






以下文章转载自笔者自己在知乎上发布的文章。
受一位前辈提点,尝试在知乎记录自己的学习,既在写中检验自己的理解,也可以接受广大同仁的批评。
第一次使用知乎写文章尚不习惯,文章结构与排版问题还请见谅。
这学期初刚开始学习机器学习,只接触了一些经典模型的理论,而且至今也还未将经典模型的代码进行复现。原本寄希望于通过kaggle比赛来锻炼实践能力,奈何会的东西太少,下载大佬模型做baseline竟不知道从何处去改动,所以打算以李沐大神的《动手学深度学习》来夯实基础,顺便加强代码能力的训练。
笔者不会写关于数学基础的笔记,主要还是以代码实现以及对代码的解释为主。原因一方面在于笔者认为自己的数学基础还不够,甚至连概率论都还未学过。另一方面笔者对于latex还不甚熟悉,目前就偷个懒了。
言归正传,笔者大概会按照课本顺序写记录,第一次就从数据预处理开始。
读取数据集
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')这里人工创建了一个数据集并存放在`../data/house_tiny.csv`中,关于第一行代码其实我不是很懂原理,所以问了一下GPT,以下是它的回答:
-
os.makedirs: 这是一个在操作系统中创建目录的函数。它会创建递归目录,即如果目录的上层目录不存在,也会一并创建。如果目录已经存在,它会忽略。
-
os.path.join('..', 'data'): 这个函数用于将路径的各个部分连接起来,形成一个完整的路径。在这里,它将 '..' 和 'data' 连接在一起,表示在当前目录的上一级目录下创建一个名为 'data' 的目录。
-
exist_ok=True: 这是 os.makedirs 函数的一个参数。如果设置为 True,当目录已经存在时不会引发错误,而是忽略。如果设置为 False 或省略,当目录已经存在时会引发 FileExistsError。
综合起来,这段代码的含义是在当前工作目录的上一级目录中创建一个名为 'data' 的目录。如果该目录已经存在,就不进行任何操作;如果该目录不存在,就创建它。这通常用于确保在运行代码时所需的目录结构存在,比如存储数据文件的目录。
代码块的最后四行写入了四条数据,按位置分别对应每列。其中NA表示空值。'\n'为换行符,这样可以每行写入一段数据,方便(人?)阅读。
现在简单打印一下数据观察一下。
import pandas as pd
data = pd.read_csv(data_file)
print(data)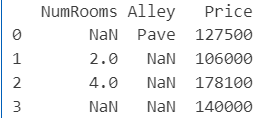
处理缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)iloc,即 index location,第一个位置表示对行操作,第二个位置表示对列操作。这里表示把数据中前两列所有数据放入inputs,将第三列放入outputs。fillna 即fill NaN,这里用每一列的均值来代替缺失值。

现在对Alley列的类别值和空值处理。由于是举的房价的例子,所以这里有类别值Pave。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)这里用到了get_dummies函数,仍然是让GPT来解释:
这段代码使用了 Pandas 库中的 get_dummies 函数,用于进行独热编码(One-Hot Encoding)。
get_dummies 函数:
-
get_dummies 是 Pandas 中的一个函数,用于将分类变量转换为独热编码(dummy variables)或指示变量。
-
独热编码是一种用于处理分类变量的方法,将一个包含 n 个不同取值的分类变量转换为一个 n 列的二进制矩阵,其中每一列代表一个分类变量的取值。如果原始数据中包含某个取值,则对应列的值为 1,否则为 0。
inputs 是 DataFrame:
-
inputs 是一个 DataFrame 对象,通过 pd.get_dummies(inputs, dummy_na=True) 对其进行处理。
-
dummy_na=True 参数:
-
dummy_na 是 get_dummies 函数的一个参数,用于指定是否为原始数据中的缺失值创建一个额外的列。当设置为 True 时,如果原始数据中存在缺失值,会为缺失值创建一个对应的列,并在该列中标记缺失值的位置。默认情况下,dummy_na 是 False,不会创建缺失值的列。
所以,pd.get_dummies(inputs, dummy_na=True) 的作用是将 inputs 中的分类变量进行独热编码,并且如果原始数据中包含缺失值,会为缺失值创建一个额外的列。这通常用于在机器学习任务中处理分类变量,以便能够在模型中使用这些信息。
所以代码的输出如下:

转换为张量格式
关于张量,笔者的理解就是多维数组。(胡乱猜测觉得可能是因为长得很像矩阵的张量积,所以叫这种名字?)反正用就完了。
import torch
X = torch.tensor(inputs.to_numpy(dtype=float))
y = torch.tensor(outputs.to_numpy(dtype=float))
X, y
这里就是把数据用张量存起来,顺便把数值以浮点数来储存。暂时不知道这样处理的好处,等以后学到再说吧。
练习
1. 删除缺失值最多的列。 2. 将预处理后的数据集转换为张量格式。
1.
miss_value_percentage = (data.isnull().mean() * 100).round(2)
data_1=data.drop(columns=[miss_value_percentage.idxmax()])
data_1这里miss_value_percentage为一个series,可以理解为一行数据,其中每一列都是按原来列的顺序对应原来的每一个列名。而每一列的值都是data中每一列缺失值的百分比。第二行代码返回miss_value_percentage中最大值对应的列名,用以把那一列删除。虽然没有按题意来做,但是起到练习效果就好。
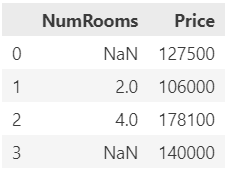
2.
data2tensor = torch.tensor(data_1.to_numpy(dtype=float))
data2tensor
以上就是所有内容,如有错漏之处还请不吝赐教。















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









