






卷积神经网络CNN
一.从全连接层到卷积
将输入和输出由原本的一维向量变形为矩阵(宽度,高度),那么权重将会变形为四维张量
使用Xij代表输入图像中位置(i,j)处的像素,Hij代表隐藏中位置(i,j)处的像素
i,j是h高度的参数,kl是w平面上的参数

使得k=i+a,l=j+b,则可以得到重新索引
原则一:平移不变性
对于权重作出限制,对模型的复杂度降低,不用再存过多元素,不依赖于高度坐标,只依赖于a,b坐标

原则二: 局部性
只局限在Xi,j附近,超过一定范围,加上限制条件,将权重归为0

卷积层
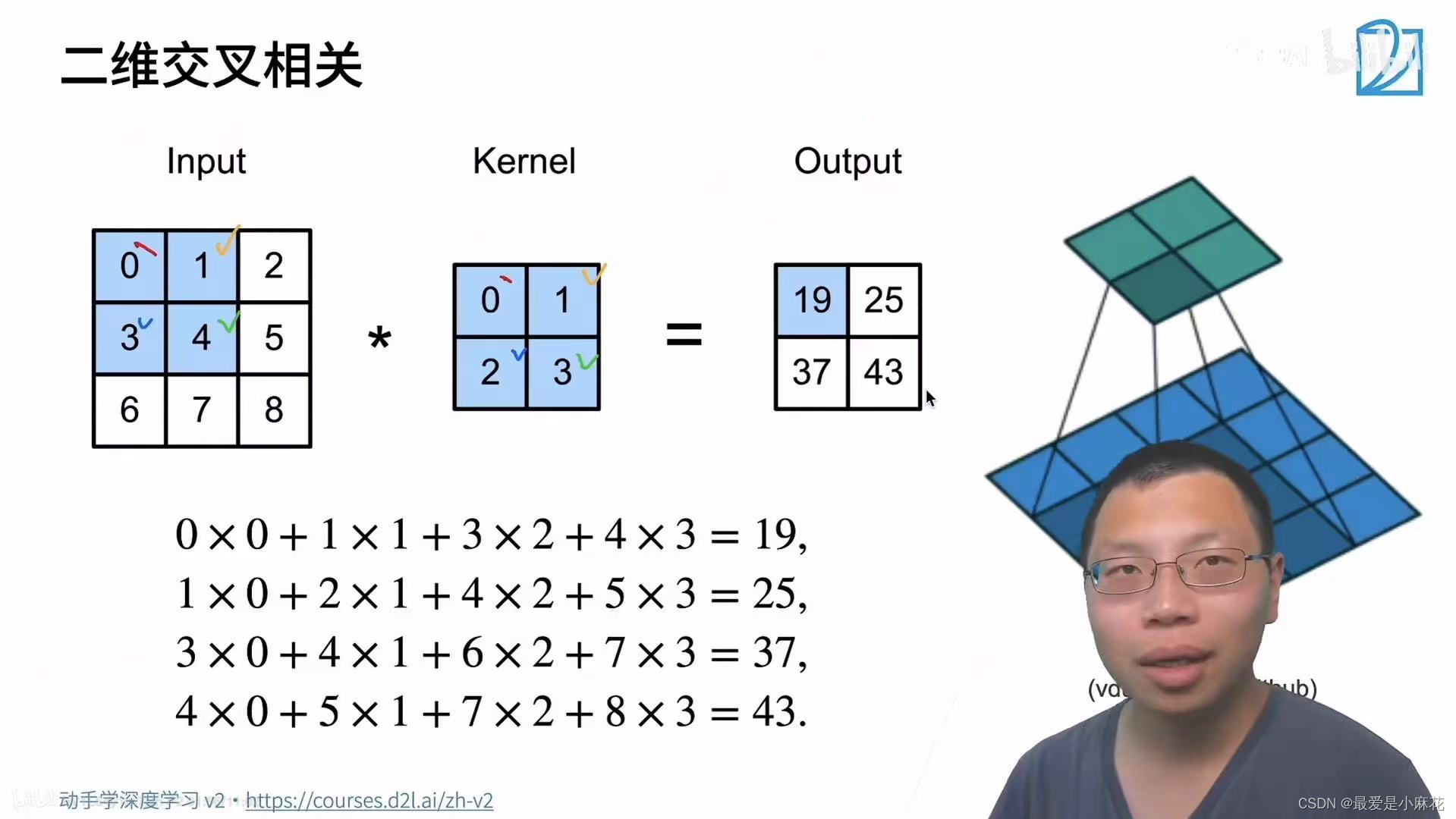

二维互相关运算
def corr2d(X,K): #X是输入,K是核矩阵
h,w=K.shape
Y=torch.zeros((X.shape[0]-h+1,X.shape[1]-w+1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i,j]=(X[i:i+h,j:j+w]*K).sum()
return Y卷积层:
'''二维卷积'''
class Conv2D(nn.Module):
def __init__(self,kernel_size):
super().__init__()
self.weight=nn.Parameter(torch.rand(kernel_size))
self.bias=nn.Parameter(torch.zeros(1))
def forward(self,X):
return corr2d(X,self.weight)+self.bias

图像中目标的边缘检测
'''检测边缘'''
X=torch.ones((6,8))
X[:,2:6]=0#中间四列为黑色是0,其他列为白色是1
print(X)
'''tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])'''
K=torch.tensor([[1.0,-1.0]])#如果水平相邻元素相同,则输出为0,否则输出为非0
Y=corr2d(X,K)
print(Y)#1为白色到黑色的边缘,0为黑色到白色的边缘
'''tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])'''不同的核进行卷积操作,得到不同的效果,关键点在于想要什么效果,用网络学习出一个能达到效果的核

卷积层将输入和核矩阵进行交叉相关,加上偏移后得到输出,核矩阵和偏移是可学习的参数,核矩阵大小是超参数(限制了检索范围)
学习由X生成Y的卷积核矩阵
已知输入和输出,现在求出核矩阵
import torch
from torch import nn
#构造一个二维卷积层,输出通道数为1,和形状为(1,2)的卷积核
conv2d=nn.Conv2d(1,1,kernel_size=(1,2),bias=False)
#四维输入和输出格式(批量大小,通道,高度,宽度)
X=X.reshape((1,1,6,8))
Y=Y.reshape((1,1,6,7))
lr=3e-2
for i in range(10):
Y_hat=conv2d(X)#得到预测输出Y_hat
l=(Y_hat-Y)**2#计算预测输出 Y_hat 和目标输出 Y 之间的均方误差损失 l
#平方运算的目的是放大较大的误差
conv2d.zero_grad()#将卷积层的梯度缓存清零,以准备下一次反向传播
l.sum().backward()# 对损失求和并进行反向传播,计算卷积层权重的梯度
#迭代卷积核
conv2d.weight.data[:]-=lr*conv2d.weight.grad#将卷积核的权重减去学习率乘以梯度的乘积,实现梯度下降更新
if(i+1)%2==0:#如果当前迭代次数加 1 能被 2 整除,则打印当前的迭代次数和损失值
print(f'epoch{i+1},loss{l.sum():.3f}')
conv2d.weight.data.reshape((1,2))#误差足够小后得到的权重张量通过这个训练过程,卷积神经网络通过不断调整卷积核的权重,使预测输出尽可能接近目标输出,从而最小化损失函数
二.填充和步幅
填充
问题:给定大小图像,用卷积核进行卷积,层数是有限的,但是深度学习的根本,是用更深层的网络解决,这种情况怎么办?解决这个问题:填充
在输入的周围加上一些行和列,可以让输出比原来更大
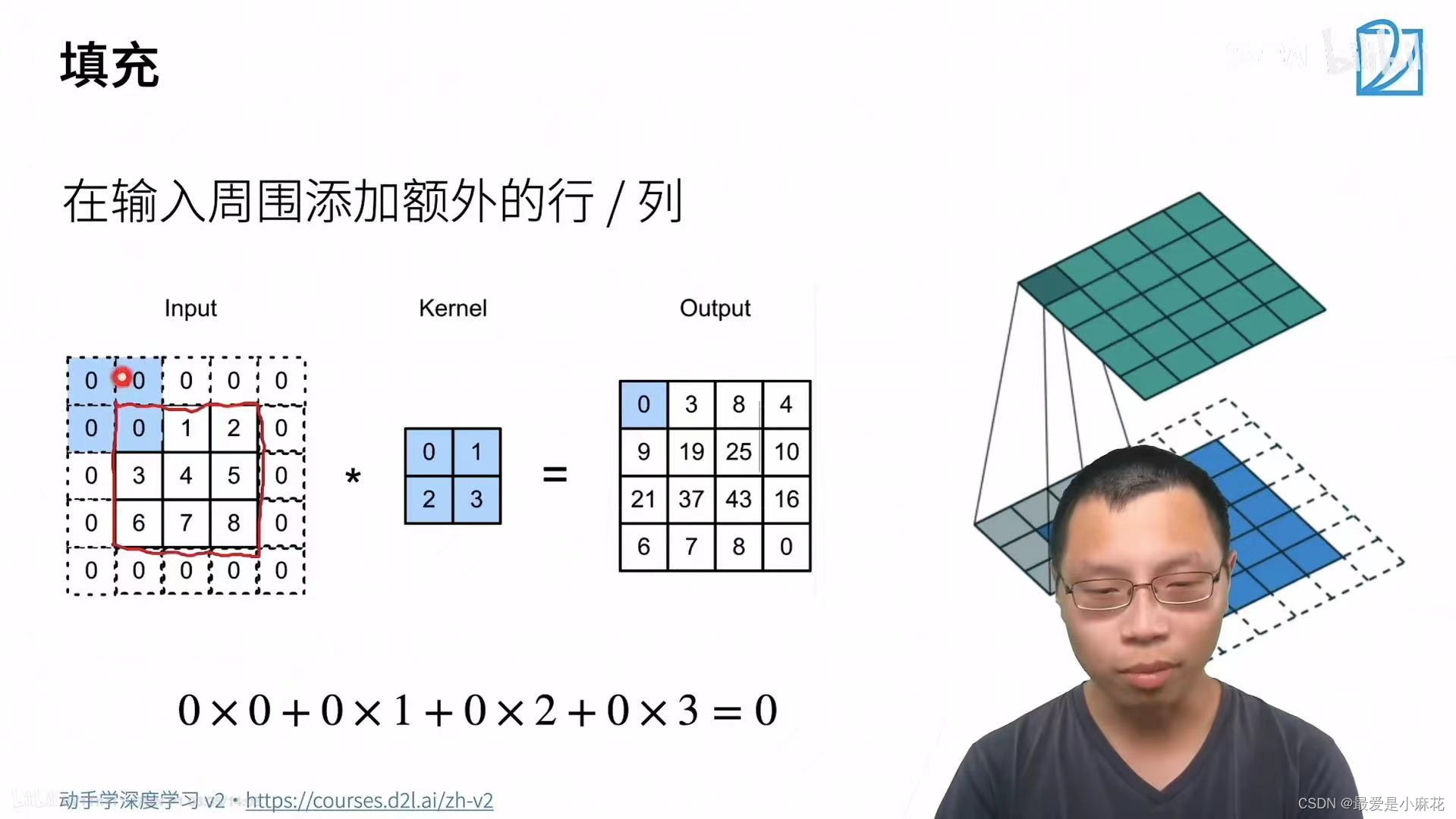
通常取值会让输入和输出的形状一致,这样的好处就在于无论选取多大的卷积核,不会让输入的形状发生改变

注意这里是填充ph行,上下一共行数 ,padding是每一边填充的行数
填充两行ph=2,上下左右各一行的例子:
def comp_conv2d(conv2d,X):
X=X.reshape((1,1)+X.shape)
#调整为四维张量的格式 ,假设 X 的原始形状为二维 (高度, 宽度),添加了批量大小和通道维度
Y=conv2d(X)
return Y.reshape(Y.shape[2:])#表示获取 Y 的形状中从索引 2 开始的维度,即 (高度, 宽度)
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1)# 一个 nn.Conv2d 类的实例
X=torch.rand(size=(8,8))#创建了一个随机的输入张量 X,形状为 (8, 8)
print(comp_conv2d(conv2d,X).shape)
#torch.Size([8, 8])也可以上下和左右填充不一样
conv2d = nn.Conv2d(1,1,kernel_size=(5,3),padding=(2,1))# 一个 nn.Conv2d 类的实例
X=torch.rand(size=(8,8))#创建了一个随机的输入张量 X,形状为 (8, 8)
print(comp_conv2d(conv2d,X).shape)
#torch.Size([8, 8])步幅
问题:一个较大的输入大小,卷积核通常不会取太大一般就是5*5,3*3,那么这种情况下,需要很多层数才能将输出降低?解决这个问题:步幅
步幅是指控制核矩阵在输入上移动的距离

步幅例子:
conv2d = nn.Conv2d(1,1,kernel_size=(3,5),padding=(0,1),stride=(3,4))# 一个 nn.Conv2d 类的实例
X=torch.rand(size=(8,8))#创建了一个随机的输入张量 X,形状为 (8, 8)
print(comp_conv2d(conv2d,X).shape)
#torch.Size([2, 2])填充和步幅都是卷积层的超参数
三.卷积层的多个输入和输出通道
多个输入通道:
彩色图像有RGB三个通道,每个通道都有自己的卷积核,做完卷积的结果后,相加得到最终结果。
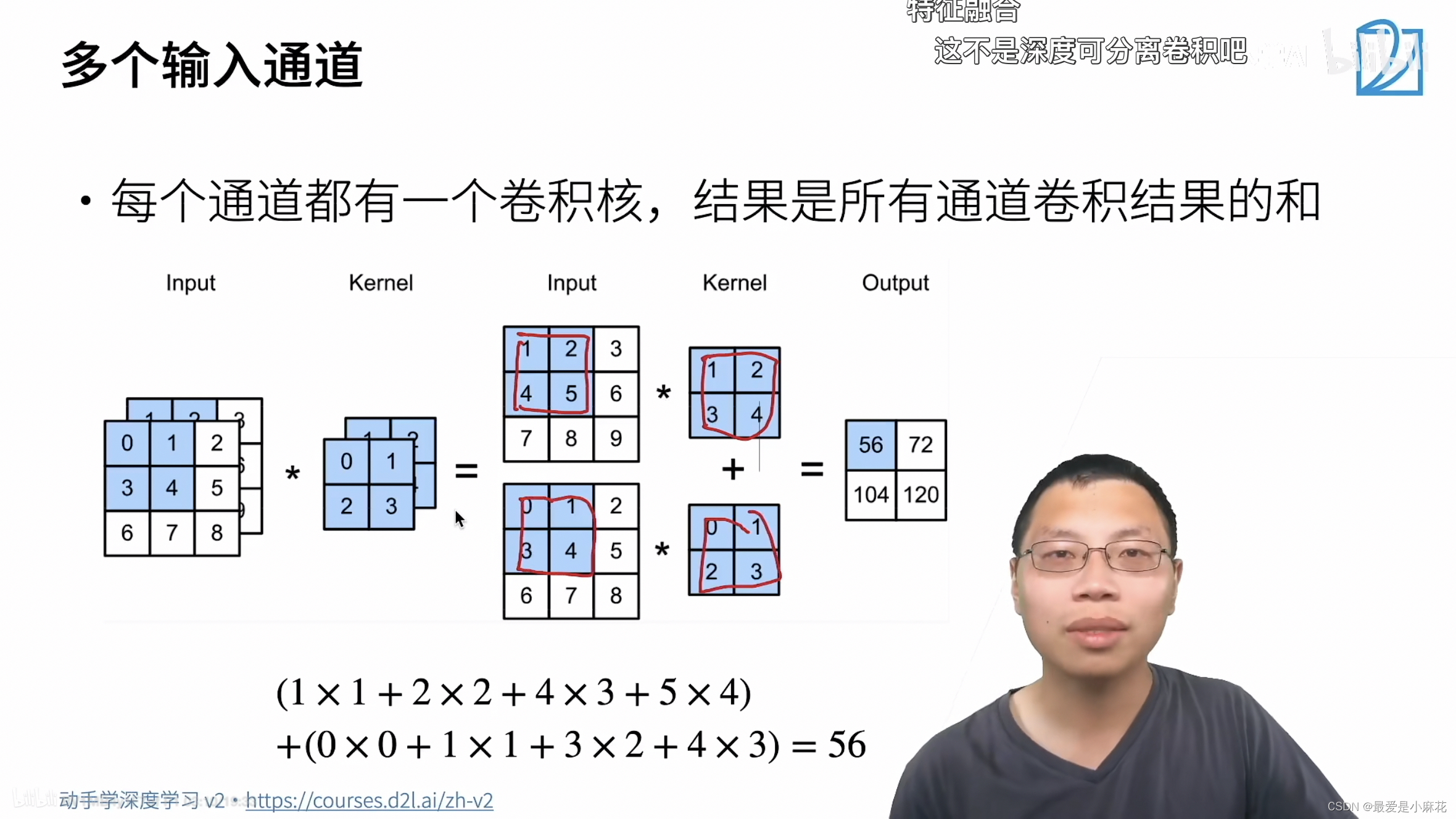
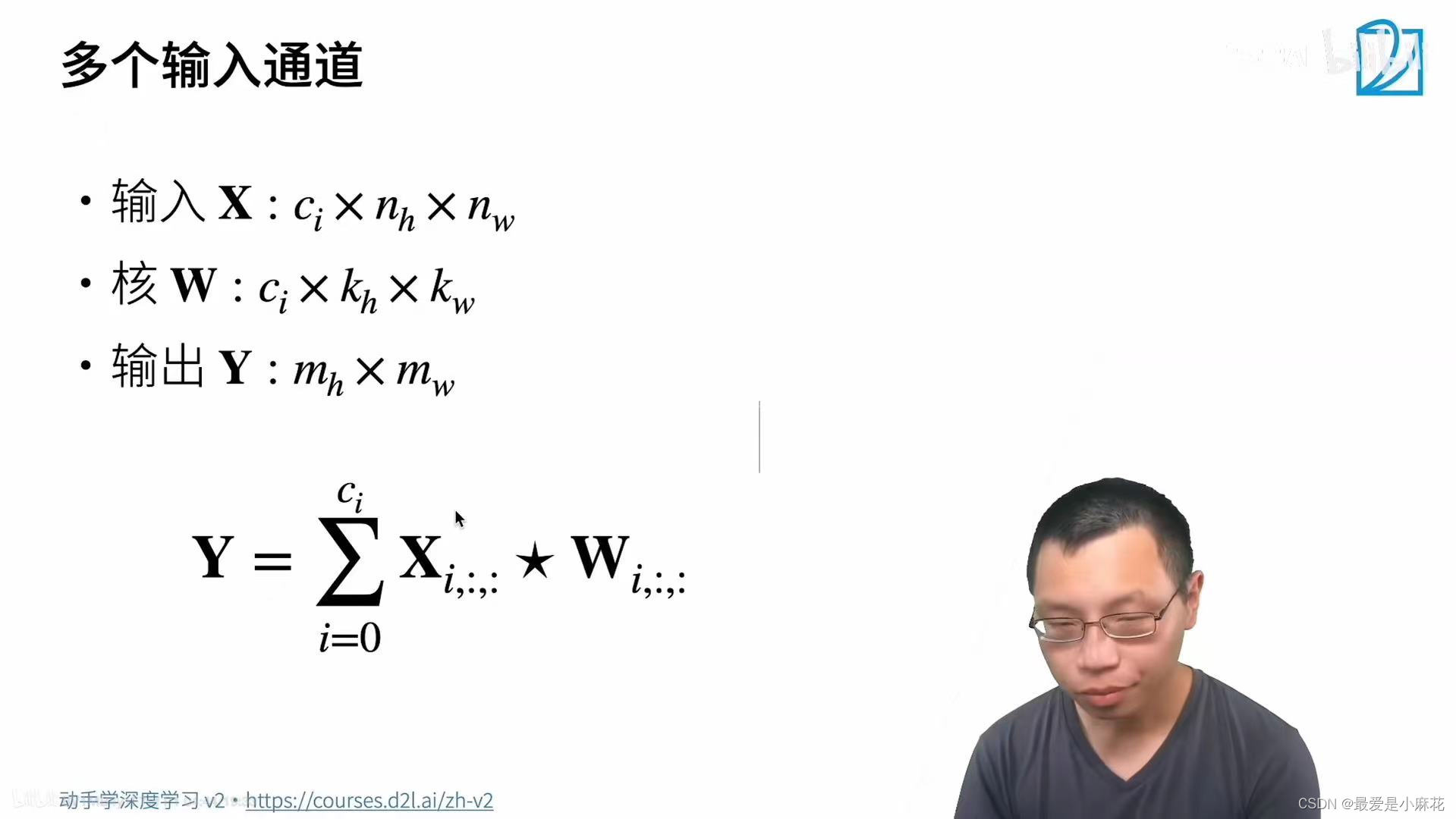
输出是一个单通道
代码:
def corr2d_multi_in(X,K):
return sum(d2l.corr2d(x,k) for x,k in zip(X,K))
#zip用于将两个或多个可迭代对象的对应元素配对,
#对于每个 (x, k) 对,使用 d2l.corr2d(x, k) 计算二维互相关运算的结果
X=torch.tensor([[[0,1,2],[3,4,5],[6,7,8]],
[[1,2,3],[4,5,6],[7,8,9]]])
K=torch.tensor([[[0,1],[2,3]],
[[1,2],[3,4]]])
print(corr2d_multi_in(X,K))
'''tensor([[ 56., 72.],
[104., 120.]])'''
多个输出通道:

Ci和Co分别代表输入和输出通道的数量,可以为每个输出通道创建一个形状为Ci*Kh*Kw的卷积核张量。运算就是每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
代码:
def corr2d_multi_in_out(X,K):
return torch.stack([corr2d_multi_in(X,k) for k in K],0)
K=torch.stack((K,K+1,K+2),0)K原本是三维,stack就是新建立一个0的维度,在0的维度上把之前的三维堆叠起来,输出通道是3.
多输出通道就是每个输出通道在识别特定模式:不同角度的边缘,某个颜色通道的点......
多输入通道就是现在有了这些不同特定模式,统一传到一层卷积,将它们组合起来
1*1的卷积层:
卷积层高和宽都为1,不识别空间模式,只融合通道
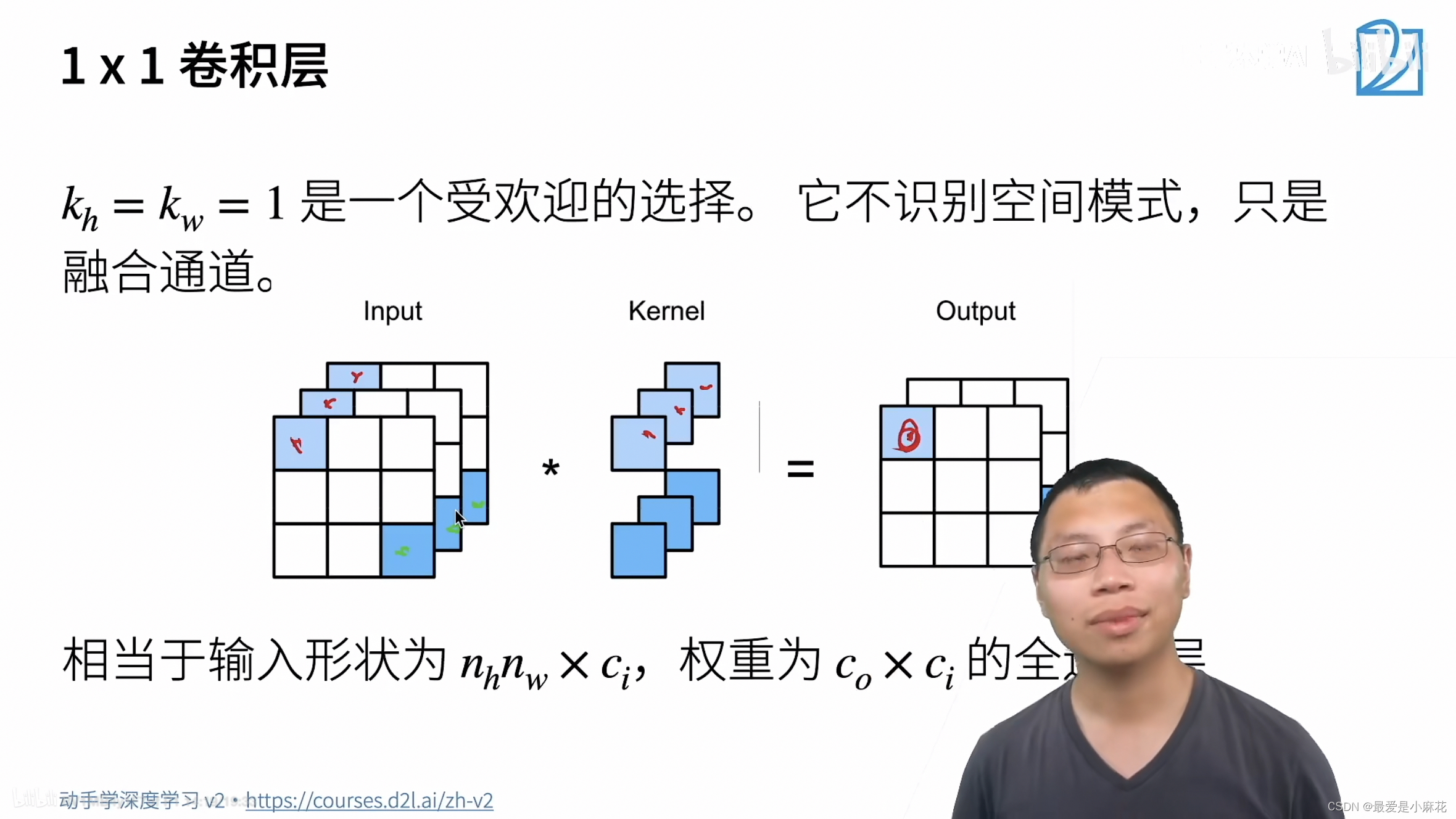
def corr2d_multi_in_out(X,K):
return torch.stack([corr2d_multi_in(X,k) for k in K],0)
K=torch.stack((K,K+1,K+2),0)
def corr2d_multi_in_out_1x1(X,K):
c_i,h,w=X.shape
c_o=K.shape[0]
X=X.reshape((c_i,h*w))
K=K.reshape((c_o,c_i))
Y=torch.matual(K,X)
return Y.reshape((c_o,h,w))
X= torch.normal(0,1,(3,3,3))
K=torch.normal(0,1,(2,3,1,1))
Y1=corr2d_multi_in_out_1x1(X,K)
总结:输出通道数是卷积层的超参数,每个输入通道有独立的二维卷积核,每个输出通道有独立的三维卷积核
四.池化层
主要是为了缓解卷积层对位置的敏感性
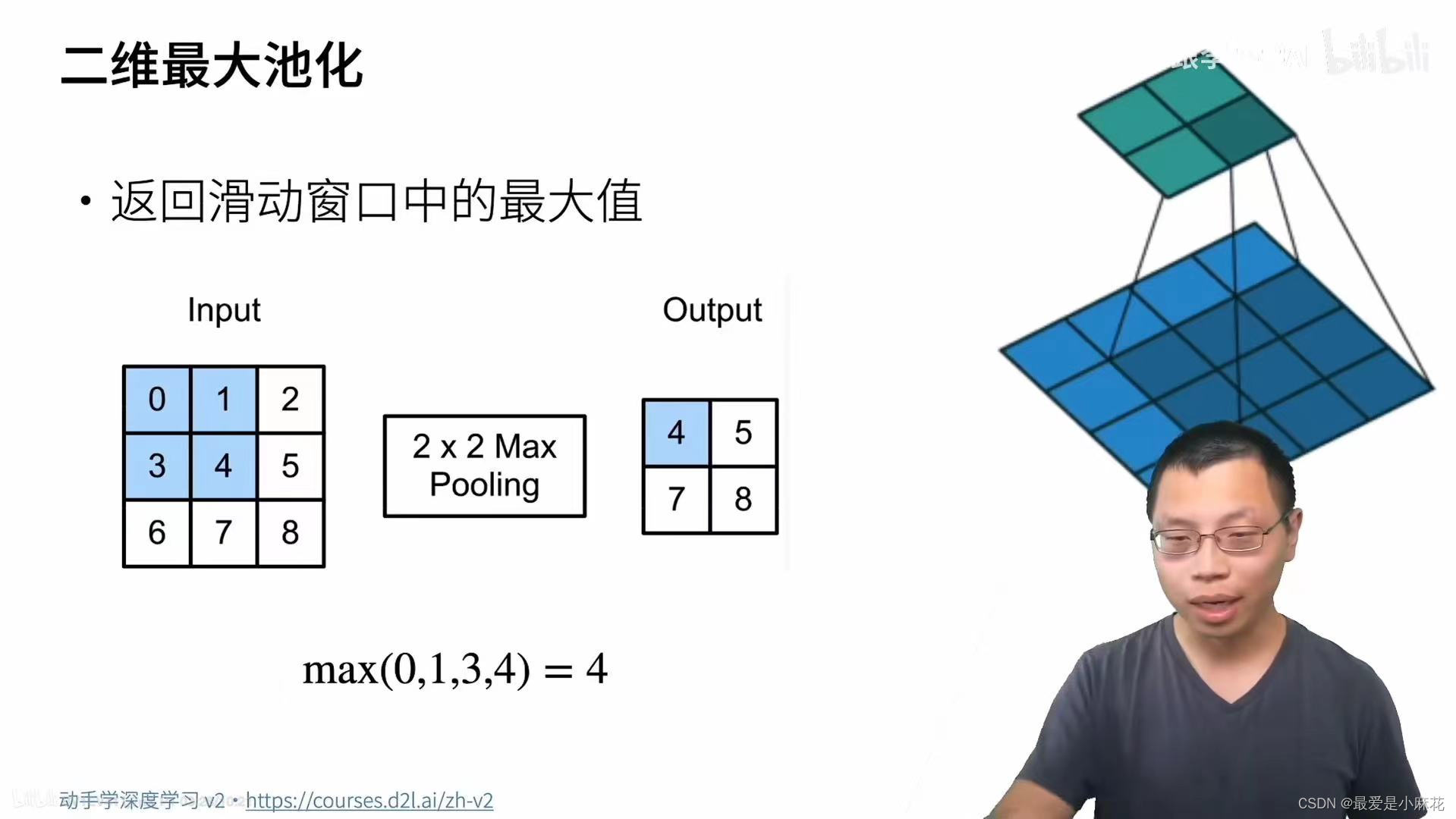
二维最大池化:
同样是有窗口,取窗口范围内的最大值
垂直边缘检测效果就是将边缘模糊化,可容输入一个像素的偏移,出现偏差后不会差距过大

填充和步幅是与卷积类似的两个超参数
在多输入的情况下,在每个输入通道应用池化层获得相应的输出通道,不会进行通道融合,因此输出通道数等于输入通道数

平均池化层:
返回窗口内的平均值
代码:
def pool2d(X,pool_size,mode='max'):#默认情况下是最大池化层
p_h,p_w=pool_size
Y=torch.zeros((X.shape[0]-p_h+1,X.shape[1]-p_w+1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i,j] = X[i:i+p_h,j:j+p_w].max()
elif mode == 'avg':
Y[i,j] = X[i:i+p_h,j:j+p_w].mean()
return Y
X=torch.tensor([[0.0,1.0,2.0],[3.0,4.0,5.0],[6.0,7.0,8.0]])
print(pool2d(X,(2,2)))
'''tensor([[4., 5.],
[7., 8.]])'''
print(pool2d(X,(2,2),'avg'))
'''tensor([[2., 3.],
[5., 6.]])'''X = torch.arange(16,dtype=torch.float32).reshape((1,1,4,4))
pool2d=nn.MaxPool2d(3)
print(pool2d(X))#深度学习框架中的步幅默认和池化窗口大小相同
#tensor([[[[10.]]]])
填充和步幅也可以手动指定
X = torch.arange(16,dtype=torch.float32).reshape((1,1,4,4))
pool2d=nn.MaxPool2d(3,padding=1,stride=2)
print(pool2d(X))
#tensor([[[[ 5., 7.],
# [13., 15.]]]])池化层在每个输入通道上单独运算
cat是在现有维度上的连接,stack是在新维度上的堆叠
X = torch.arange(16,dtype=torch.float32).reshape((1,1,4,4))
#池化层在每个输入通道上单独运算
X=torch.cat((X,X+1),1)
print(X)
'''tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])'''
pool2d=nn.MaxPool2d(3,padding=1,stride=2)
print(pool2d(X))
'''tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])'''总结:池化层通常放在卷积层后面,让其对位置不要过于敏感















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









