








大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于如果构建生成级别的AI架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
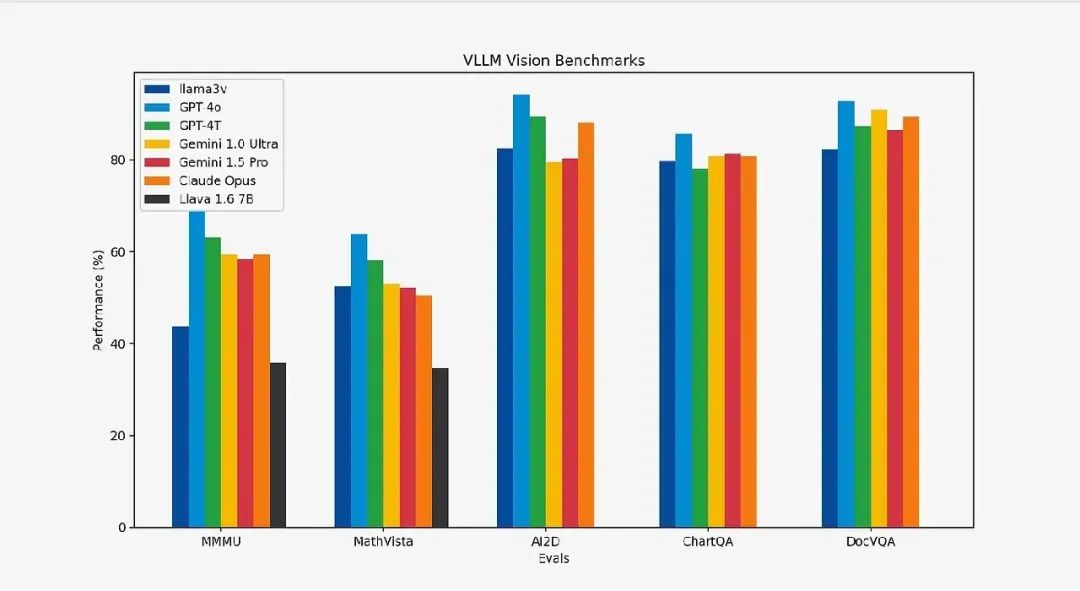
大模型领域风云变幻莫测。先是Llama3风靡全球,在几乎所有基准测试中都超越GPT-3.5,部分的基准测试超越了 GPT4。随后,GPT-4o横空出世,凭借其多模态重新夺回王位。而本文中的Llama3-v是研究人员带来新的惊喜,先看下图的统计。Llava是目前最先进的多模态理解模型,LLama3-V与Llava(多模态理解领域的SOTA)相比,提升了 10-20%。此外,除了MMMU之外,在其他指标的表现上和规模大于其 100 倍的闭源模型都毫不逊色。
基于Llama3 8B的LLama3-v与其他模型对比的基准指标数据:

模型架构
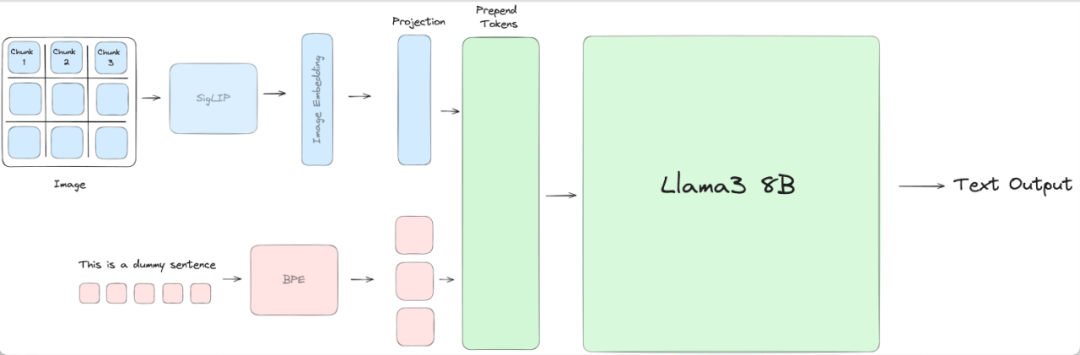
为了让Llama3理解视觉信息,因此研究人员将图像切块通过SigLIP模型获取图像的Embedding Vector,然后通过投影与输入文本Tokens对齐平面上。最后,投影块中的视觉Tokens添加到文本Tokens之前,并将联合表示传递到 Llama3。
SigLIP 模型由 Xiaohua Zhai、Basil Mustafa、Alexander Kolesnikov 和 Lucas Beyer在“Sigmoid Loss for Language Image Pre-Training”中提出。SigLIP 是一种与 CLIP 类似的图像嵌入模型。主要区别在于训练损失,SigLIP采用成对Sigmoid 损失,这允许模型独立地对每个图像-文本对进行操作,而无需对批次中的所有对进行全局查看,同时对 logits应用sigmoid激活函数,而不是softmax。

请看上图。换句大白话的说,sigLIP的损失函数是在文字Tokens和图像Tokens的两个序列的基础上计算出来。它指导着模型训练朝着这相同样本对(图,文)的点积值越大,而不同图文对的点积值越小的目标迈进。即矩阵对角线的越大,其余的各自越小。
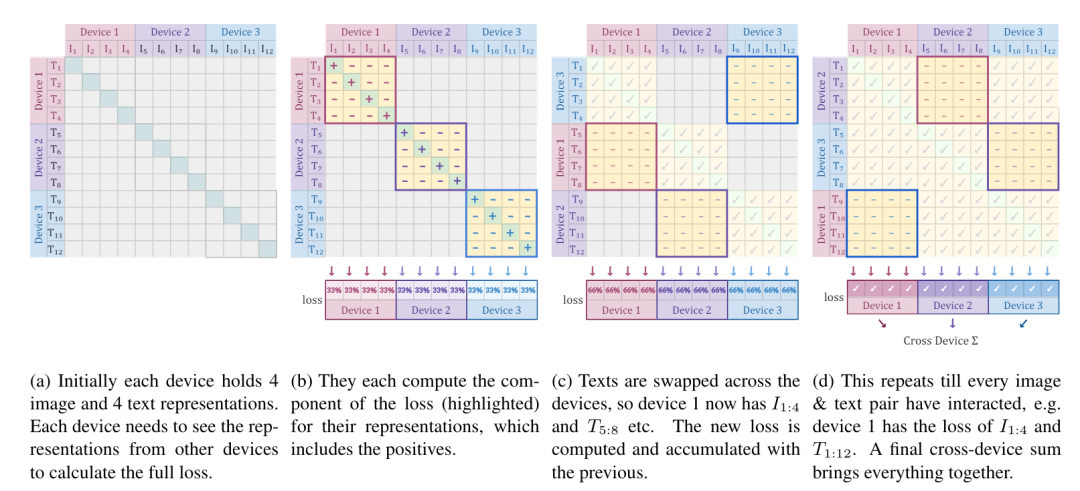
上图为SigLIP的预训练过程,它在三个设备进行训练。每设备持有4幅图和文字,在单设备上各自运算。紧接着不同的设备交换文本计算损失,如此循环直到全部计算完毕。
SigLIP 的视觉编码器在高层次上将图像分割成一系列不重叠的图像块,并将它们投影到低维线性嵌入空间中,从而产生一系列块嵌入。然后,这些块嵌入经过视觉编码器,该编码器应用自注意力来捕获长距离依赖关系并提取更高级的视觉特征。
虽然为了节省计算资源,在LLama3-v中直接使用由Google DeepMind训练的原始SigLIP模型。然而为了与文本嵌入对齐,还是在SigLIP输出之后使用了额外的投影模块。这与将单个线性层应用于原始图像嵌入的Llava不同,这个模块被改为训练两个自注意力块以便于更好地捕获输入模式,从而生成最终的图像嵌入向量(Embedding Vector)。
对于文本输入,首先使用字节对编码 (BPE) 词汇表对文本进行Tokenizer,从而生成文本标记序列。这些标记(Token)会被包在特殊的 <text>和</text>标签中来进行区分。对于来自投影层的图像输出将被视为单独的“视觉标记”,并使用<image>和</image>标签划分它们。视觉标记序列前置到文本标记序列,形成新的序列成为Llama3的联合输入。

SigLIP
SigLIP模型比Llama3小得多,而且在整个过程中是被冻结参数的。因此对于预训练和 SFT,我们直接传入这些预先计算好的图像嵌入(Embedding),而不是重新运行SigLIP。这使得训练能够增加批处理大小并最大限度地利用GPU来运行SigLIP,还为节省了训练/推理时间。
为了进一步的优化速度,由于SigLIP也适合运行在Macbook,因此采用MPS 优化过的SigLIP模型上进行运算,这样一来就能够实现每秒 32 张图像的吞吐量,让上个步骤得以实行。
MPS(Metal Performance Shaders)是Apple提供的一套框架,专门用于在Apple设备上加速机器学习和图形计算。
通过SigLIP预计算图像嵌入的步骤,目标是将图像传入SigLIP以获得图像的矢量表示或嵌入。
由于分辨率较高,研究人员遵循LLaVA-UHD采用的方法并执行图像分割。图像分割的目的是将图像分成可变大小的块或片段,以实现更高效的编码和批量处理。

细节分析
首先加载 SigLIP 模型和处理器/标记器,然后使用处理器预处理提供的输入图像。紧跟着将预处理后的图像传递给模型。之后获得模型的输出,将 S型激活函数应用于输出以获得概率。
通过 SigLIP 计算图像嵌入之后,我们现在开始学习投影矩阵——你也可以将其视为投影层,它通常是线性或前馈层。如上文成分部分所述,投影层将视觉嵌入从其原始空间映射到联合多模态嵌入空间。具体而言,投影层将学习到的权重矩阵 Wv 应用于视觉嵌入 v 以获得投影的多模态视觉嵌入 Wv * v(矩阵运算)。通过投影之后,视觉和文本嵌入基本上被对齐到一个共同的多模态嵌入空间,这样一来视觉和文本就融合了,可以运用到各种的多模态任务,如视觉问答、图像字幕等。
根据上述而言图像标记序列添加到文本标记序列之前。之所以添加在前面,是因为将图像放在文本之前,可以让模型在预训练期间更容易学习。

这里借用了LLaVA-UHD的架构图,因为LLama3-v和LLaVA-UHD几乎相同,两者只不过在组件的选择不同而已。前者采用了SigLIP和LLama3,而后者选择CLIP-ViT和Vicuna-13B作为基座模型。

训练回放
训练分为两个阶段:在预训练中使用 600,000 个样本,该步骤保持 Llama-3架构的主要权重不变,主要训练投影矩阵。这里主要是为了训练图像Tokens与文本Tokens的联合对齐。
在第二个阶段微调更多的类似指令微调。这个步骤冻结SigLIP模型和投影层的权重,但是更新Llama3 8B模型的权重和其余的参数。这里用了大约1M张图像。除此之外还利用了从YI模型系列生成的多模态合成数据。















 3344
3344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









