






 本文展示了一个使用Python调用讯飞语音转写API的示例,特别强调了如何添加角色分离参数(roleType和roleNum)以处理双人对话。代码中包含了请求签名的生成过程,并通过requests库进行POST请求,最后将结果保存为JSON文件。
本文展示了一个使用Python调用讯飞语音转写API的示例,特别强调了如何添加角色分离参数(roleType和roleNum)以处理双人对话。代码中包含了请求签名的生成过程,并通过requests库进行POST请求,最后将结果保存为JSON文件。
讯飞给的语音转写demo没有添加角色分离的参数

双人对话,取roleType=1 roleNum=2,添加在upload函数中param_dict
以下是添加了区分角色参数后改写的代码(包括json文件的保存)
# -*- coding: utf-8 -*-
import base64
import hashlib
import hmac
import json
import os
import time
import requests
import urllib
lfasr_host = 'https://raasr.xfyun.cn/v2/api'
# 请求的接口名
api_upload = '/upload'
api_get_result = '/getResult'
roleType=1
class RequestApi(object):
def __init__(self, appid, secret_key, upload_file_path):
self.appid = appid
self.secret_key = secret_key
self.upload_file_path = upload_file_path
self.ts = str(int(time.time()))
self.signa = self.get_signa()
def get_signa(self):
appid = self.appid
secret_key = self.secret_key
m2 = hashlib.md5()
m2.update((appid + self.ts).encode('utf-8'))
md5 = m2.hexdigest()
md5 = bytes(md5, encoding='utf-8')
# 以secret_key为key, 上面的md5为msg, 使用hashlib.sha1加密结果为signa
signa = hmac.new(secret_key.encode('utf-8'), md5, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
return signa
def upload(self):
print("上传部分:")
upload_file_path = self.upload_file_path
file_len = os.path.getsize(upload_file_path)
file_name = os.path.basename(upload_file_path)
param_dict = {}
param_dict['appId'] = self.appid
param_dict['signa'] = self.signa
param_dict['ts'] = self.ts
param_dict["fileSize"] = file_len
param_dict["fileName"] = file_name
param_dict["duration"] = "200"
param_dict["roleNum"] = 2
param_dict["roleType"] = 1
print("upload参数:", param_dict)
data = open(upload_file_path, 'rb').read(file_len)
response = requests.post(url =lfasr_host + api_upload+"?"+urllib.parse.urlencode(param_dict),
headers = {"Content-type":"application/json"},data=data)
print("upload_url:",response.request.url)
result = json.loads(response.text)
print("upload resp:", result)
return result
def get_result(self):
uploadresp = self.upload()
orderId = uploadresp['content']['orderId']
param_dict = {}
param_dict['appId'] = self.appid
param_dict['signa'] = self.signa
param_dict['ts'] = self.ts
param_dict['orderId'] = orderId
param_dict['resultType'] = "transfer,predict"
print("")
print("查询部分:")
print("get result参数:", param_dict)
status = 3
# 建议使用回调的方式查询结果,查询接口有请求频率限制
while status == 3:
response = requests.post(url=lfasr_host + api_get_result + "?" + urllib.parse.urlencode(param_dict),
headers={"Content-type": "application/json"})
# print("get_result_url:",response.request.url)
result = json.loads(response.text)
print(result)
status = result['content']['orderInfo']['status']
print("status=",status)
if status == 4:
break
time.sleep(5)
print("get_result resp:",result)
return result
# 输入讯飞开放平台的appid,secret_key和待转写的文件路径
if __name__ == '__main__':
api = RequestApi(appid="xxxx",
secret_key="xxxx",
upload_file_path=r"xxxxxxxx.wav")
result = api.get_result()
json.dump(result, open('result.json', 'w'), ensure_ascii=False)
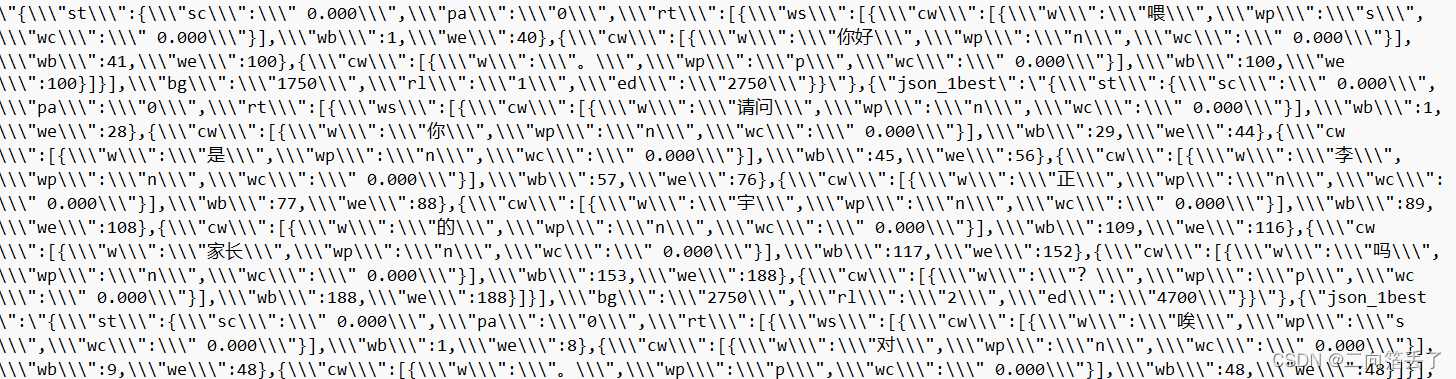
出来的结果是这样的,多层嵌套,找到规律一层一层解开就行了
具体提取方法见本人另一篇文章【python讯飞开放平台语音转写API json内容提取 - CSDN App】



















 2796
2796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











