






大模型算法工程师经典面试题————为什么现在的主流大模型都是 decoder-only 架构?
本人是某双一流大学硕士生,也最近刚好准备参加 2024年秋招,在找大模型算法岗实习中,遇到了很多有意思的面试,所以将这些面试题记录下来,并分享给那些和我一样在为一份满意的offer努力着的小伙伴们!!!
面试题
为什么现在的主流大模型都是 decoder-only 架构?
相比encoder-decoder架构,只使用decoder有什么好处吗?
标准答案
首先概述几种主要的架构:以BERT为代表的encoder-only、以T5和BART为代表的encoder-decoder、以GPT为代表的decoder-only,还有以UNILM为代表的PrefixLM(相比于GPT只改了attention mask,前缀部分是双向,后面要生成的部分是单向的causalmask),可以用这张图辅助记忆:
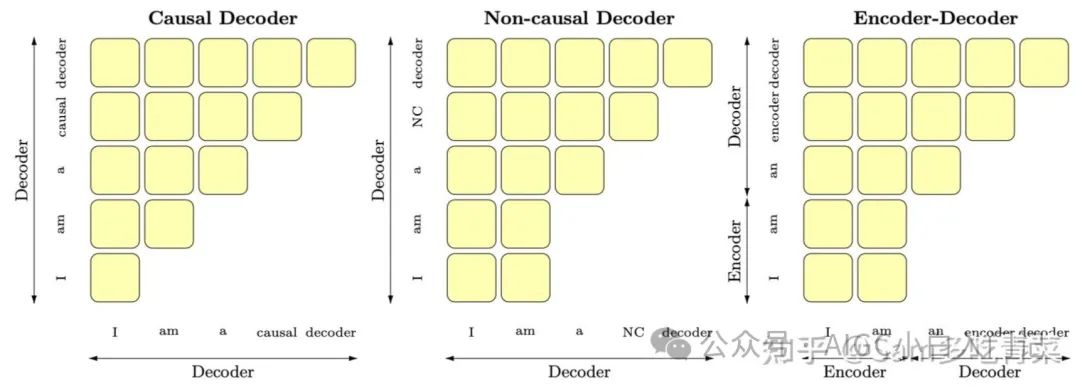
要回答该问题,需要从自回归(autoregressive)生成方法、模型架构和训练效率和应用需求等多个角度进行回答:
1. 自回归(autoregressive)生成方法
-
原理:Decoder-only架构的模型,比如GPT系列,主要运用自回归生成策略。这意味着在生成每一个词汇时,模型都会参考之前生成的所有词汇。这种机制非常适合需要逐步构建序列的任务,如文本创作和对话系统。
-
优势:
-
连贯性与上下文一致性:自回归生成方式确保每个新生成的词汇都能考虑到前面的上下文,从而保证输出文本的连贯性和上下文一致性。
-
高效稳定的文本生成:通过逐个词汇生成的方式,Decoder-only模型避免了一次性预测整个序列的需求,这不仅使生成过程更为稳定,同时也提高了效率。
2. 模型架构和训练效率
-
原理:与Encoder-Decoder 架构相比,Decoder-only 模型具有更简洁的架构。Encoder-Decoder 架构主要用于那些需要对输入序列进行编码的任务,例如机器翻译;而 Decoder-only 模型则直接专注于解码(生成)输出序列。
-
优点:
-
简化架构设计:仅包含一个 Decoder 模块,这种精简的设计使得模型在实现和调试方面更加简便。
-
提高训练效率:由于模型中只涉及单一模块的训练,因此训练过程更为高效,有效减少了所需的计算资源和时间。
3. 应用需求驱动
-
原理:多种自然语言处理应用,如文本生成、对话系统和自动补全等功能,其核心需求在于生成连贯的文本序列,而非将一个序列转换为另一个序列(例如在翻译任务中)。
-
优点:
-
适合生成任务:Decoder-only模型特别适用于直接生成任务,能更好地符合实际应用场景的需求。
-
高度灵活:该架构可以灵活应对不同长度和复杂程度的文本生成任务,展现出更强的适应能力。
4. 预训练和微调策略
-
原理:Decoder-only模型一般采用自回归预训练的方法,通过预测后续词汇来学习大规模数据集中的语言结构和模式。这种方法不仅简单高效,还易于应用于更大规模的数据集上。
-
优势:
-
高效的预训练:自回归预训练策略在捕获语言模式及上下文信息方面表现出色,有助于提高模型在生成任务上的性能。
-
灵活的微调:在针对特定下游任务进行微调时,Decoder-only模型能够通过简便的任务适应策略迅速调整,以满足具体任务的需求。
5. 计算资源优化
-
原理:在大规模模型训练过程中,高效利用计算资源至关重要。Decoder-only模型通过精简计算组件的数量,实现了计算资源使用的优化。
-
优势:
-
节约计算资源:仅需要训练Decoder模块,因此对计算资源的需求较低。
-
易于扩展:这种模型架构更便于扩展至更大的参数规模,能充分利用现有的硬件资源来进行更大规模的训练。
其他观点
在知乎上有一个很经典的问题《为什么现在的LLM都是Decoder only的架构?》(https://www.zhihu.com/question/588325646),很多大佬针对该问题做了很好的回答,这里稍微总结:
-
@苏剑林 苏神强调的注意力满秩的问题,双向attention的注意力矩阵容易退化为低秩状态,而causal attention的注意力矩阵是下三角矩阵,必然是满秩的,建模能力更强;
-
@yiī 大佬强调的预训练任务难度问题,纯粹的decoder-only架构+next token predicition预训练每个位置所能接触的信息比其他架构少,要预测下一个token难度更高,当模型足够大,数据足够多的时候,decoder-only模型学习通用表征的上限更高
-
@mimimumu 大佬强调,上下文学习为decoder-only架构带来的更好的few-shot性能:prompt3.和demonstration的信息可以视为对模型参数的隐式微调[2],decoder-only的架构相比encoder-decoder在in-context learning上会更有优势,因为prompt可以更加直接地作用于decoder每一层的参数,微调的信号更强;
-
多位大佬强调了一个很容易被忽视的属性,causal attention(就是decoder-only的单向4attention)具有隐式的位置编码功能[3],打破了transformer的位置不变性,而带有双向attention的模型,如果不带位置编码,双向attention的部分token可以对换也不改变表示,对语序的区分能力天生较弱。
下面分享一下,我在春招过程中所整理的面试题资料。
yang19527/AwesomeInterview: 包含程序员面试大厂面试题和面试经验 (github.com)
https://github.com/yang19527/AwesomeInterview
大模型算法岗
大模型算法岗面试经验
-
【面试题解答】荣耀NLP算法工程师 一面试题解答
-
【面试题解答】华为NLP算法工程师 一面试题解答
-
【面试题解答】SHEIN算法工程师 一面试题解答
-
【面试题解答】科大讯飞NLP大模型实习 一面试题解答
-
【面试题解答】网易NLP大模型实习 一面试题解答
-
【面试题解答】得物NLP算法工程师 一面试题解答
-
【面试题解答】字节 大模型算法工程师 一面试题解答
-
【面试题解答】知乎 大模型算法工程师 一面试题解答
-
【面试题解答】58同城NLP算法工程师 一面试题解答
-
【面试题解答】阿里智能NLP算法工程师 一面试题解答
-
【面试题解答】百度大模型算法师 一面试题解答
-
【面试题解答】商汤NLP算法工程师 实习一面面试题解答
-
【面试题解答】小米大模型实习一面面试题解答
-
【面试题解答】昆仑天工大模型实习一面面试题解答
-
【面试题解答】百度-NLP算法工程师面经
-
【面试题解答】小米-NLP算法工程师面试题
-
【面试题解答】百度大模型算法工程师面经
-
【面试题解答】昆仑天工大模型算法工程师
-
【面试题解答】SHEIN NLP算法工程师 一面试题解答
-
【面试题解答】淘天阿里妈妈NLP算法工程师 一面试题解答
大模型算法岗面试题(未包含答案)
-
【面试题】美团算法面试题汇总
-
【面试题】荣耀算法面试题汇总
-
【面试题】太初算法面试题汇总
-
【面试题】长亭科技大模型算法工程师面试题
-
【面试题】网易算法面试题汇总
-
【面试题】科大讯飞算法面试题汇总
-
【面试题】SHEIN 算法面试题汇总
-
【面试题】滴滴算法面试题汇总
-
【面试题】OPPO算法面试题汇总
-
【面试题】金山 大模型算法工程师面试题
-
【面试题】平安科技 大模型算法工程师面试题
-
【面试题】海康威视 大模型算法工程师面试题
-
【面试题】理想汽车大模型算法工程师面试题
-
【面试题】淘天算法面试题汇总
-
【面试题】快手算法面试题汇总
-
【面试题】搜狐算法面试题汇总
机器视觉算法岗
机器视觉算法岗面试经验
-
【面试题解答】字节CV算法工程师 一面试题解答
-
【面试题解答】趣玩科技公司CV算法工程师 一面试题解答
-
【面试题解答】百度 计算机视觉算法工程师 一面试题解答
-
【面试题解答】深信服CV算法工程师 一面试题解答
机器视觉岗面试题(未包含答案)
-
【面试题】商汤 大模型算法工程师面试题
-
【面试题】蚂蚁金服 大模型算法工程师面试题
-
【面试题】旷视 大模型算法工程师面试题
软件后台岗
软件后台岗面试经验
- 【面试题解答】WXG 软件后台岗 一面试题解答
数据挖掘算法岗
数据挖掘算法岗面试经验
-
【面试题解答】快手数据分析师 实习一面面试题解答
-
【面试题解答】字节数据科学算法师 实习一面试题解答
-
【面试题解答】美团数据科学算法工程师 一面试题解答
-
【面试题解答】招银网科 数据科学算法工程师 一面试题解答
-
【面试题解答】美团 数据挖掘算法工程师 一面试题解答
-
【面试题解答】快手数据科学算法工程师 一面试题解答
-
【面试题解答】万物心选数据科学算法工程师 一面试题解答
推荐系统算法岗
推荐系统算法岗面试经验
-
【面试题解答】快手推荐算法实习 一面试题解答
-
【面试题解答】联想 推荐系统算法工程师 一面试题解答
广告算法岗
广告算法岗面试经验
- 【面试题解答】快手广告算法工程师 一面试题解答
















 1755
1755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









