






目录
引言
作为一个提供小说资源的网站,起点网对爬虫行为十分敏感,由此起点网采用了很多反爬手段;其中就包括阅读页面不响应鼠标右键、限制开发者工具的使用、加密付费资源文本;
下面以获取某章(已订阅)资源到本地为例提供应对上述反爬措施的思路
使用开发者工具进行分析
首先我们可以在点击章节后立刻鼠标右键-检查呼出开发者工具或刷新页面后立刻右键-检查来应对响应屏蔽
打开开发者工具后我们发现工具处于“暂停调试”状态且无法使用完整功能,此时通过依次点击右上角“停用断点”-“继续执行脚本”后可解除暂停调试状态,恢复开发者工具正常功能的使用
之后通过审查元素发现小说中的文章在html源码中呈现繁体乱码,通过常规爬虫无法获得所需的信息,判断页面的文字经过某js文件对加密资源解密后产生
通过抓包分析可知小说内容在网站返回的一个数字命名的文档中,查看文档响应代码中的一串json数据可以获得密文以及其它后面会用到的参数(在网络页筛选“content”可以定位到该json数据)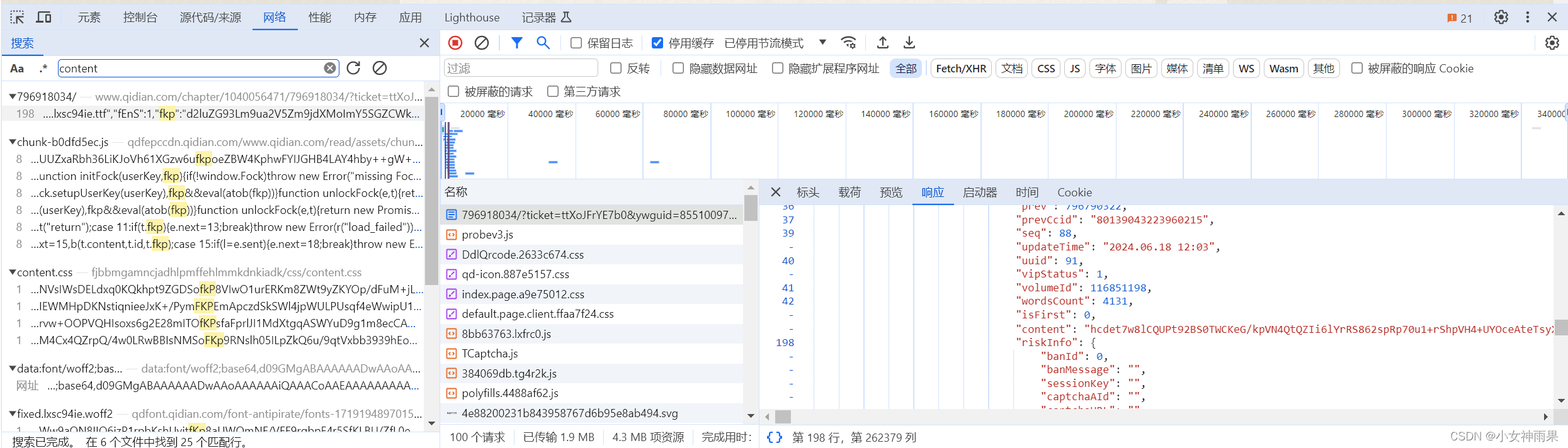
对其它每个js文件的内容特征进行分析可以发现一个包含许多处理文字内容函数的文件,其部分突出特征如下
var Y = []
, G = "function" == typeof atob ? atob : function(A) {
var r, e, n, t, o, i, f = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=", a = "", u = 0;
A = A.replace(/[^A-Za-z0-9\+\/\=]/g, "");
do {
r = Ju(f).call(f, A.charAt(u++)) << 2 | (t = Ju(f).call(f, A.charAt(u++))) >> 4,
e = (15 & t) << 4 | (o = Ju(f).call(f, A.charAt(u++))) >> 2,
n = (3 & o) << 6 | (i = Ju(f).call(f, A.charAt(u++))),
a += String.fromCharCode(r),
64 !== o && (a += String.fromCharCode(e)),
64 !== i && (a += String.fromCharCode(n))
} while (u < A.length);
return a
}解密js文件(大概一万多行这里不做展示,在本地ide操作时可能会导致内存占用过大,电脑卡顿)
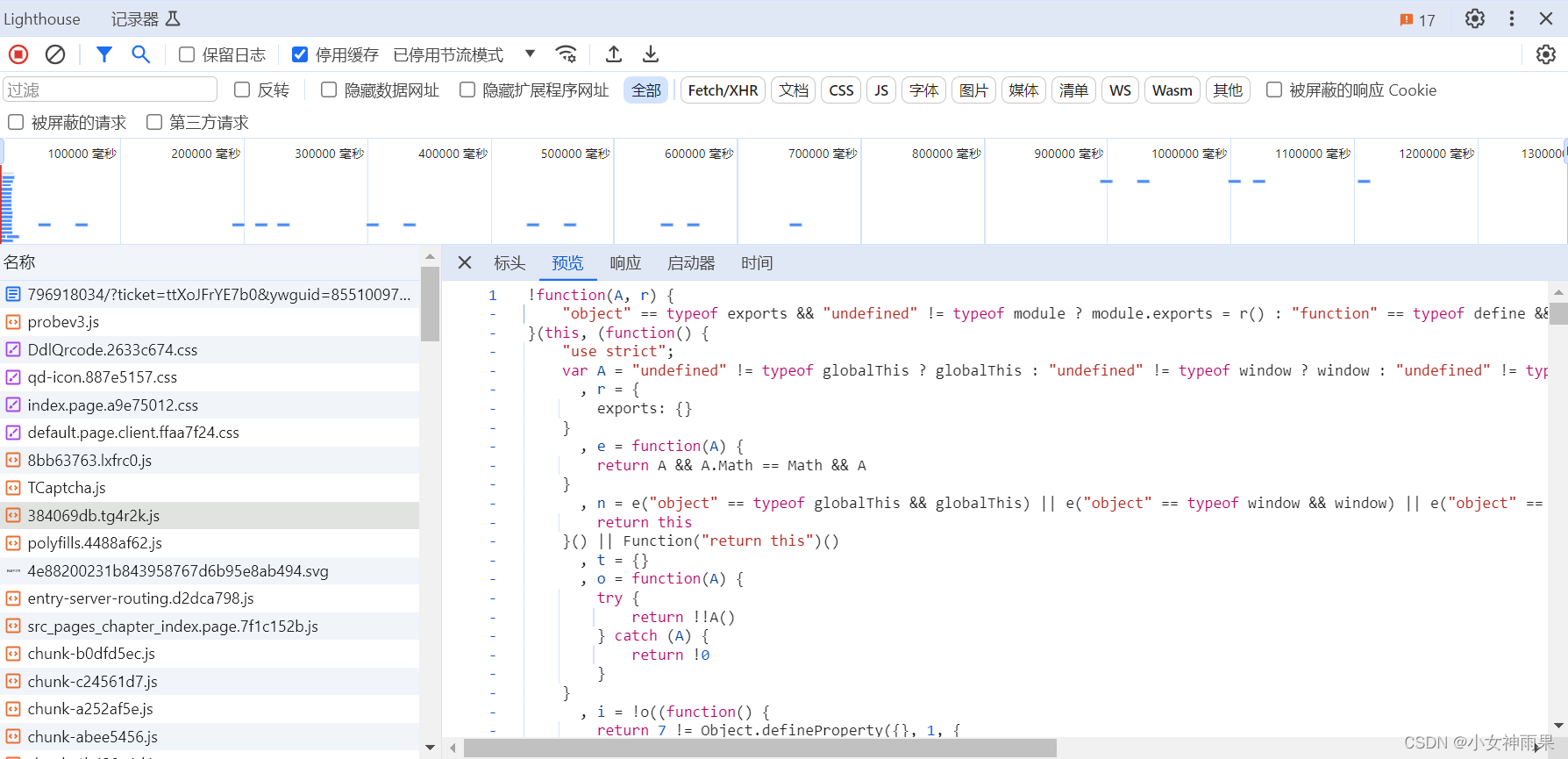
通过设置断点进行分析可知 在其它js文件中有函数进行解密相关的初始化/准备操作,函数中A需要5个参数 密文、图书编号、cES、fkp、fEnS
function initFock(userKey, fkp) {
if (!window.Fock)
throw new Error("missing Fock");
window.Fock.initialize(),
window.Fock.setupUserKey(userKey),
fkp && eval(atob(fkp))
}
function unlockFock(e, t) {
return new Promise((function(n, o) {
try {
var r;
null === (r = window.Fock) || void 0 === r || r.unlock(e, t, (function(e, t) {
0 === e ? n(t) : o(new Error("F:e:u: ".concat(e)))
}
))
} catch (i) {
o(i)
}
}
))
}通过js逆向调用解密函数处理密文
得到了几个要素(解密函数、参数、解密原理)以后就可以在本地进行解密了,首先配置与小说网相同的环境
window = global;
null_fun = function(){console.log(arguments);}
window.outerHeight = 1000
window.innerHeight = 100
globalThis = window
self = window
window.location = {}
location.protocol = "https:"
location.hostname = "vipreader.qidian.com"
setTimeout = null_fun
setInterval = null_fun
document = {createElement: null_fun, documentElement: {}, createEvent: null_fun, currentScript: {src: "https://qdfepccdn.qidian.com/www.qidian.com/fock/116594983210.js"}, domain: 'qidian.com'}
navigator = {userAgent: ''}//填标头
performance = {}
performance.navigation = {type: 1}之后创建一个接口函数sdk,把解密函数嵌套在接口函数中
function sdk(enContent, cuChapterId, cES, fkp, fEnS){
window.enContent = enContent
window.cuChapterId = cuChapterId
window.cES = cES
window.fkp = fkp
window.fEnS = fEnS
//解密函数
//函数结束
return window.content//返回解密内容
}最后调用根据环境修改的初始化函数和sdk函数即可完成解密
function initFock(){
Fock.initialize();
var fuid = "3421355804";
Fock.setupUserKey(fuid);
eval(atob(window.fkp))
window.fkp = undefined,
isFockInit = !0,
fockUnlock()
}
function fockUnlock(){
Fock.unlock(window.enContent, window.cuChapterId)
}
initFock()
console.log(sdk(content,chapterId,ces,fkp,fens))解密后替换乱码的html源码

之后便可在爬虫代码中调用js代码,再用beautifulsoup进行内容解析、提取文章,模拟请求时需要在标头中加上cookie和user-agent(每次访问从设置的user-agent池中随机选择),遍历每个文章链接后time.sieep(1)以防被识别为爬虫 。
总结
起点网对付费资源采取动态加载的方式,非订阅用户无法靠伪装标头等手段从服务器请求到资源,但订阅用户可以利用找到的解密算法把文章获取到本地,网站的解密算法可能出现迭代,本文仅提供相关思路,更多具体做法可根据js逆向知识和实际抓包分析得出。


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









