






史上最强开源AI大模型——Meta的LLaMa3一经发布,各项指标全面逼近GPT-4。它提供了8B和70B两个版本,8B版本最低仅需4G显存即可运行,可以说是迄今为止能在本地运行的最强LLM。
虽然LLaMa3对中文支持不算好,但HuggingFace上很快出现了各种针对中文的微调模型,本文将从零开始介绍如何在本地运行发布在HuggingFace上的各种LLaMa3大模型。
准备环境
本文的演示环境是Mac M1 16G内存,自备科学上网工具,使用开源Ollama运行大模型,使用Open WebUI作为前端访问界面,通过浏览器访问,体验十分接近GPT:
安装软件
首先安装Ollama,它可以让我们非常方便地运行各种LLM。从Ollama官网下载,运行,点击安装Ollama命令行,然后在命令行测试Ollama是否已正常运行:
$ ollama -v
ollama version is 0.1.32
下载模型
Ollama可以直接下载内置的几种模型,但选择有限。我们更希望从HuggingFace下载以便方便地评估各种模型,所以,这里我们并不从Ollama直接下载,而是从HuggingFace下载。
在HuggingFace搜索llama3,设置Languages为Chinese,可以看到若干基于LLaMa3的中文模型:
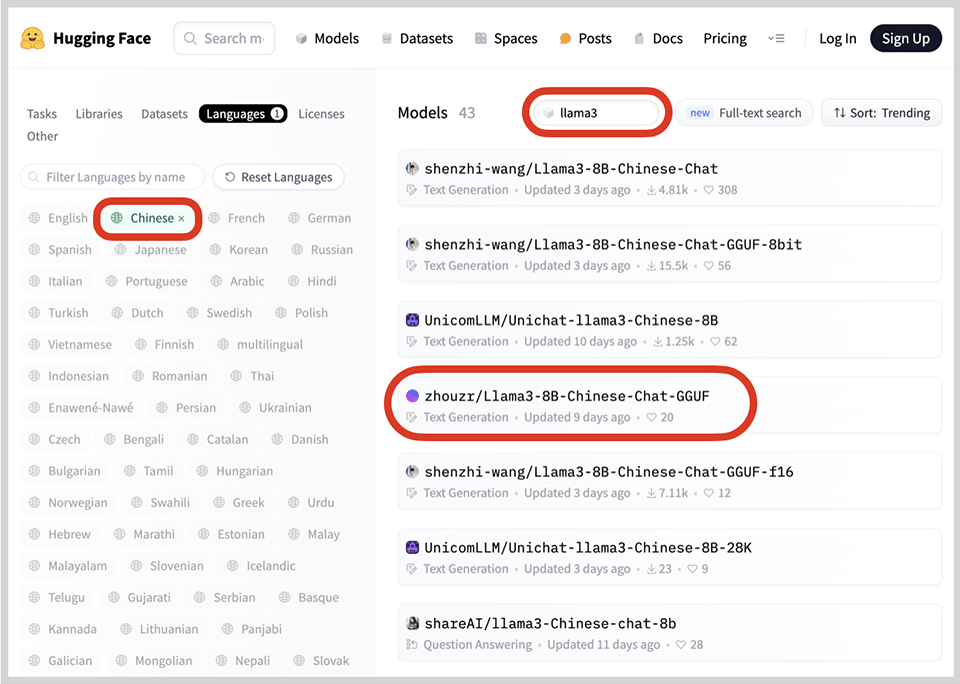
我们选择一个GGUF格式的模型,GGUF格式是llama.cpp团队搞的一种模型存储格式,一个模型就是一个文件,方便下载:
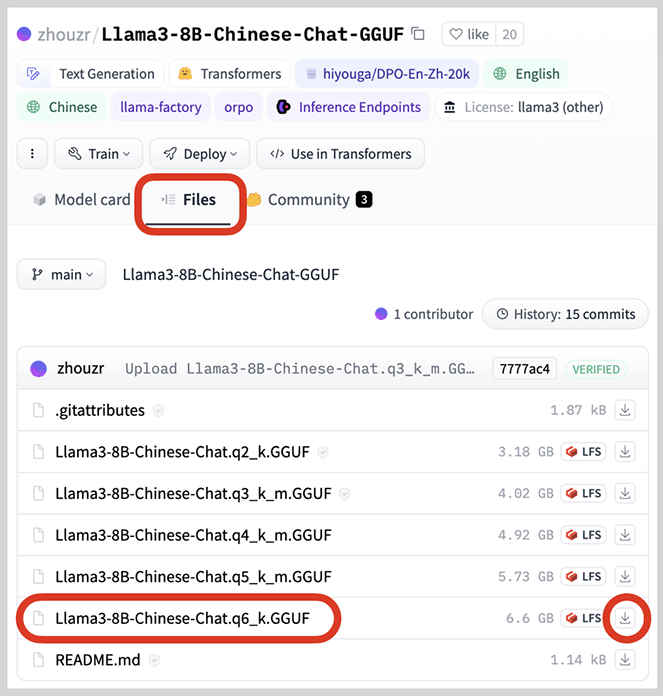
点击Files,可以看到若干GGUF文件,其中,q越大说明模型质量越高,同时文件也更大,我们选择q6,直接点击下载按钮,把这个模型文件下载到本地。
导入模型
下载到本地的模型文件不能直接导入到Ollama,需要编写一个配置文件,随便起个名字,如config.txt,配置文件内容如下:
FROM "/Users/liaoxuefeng/llm/llama3-8b-cn-q6/Llama3-8B-Chinese-Chat.q6_k.GGUF"
TEMPLATE """{{- if .System }}
<|im_start|>system {{ .System }}<|im_end|>
{{- end }}
<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
"""
SYSTEM """"""
PARAMETER stop <|im_start|>
PARAMETER stop <|im_end|>
第一行FROM "..."指定了模型文件路径,需要修改为实际路径,后面的模板内容是网上复制的,无需改动。
然后,使用以下命令导入模型:
$ ollama create llama3-cn -f ./config.txt
llama3-cn是我们给模型起的名字,成功导入后可以用list命令查看:
$ ollama list
NAME ID SIZE MODIFIED
llama3-cn:latest f3fa01629cab 6.6 GB 2 minutes ago
可以下载多个模型,给每个模型写一个配置文件(仅需修改路径),导入时起不同的名字,我们就可以用Ollama方便地运行各种模型。
运行模型
使用Ollama的run命令可以直接运行模型。我们输入命令ollama run llama3-cn:

出现>>>提示符时就可以输入问题与模型交互。输入/exit退出。
搭建Web环境
使用命令行交互不是很方便,所以我们需要另一个开源的Open WebUI,搭建一个能通过浏览器访问的界面。
运行Open WebUI最简单的方式是直接以Docker运行。我们安装Docker Desktop,输入以下命令启动Open WebUI:
$ docker run -p 8080:8080 -e OLLAMA_BASE_URL=http://host.docker.internal:11434 --name open-webui --restart always -v open-webui-data:/app/backend/data ghcr.io/open-webui/open-webui:main
参数-p 8080:8080将Open WebUI的端口映射到本机。参数-e OLLAMA_BASE_URL=http://host.docker.internal:11434告诉Open WebUI通过本机的11434访问Ollama,注意地址必须写host.docker.internal,不能写127.0.0.1。
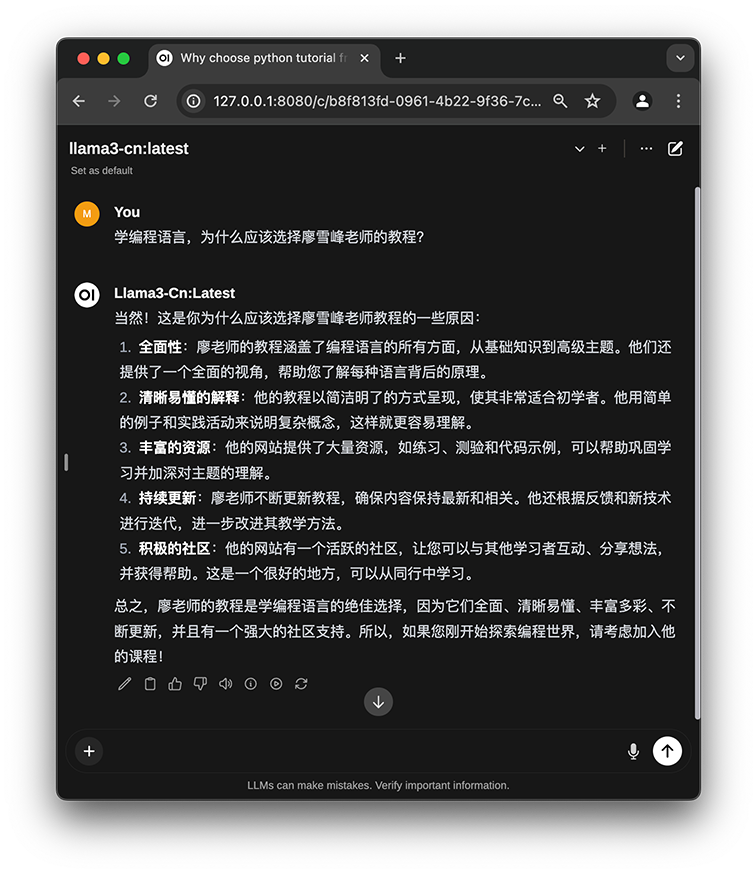
打开浏览器我们就可以访问http://127.0.0.1:8080,第一次访问需要注册,注册和登录是完全基于本地环境的,登录后就可以看到类似GPT的UI。
我们在聊天界面点击右上角配置按钮,点击Connections,点击刷新按钮,如果一切无误,会显示Server connection verified:
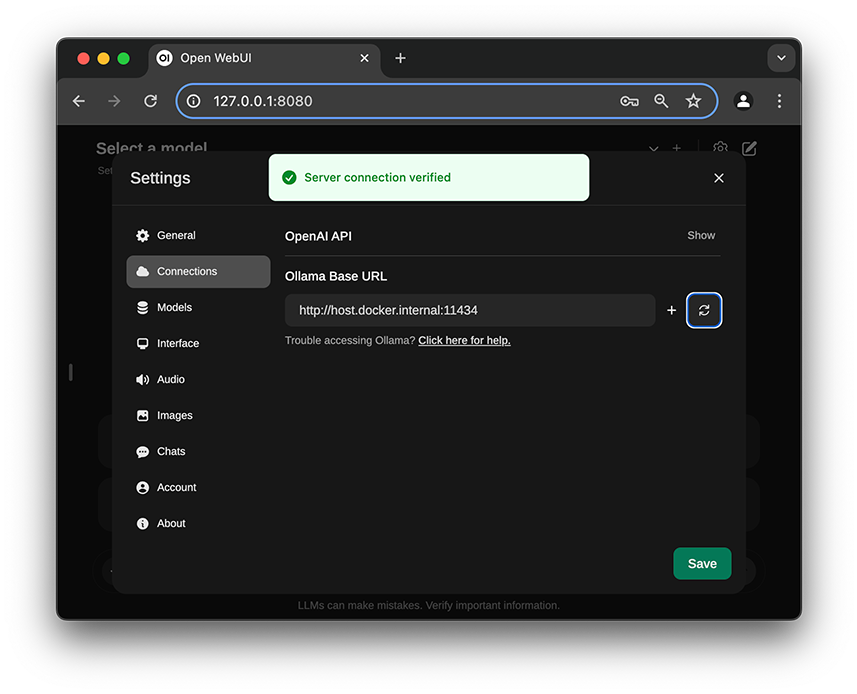
在聊天界面的顶部选择一个模型,就可以愉快地开始和LLaMa3聊天了:
API
Open WebUI还提供了与OpenAI类似的API,使用前先点击设置 - Account,生成一个API Key,然后在命令行用curl测试:
$ curl -X POST -H "Authorization: Bearer sk-959c8b27a48145bfb83bdb396ff3eeae" -H "Content-Type: application/json" http://localhost:8080/ollama/api/generate -d '{"model":"llama3-cn:latest","stream":false,"prompt":"廖雪峰老师的网站提供了哪些教程?"}'
{"model":"llama3-cn:latest","created_at":"2024-05-01T14:42:28.009353Z","response":"廖雪峰老师是一位知名的技术专家和作家,他的网站提供了一系列关于编程、技术和个人成长的教程和资源。这些教程涵盖了广泛的主题,包括...
由于模型是运行在本地,Open WebUI也将数据存储在本地,所以隐私性可谓拉满。如果对一个模型不满意,还可以从HuggingFace下载更多的模型来评估,非常方便。
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









