapper 类
public class MyMapper extends Mapper<Object, Text, Text, IntWritable>{
// Map 函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// key: 输入数据的键
// value: 输入数据的值
// context: MapReduce 上下文
// 将输入数据转换为字符串
String line = value.toString();
// 使用空格分割字符串
StringTokenizer tokenizer = new StringTokenizer(line);
// 遍历分割后的单词
while (tokenizer.hasMoreTokens()) {
// 获取单词
String word = tokenizer.nextToken();
// 发射键值对 (键为单词,值为1)
context.write(new Text(word), new IntWritable(1));
}
}
}
这是一个简单的 Map 阶段示例代码,其中 MyMapper 类继承自 Hadoop 提供的 Mapper 类。在 map 方法中,输入数据被解析成行,并使用 StringTokenizer 对每一行进行单词划分。然后,对于每个单词,都会生成一个中间键值对,键为单词,值为1。这些中间键值对会被 MapReduce 框架收集并传递给 Reduce 阶段进行进一步处理。
在实际应用中,Mapper 函数的具体实现会根据任务的需求而有所不同。
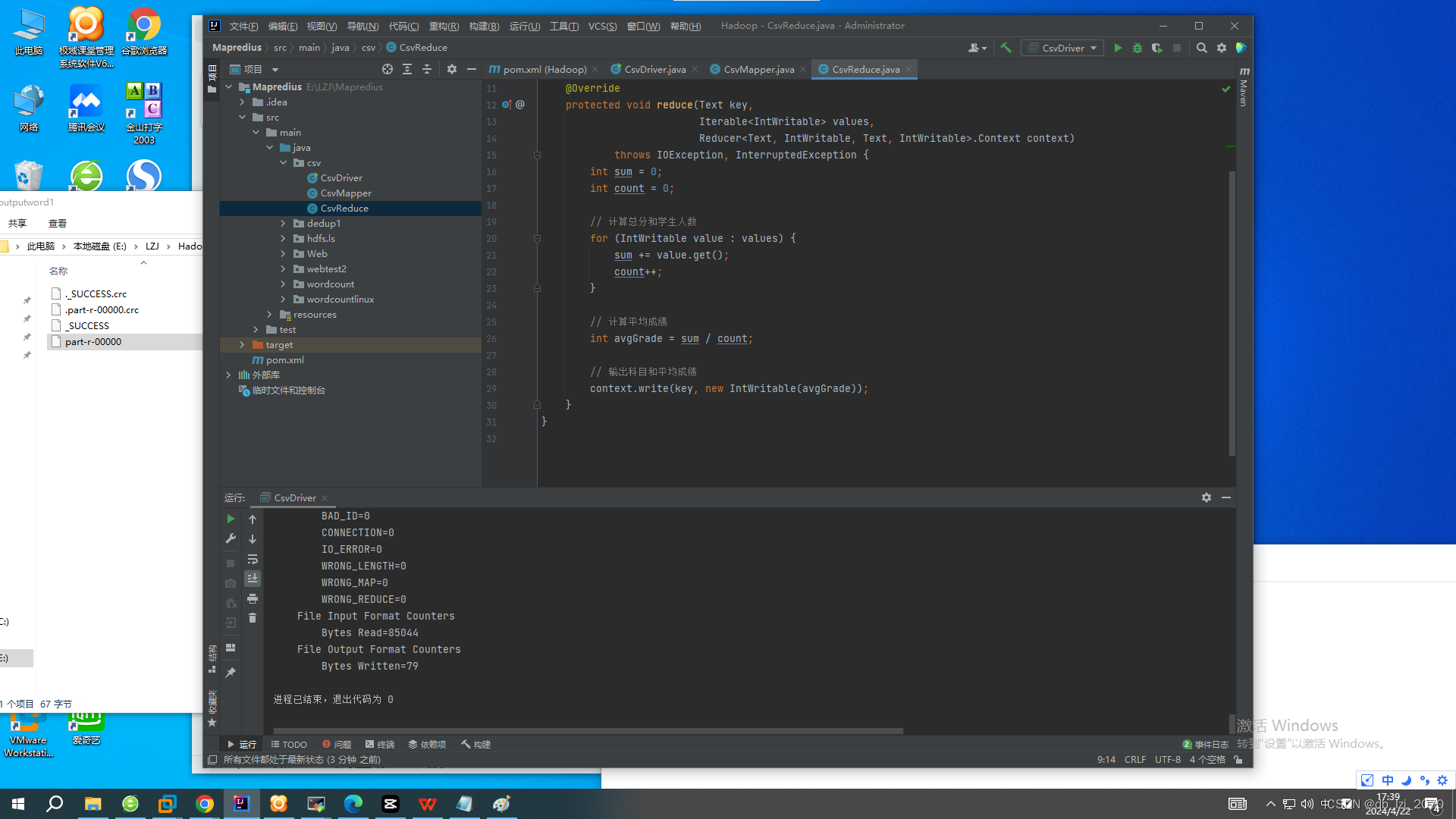
2.Reduce 阶段的结构:
MapReduce 的 Reducer 阶段是 MapReduce 任务中的一个重要部分,负责对 Mapper 阶段输出的中间键值对进行汇总和处理,生成最终的输出结果。
-
数据分组(Data Shuffling):
- 在 Reducer 阶段之前,Hadoop 框架会将 Mapper 阶段输出的键值对按照键进行分组。这个过程被称为数据分组(Data Shuffling)。相同键的所有值将被发送到同一个 Reducer 实例进行处理。
-
Reducer 初始化(Reducer Initialization):
- 在 Reducer 阶段开始之前,每个 Reducer 实例会被初始化。在初始化过程中,可以执行一些准备工作,比如设置初始状态或加载必要的资源。
-
迭代处理(Iterative Processing):
- 对于每个分组的键值对,Reducer 实例会被调用一次。在这个阶段,Reducer 将对每个键值对执行相应的处理逻辑。这通常包括聚合、计算、过滤等操作,根据具体需求来生成最终的输出结果。
-
Reducer 输出(Reducer Output):
- 在处理完所有键值对后,Reducer 实例将生成最终的输出。输出通常是键值对的集合,其中键代表某种结果或分类,而值则代表相应的计数、统计量或其他计算结果。
-
Reducer 结束(Reducer Termination):
- 当 Reducer 完成所有键值对的处理后,Reducer 实例将进入结束阶段。在这个阶段,可以进行一些清理工作,释放资源或执行其他必要的操作。
代码如下(示例):
import java.io.IOException;
// Reducer 类
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// Reduce 函数
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// key: 分组键
// values: 分组内的值列表
// context: MapReduce 上下文
int sum = 0;
// 对分组内的值进行求和
for (IntWritable value : values) {
sum += value.get();
}
// 发射最终结果 (键为原始键,值为求和结果)
context.write(key, new IntWritable(sum));
}
}
这是一个简单的 Reduce 阶段示例代码,其中 MyReducer 类继承自 Hadoop 提供的 Reducer 类。在 reduce 方法中,对于每个分组的键值对集合,都会将其值进行求和操作,并将最终的结果输出为键值对,其中键为原始键,值为求和结果。这些最终的输出结果会作为整个 MapReduce 任务的最终输出。
在实际应用中,Reducer 函数的具体实现会根据任务的需求而有所不同,可以执行各种不同的聚合操作,如求和、计数、平均值等。
3.Driver 阶段的结构:
MapReduce 的 Driver 阶段是整个 MapReduce 任务中的控制中心,负责配置和管理整个任务的执行流程。它通常由一个独立的 Java 类来实现,其中包括了作业配置、作业实例的创建以及作业的提交等步骤。
-
设置作业配置(Job Configuration):
- 在 Driver 阶段,首先需要设置 MapReduce 作业的配置信息,包括作业名称、输入路径、输出路径、Mapper 类、Reducer 类等。这些配置信息将指导 Hadoop 框架如何执行任务。
-
创建作业实例(Job Instance Creation):
- 使用配置信息创建一个 MapReduce 作业实例。这个作业实例是整个 MapReduce 任务的核心对象,负责协调整个任务的执行流程。
-
配置 Mapper 和 Reducer(Mapper and Reducer Configuration):
- 在作业实例中,需要设置 Mapper 类和 Reducer 类,以及它们的输入和输出类型。这些信息告诉 Hadoop 如何对输入数据进行处理和计算。
-
设置输入和输出路径(Setting Input and Output Paths):
- 在作业实例中,需要指定输入数据的路径和输出结果的路径。这些路径可以是 Hadoop 分布式文件系统(HDFS)中的路径,也可以是其他支持的文件系统中的路径。
-
提交作业(Job Submission):
- 设置完所有配置后,需要将作业提交给 Hadoop 集群执行。作业提交后,Hadoop 框架会根据配置信息启动相应的 Mapper 和 Reducer 任务,并处理输入数据,生成输出结果。
-
等待作业完成(Waiting for Job Completion):
- 提交作业后,驱动程序会等待作业完成。作业完成后,驱动程序可以获取作业的执行状态,并根据需要执行后续操作。
代码如下(示例):
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class MyDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, "My MapReduce Job");
// 设置 Mapper 类
job.setMapperClass(MyMapper.class);
// 设置 Reducer 类
job.setReducerClass(MyReducer.class);
// 设置输出键值对类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入路径
Path inputPath = new Path(args[0]);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, inputPath);
// 设置输出路径
Path outputPath = new Path(args[1]);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, outputPath);
// 提交作业并等待完成
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
在上述示例代码中,MyDriver 类是整个 MapReduce 任务的入口点。在 main 方法中,首先创建了一个配置对象 Configuration,然后通过 Job.getInstance() 方法创建了一个作业实例 Job。接着设置了 Mapper 类和 Reducer 类,以及输出键值对类型。然后设置输入路径和输出路径,并提交作业等待完成。
请确保在编译和运行代码之前配置好 Hadoop 环境,并将编译后的 JAR 文件提交给 Hadoop 集群执行。
三.下面给出一个关于词频统计的相关代码供参考
非关键部分已省略方便查看:
Reduce:
Maper:
Driver:
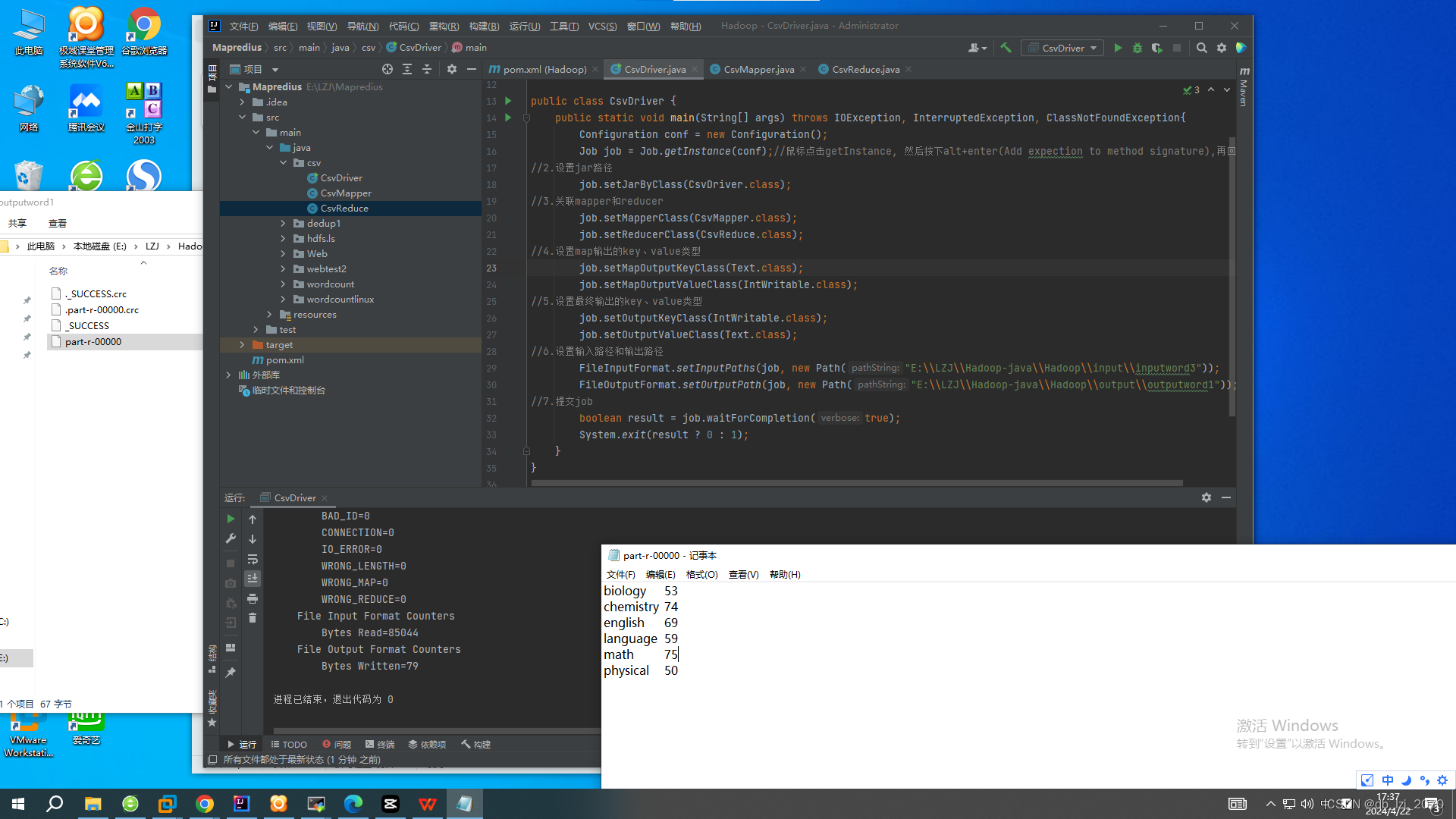
最后查看输出可以在Driver设置的ouput输出路径里的part-r-00000文件中找到词频统计的结果。
注意:如果第二次运行程序未改变输出路径,需要将旧输出文件删除才能正常运行程序。
总结
在 Hadoop 中,MapReduce 由一个 Master 节点和多个 Worker 节点组成。Master 负责任务的调度和监控,而 Worker 则负责实际的数据处理。用户只需编写 Map 和 Reduce 函数,以及指定输入数据和输出数据的位置,Hadoop 就会自动管理数据的分发、任务的调度和失败的处理,从而实现分布式的大规模数据处理。
对于初学者来说,理解 MapReduce 的关键在于掌握其基本原理和工作流程。首先,需要了解 Map 阶段的作用是将输入数据映射为中间键值对,并对每个键值对进行处理;而 Reduce 阶段则负责将相同键的值聚合在一起,并进行最终的处理。其次,需要明白 MapReduce 的并行化处理方式,即将数据分割成多个小块,并通过网络传输在多个节点上并行处理,从而提高处理效率。
总的来说,MapReduce 是一种简单而强大的大数据处理框架,通过将任务分解为 Map 和 Reduce 两个阶段,并利用分布式计算的能力,实现了高效的数据处理和分析。对于需要处理海量数据的应用场景,MapReduce 是一个不可或缺的工具。















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









