






“互联生活快步走,‘移民’‘难民’不掉队!” 中老年人互联网生活调查研究 ——以保定市为例
问卷抽样方法【pps抽样法,分层抽样法】
数据分析方法
层次分析法确定权重,topsis计算互联网使用评分
logistics回归模型分析互联网移民难民
结构方程模型探究影响因子【移民、难民】
结论
没有亮点,还不如我写的那一篇。
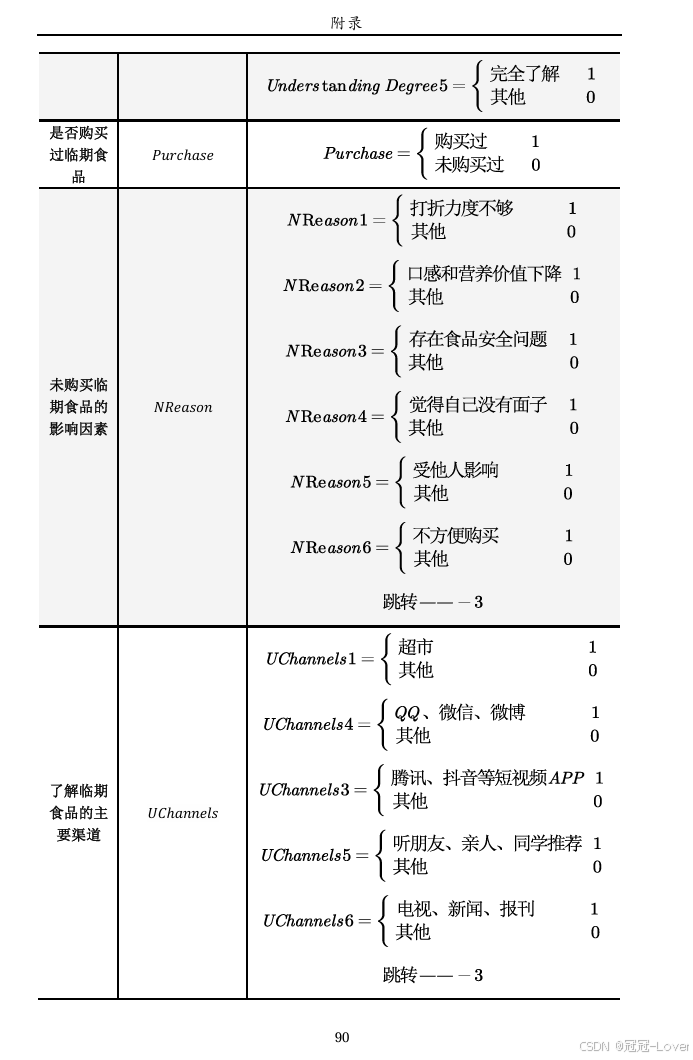
欢迎光“临”·“期”待邂逅 ——成都市“临期食品”的消费者购买行为分析及发展方向创新探究
回收问卷1040份
抽样调查,不等概率等距抽样,简单随机抽样相结合的多阶段抽样方法
认知现状-购买现状-购买习惯-心理特征四个方面收集数据
信效度+随机性检验
消费者的认知现状和购买现状
购买行为影响因素
发展方向创新
第一部分--------对临期食品的认知现状和购买现状分析
描述性得到初步结论
列联分析研究几个特征与临期食品购买意愿之间的关系【显著相关】
从消费者对于临期食品的了解程度、态度、购买习惯和购买频率以及在临期食品上的花费五个方面进行聚类分析挖掘消费者的购买行为特征
这里一个写的五个方面一个写的六个方面

第二部分-------从临期食品购买行为影响因素分析
描述性统计
灰色关联分析研究影响因素对购买行为的影响程度大小
综合评价模型定量分析购买临期食品的积极性
logistics回归分析消费习惯中的因素对购买行为的影响程度大小
方差分析研究不同性别、年龄、学历和职业下的样本差异情况
第三部分-------从临期食品发展方向分析
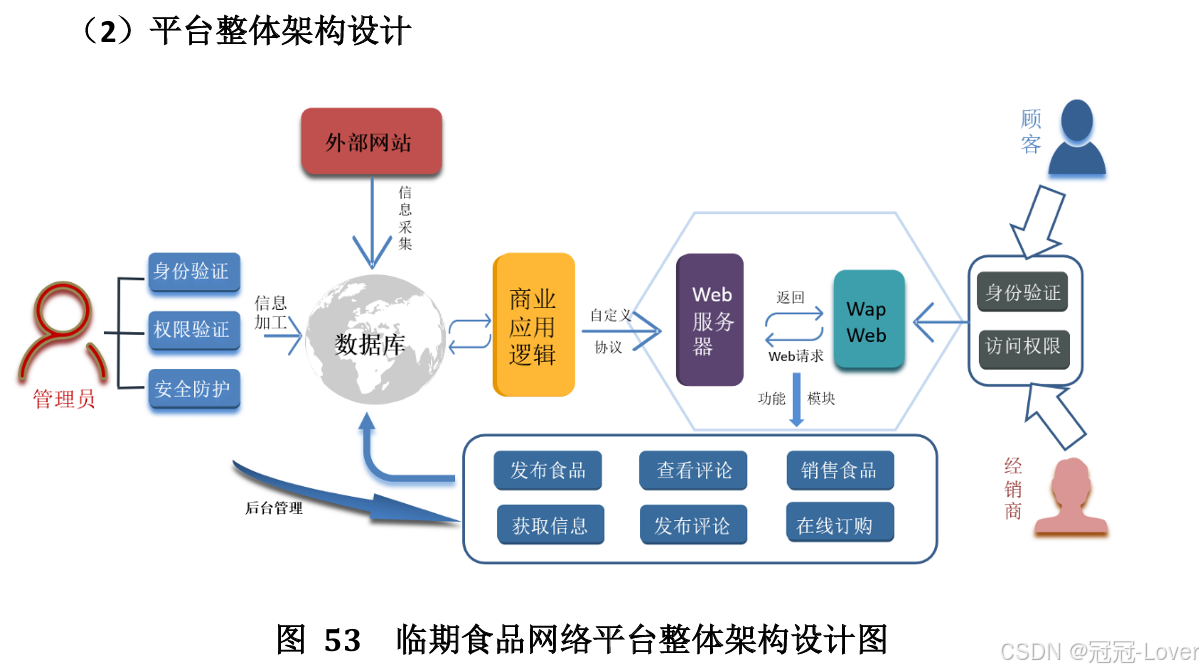
提出基于𝐸𝑅𝑃系统的临期食品销售管理平台
结论与建议
亮点
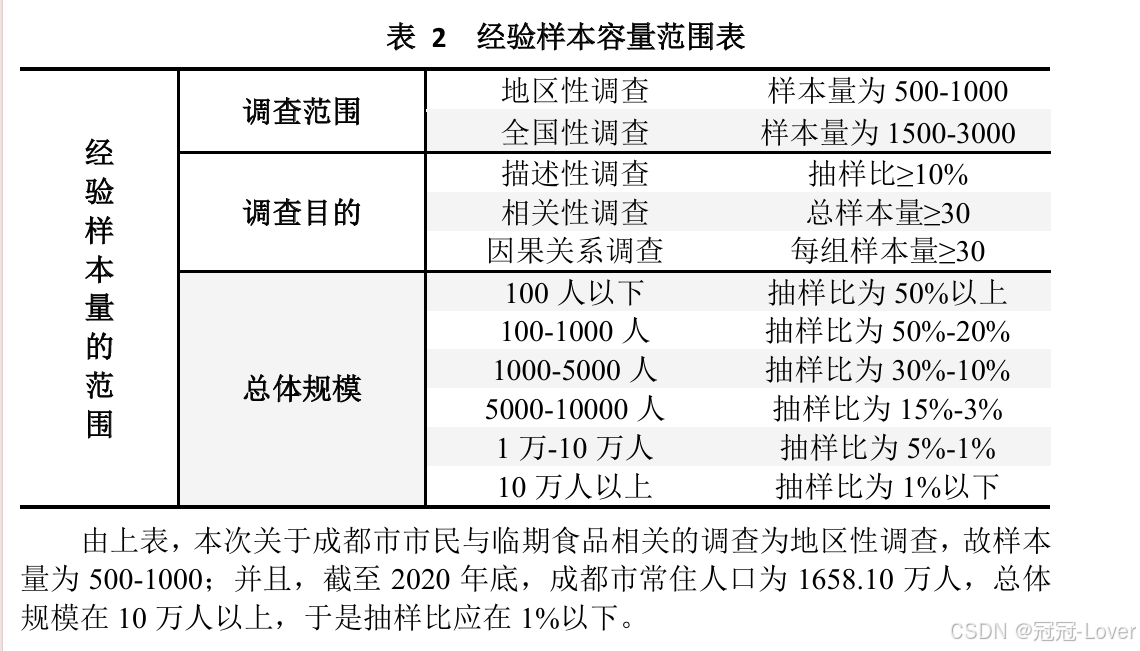

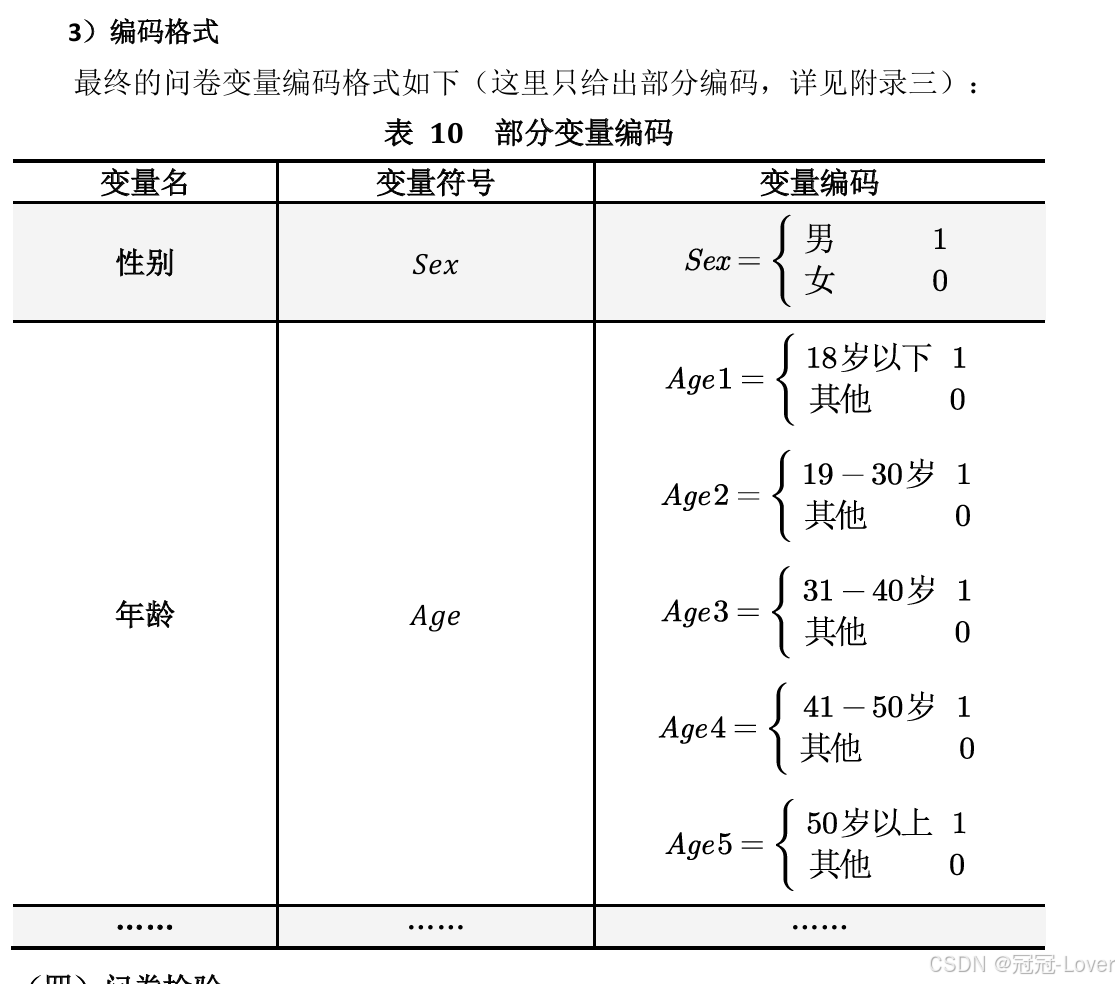
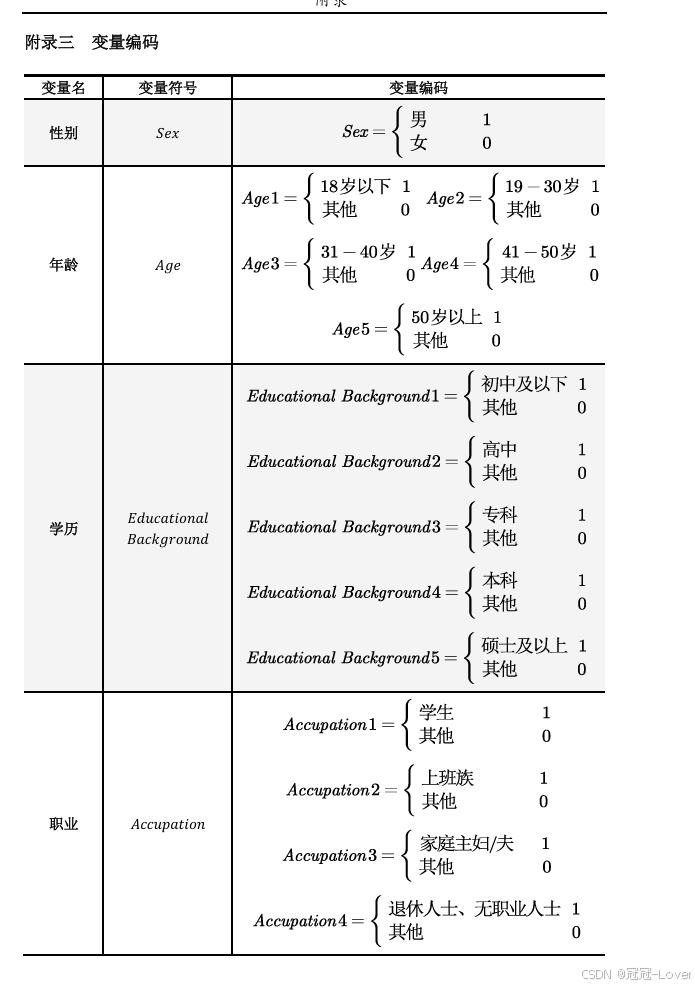
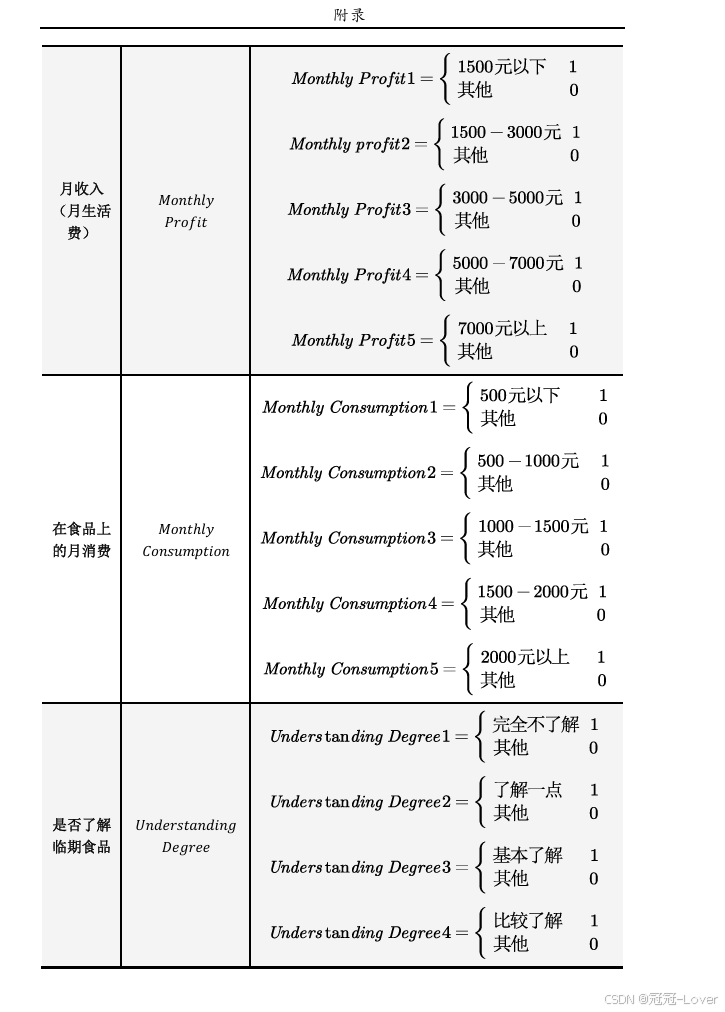

为什么要对这个做分析,应该有原因支撑

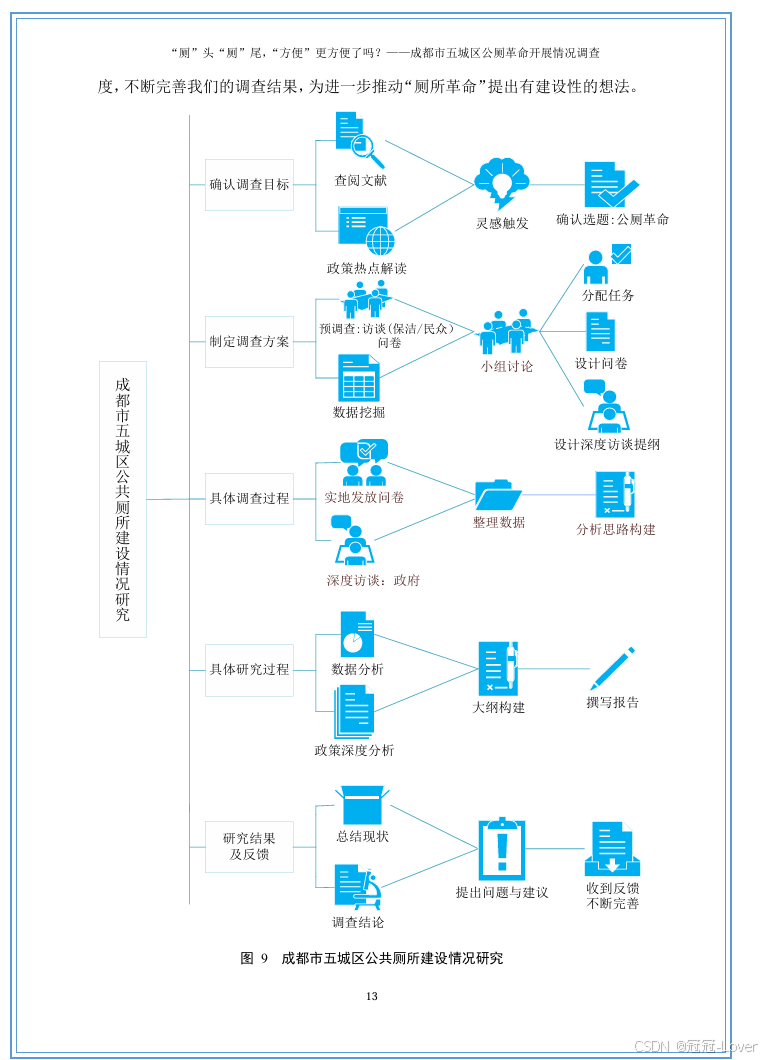
“厕”头“厕”尾 “方便”更方便了吗?

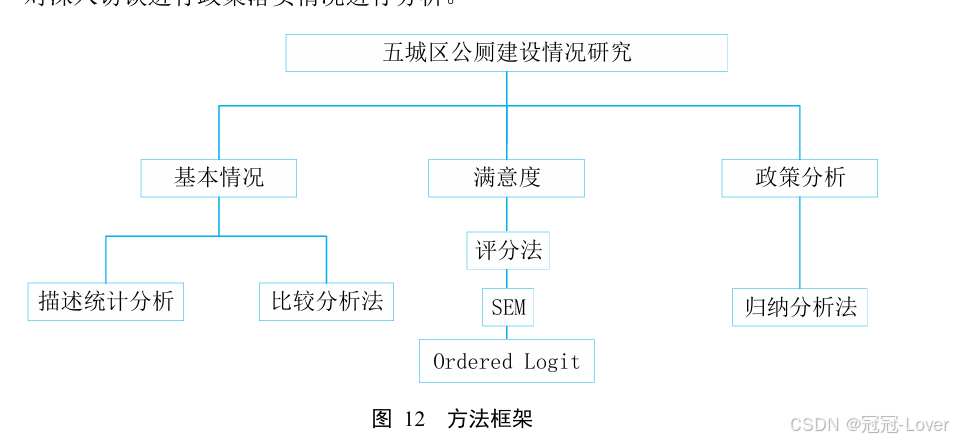
Ordered Logit是一种处理定序变量数据常用的一种方法,通过对被解释变量整体满意度采用定序变量赋值方法,来探究分级指标(洁手设施、水洁设备、卫生情况、规划布局、厕所隔间配置)对总指标(总体满意度)的影响程度。











访谈记录非常的多,实地调查照片佐证也非常的多,证据十分充足,这个应该是拿国一的很大的原因。
虽骂但买,超前点播成常态?----关于大学生对超前点播的态度及需求的调查
研究方法赞同都评价指标测量维度表修正
信效度检验
非抽样误差控制
结构方程
灰色关联分析
RFM模型【大学生群体点播价值的分析,RFM,LRFMC,Kmeans聚类】
这RFM是一个基于消费的评估模型,本文在RFM上创新,增加了LRFMC增加了L和C两项进行研究,但未详细说明。

重点是大学生对超前点播的支持和分享(share)分为了五个维度
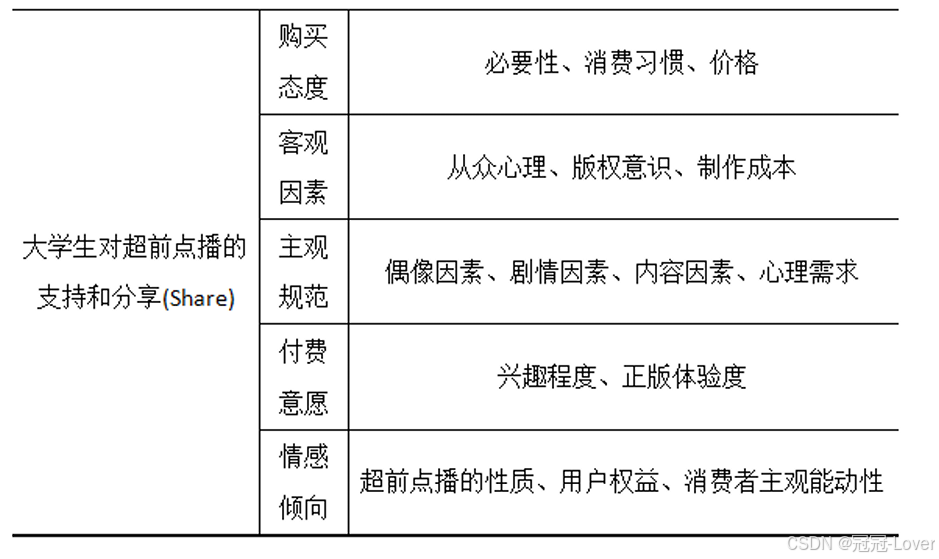

看完这篇我也觉得这篇放到现在只是篇省二的论文。
茶馆相遇妙,沧海一声笑----相声观众偏好分析与付费意愿调查
问卷收集1600份
数据分为了相声观众的基本信息、观众对待相声的认知和偏好情况、观众对待相声的行为特征、 已付费观看相声的观众态度以及观众对相声发展的前景展望五个方面
词云统计
情感词典
多元有序Logistic回归
Kmeans聚类【对受访的相声观众进行人群划分,分为三类】
Text-CNN模型【由填空题得到特征文本然后选出词频最高的30个词利用相关性建立模型,将主题分为3类】
随机森林【研究各类要素对观众喜爱相声程度的影响并进行重要性排序】
基于结构方程模型【潜变量与可测变量--研究影响观众对相声付费意愿的因素】
贝叶斯决策模型,从观众对相声的喜爱、了解和满意程度出发,探究出三个结论
层次分析法,将影响观众选择相声团体的因素分为服务价值和服务产品两类。
云模型【付费观看表演前对各方面的期待值作为指标权重,求出权重系数】【算满意度】
SWOT分析S优势W劣势O机会T威胁
信效度检验

这里也是说明了这个描述性统计的统计量背后的意义
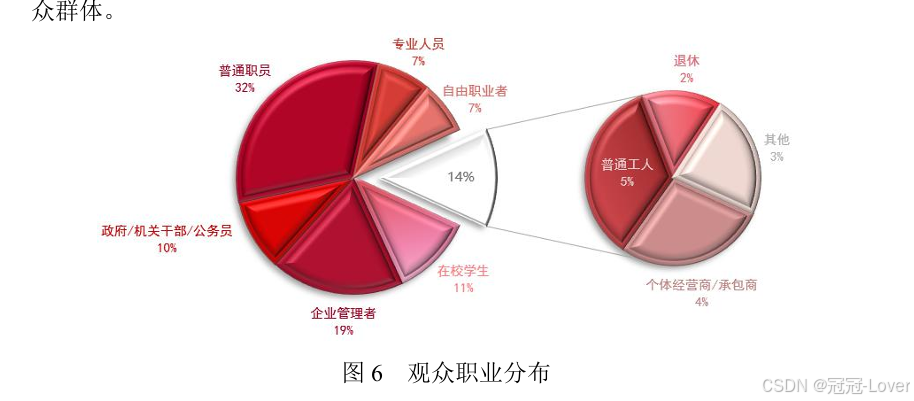
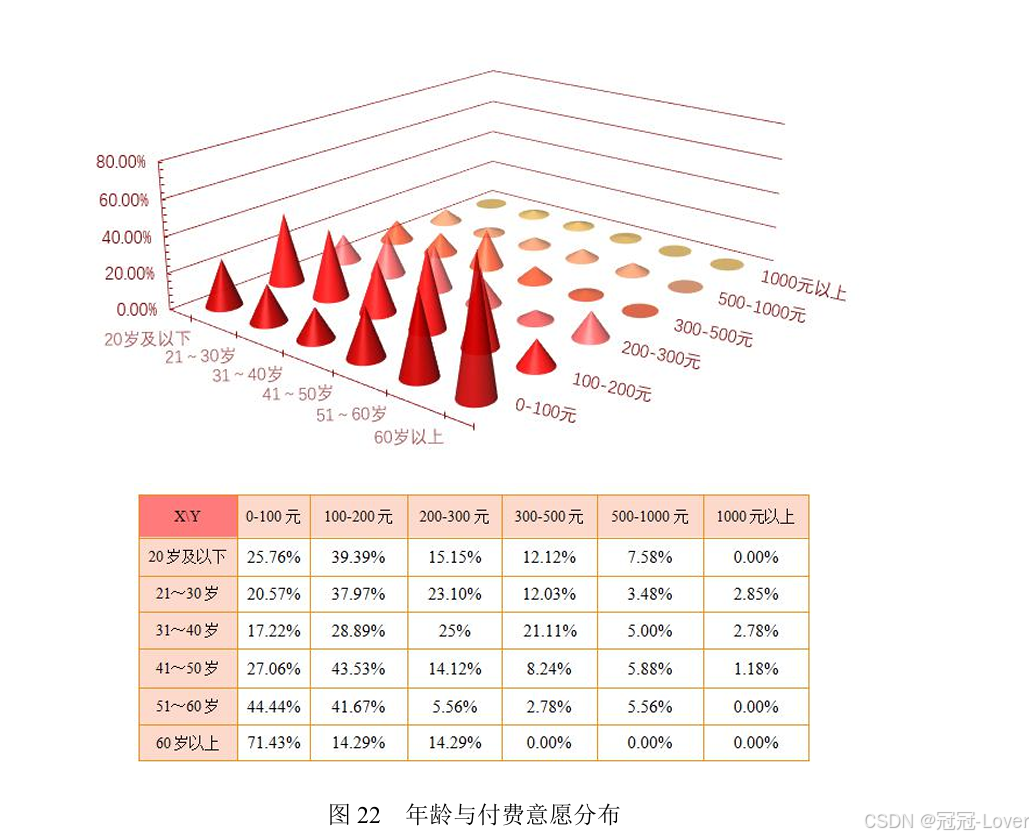
这种表格数据可以三维可视化



这份作品也有委托书
爱情三十六计----对大学开设恋爱课的探究与分析
问卷数据基本都是1000份起步,然后这个有两轮问卷,一个是856份一个是468份
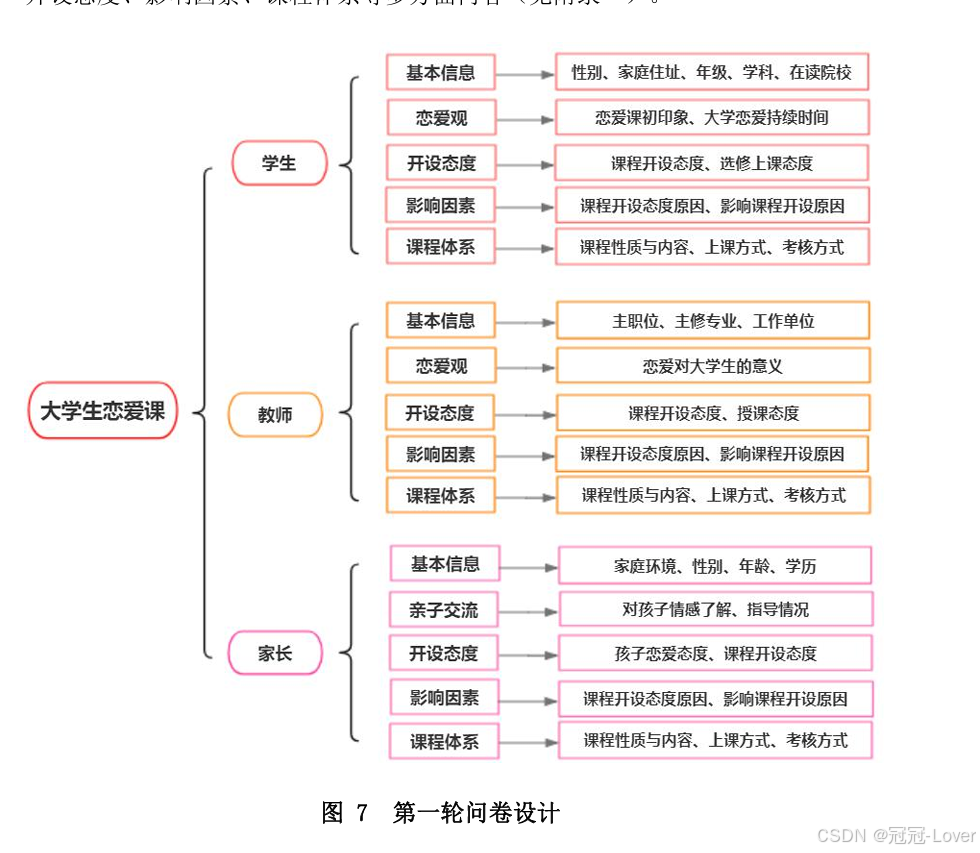
第一轮问卷针对学生、教师、 家长三个群体就大学生恋爱观、对于大学生恋爱课的态度、支持和影响恋爱课开 设的因素以及恋爱课开设内容和方式等展开研究,采用分层抽样和简单随机抽样 相结合的方法获取样本,结合高校师生比及各地区本科院校数,最终确定样本量 为856份,其中大学生467份,教师156份,家长233份。
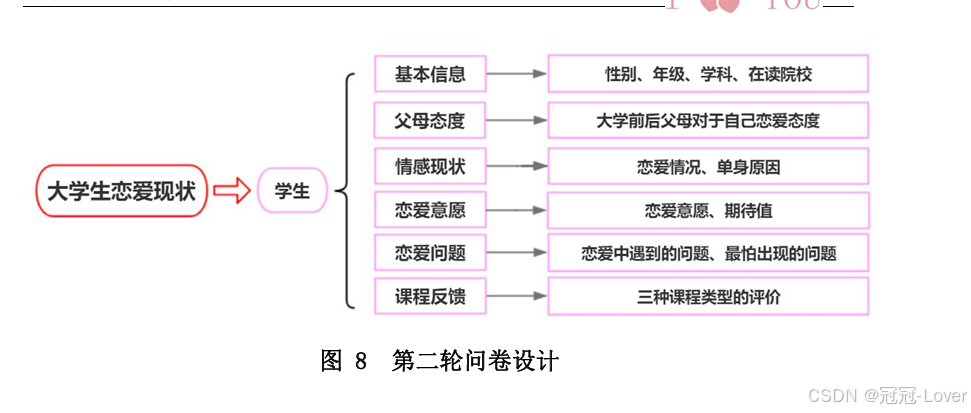
第二轮问卷主要就在 校大学生的情感现状、恋爱意愿和恋爱问题等展开研究,并设置相关题目对第一 轮研究结果和课程设计方案进行反馈调查,进一步补充完善调研内容;同时,为 提高样本回收效率,第二轮调查采用配额抽样,在第一轮分层抽样基础上根据性 别比和各地区人数最终确定样本量为468份

描述性分析 词云分析【各人群对恋爱课开设的态度】
logistics回归 列联分析 【研究影响恋爱课开设的原因】
因子分析法【对支持恋爱课开设的因素进行了归纳】数据降维,降噪提取出主要成分
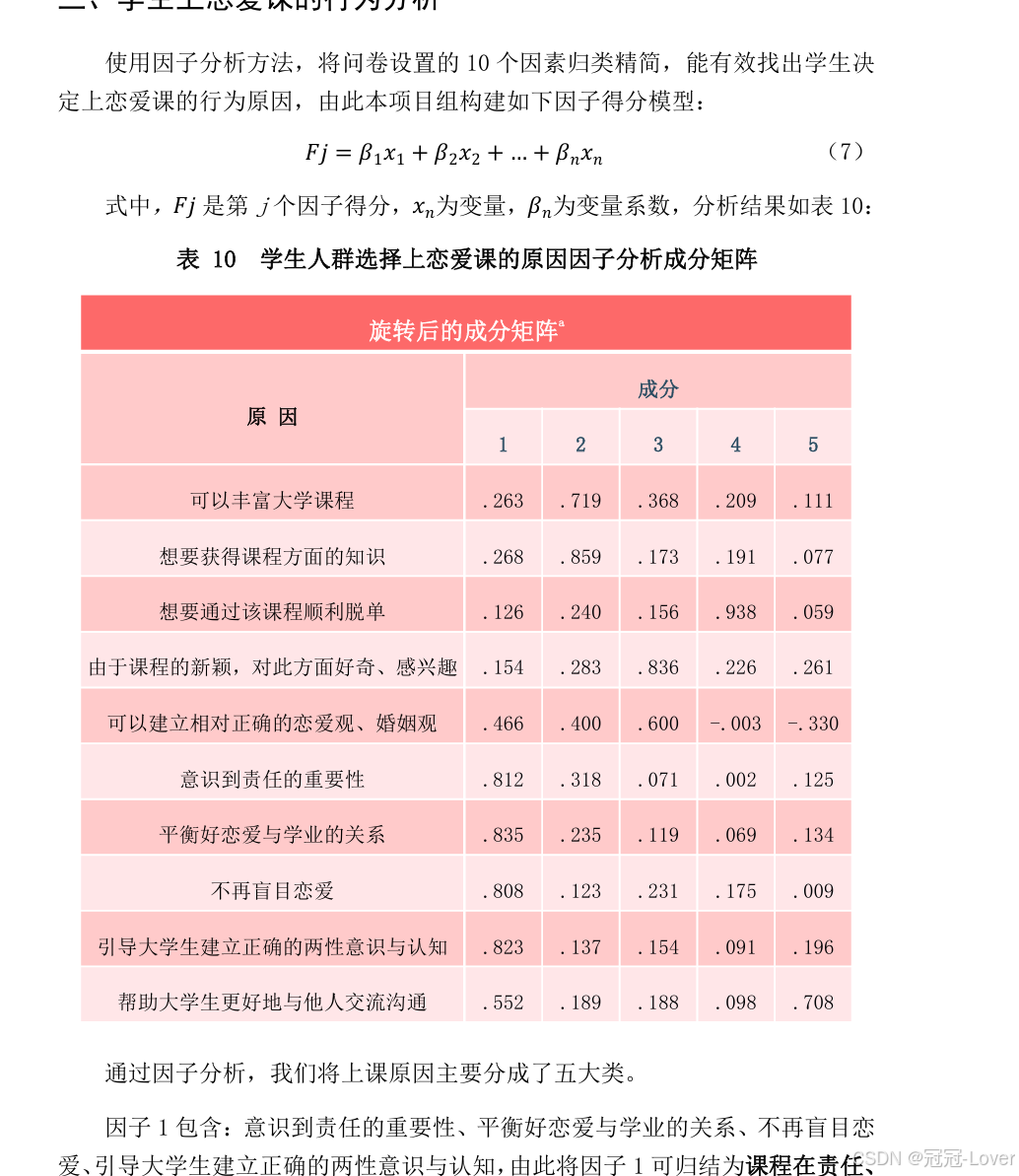
聚类模型Kmeans 深度访谈
随机检验与信效度检验

王婆卖瓜自卖自夸

然后文末也有比较多的照片当佐证

















 5484
5484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









