






distance库的distance.levenshtein( , )函数可以计算两句话之间的距离(错+漏+缺)
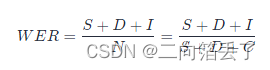
下面代码是对比语音识别结果和标准结果之间的错误率。每一行进行对比,输出结果为
输入文件格式为:spk##啊啊啊
import distance
import re
def spk_compare(compare_spk_list,cor_spk_list):
spk_compared_list=[]
for spk_num in range(len(xf_spk_list)):
if compare_spk_list[spk_num]==cor_spk_list[spk_num]:
spk_compared_list.append('1')
else:
spk_compared_list.append('0')
return spk_compared_list
def split_spk_content(list):
spk_list=[]
content_list=[]
for line in list:
if line=='\n':
spk='spk0'
content=''
else:
spk=(line.split('##'))[0]
#print(len(line.split('#')))
#print(line.split('#'))
content=re.sub('[^\u4e00-\u9fa5]+', '',(line.split('##'))[1])#删除非中文字符
spk_list.append(spk)
content_list.append(content)
return spk_list,content_list
def count_num(content_list):
num_word_list=[]
for line in content_list:
num_word_list.append(len(line))
# print(num_word_list)
return num_word_list
def cal_distance(cort_sentences_list,compare_sentences_list):
distance_list=[]
for num_list in range(len(cort_sentences_list)):
sentence_distance = distance.levenshtein(cort_sentences_list[num_list],compare_sentences_list[num_list])
distance_list.append(sentence_distance)
return distance_list
def x(content_list):
x_list=[]
flag='0'
for line in content_list:
for i in line:
if i=="x":
flag='1'
x_list.append(flag)
flag = '0'
return x_list
if __name__ == '__main__':
xunfei_txt = open('new.txt','r',encoding='utf-8')
correct_txt = open('correct.txt','r',encoding='utf-8')
xunfei_list=xunfei_txt.readlines()
correct_list=correct_txt.readlines()
x_list = x(correct_list)
xf_spk_list,xf_content_list=split_spk_content(xunfei_list)
cor_spk_list,cor_content_list=split_spk_content(correct_list)
spk_compared_list=spk_compare(xf_spk_list,cor_spk_list)
cor_num_word_list = count_num(cor_content_list)
xf_num_word_list = count_num(xf_content_list)
distance_list=cal_distance(xf_content_list,cor_content_list)
# print(distance_list)
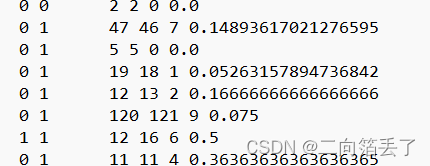
print("x? spk? 字数correct 字数pred dinstance cer")
for num in range(len(cor_spk_list)):
print(x_list[num],spk_compared_list[num]," ",cor_num_word_list[num],xf_num_word_list[num],distance_list[num],str(distance_list[num]/(cor_num_word_list[num])))
第一列x表示句子中是否有听不清的内容
第二列表示是否有说话者判断错,
第三四列为中文字符个数
第五列为错字数
distance/总字数=cer (可能大于100%)
注意:两个文档必须行行对应

















 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











