






一.Encoder部分
相机特征提取:
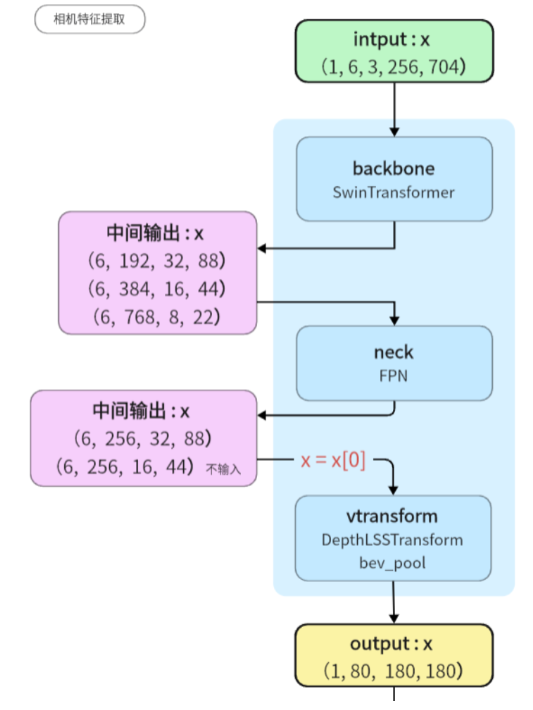
DepthLSSTransform bevfusion-main\mmdet3d\models\vtransforms\depth_lss.py
class DepthLSSTransform(BaseDepthTransform):
def __init__(
self,
in_channels: int,#输入通道数
out_channels: int,#输出通道数
image_size: Tuple[int, int],#图像大小
feature_size: Tuple[int, int],#特征大小
xbound: Tuple[float, float, float],#X轴范围
ybound: Tuple[float, float, float],#Y轴范围
zbound: Tuple[float, float, float],#Z轴范围
dbound: Tuple[float, float, float],#D轴范围
downsample: int = 1,#下采样因子
) -> None:
super().__init__(
in_channels=in_channels,
out_channels=out_channels,
image_size=image_size,
feature_size=feature_size,
xbound=xbound,
ybound=ybound,
zbound=zbound,
dbound=dbound,
)
self.dtransform = nn.Sequential(
nn.Conv2d(1, 8, 1),#输入通道数为 1,输出通道数为 8 的 1x1 卷积层
nn.BatchNorm2d(8),#对于输出通道为 8 的卷积层进行批归一化
nn.ReLU(True),
nn.Conv2d(8, 32, 5, stride=4, padding=2),##输入通道数为 8,输出通道数为 32 的 5x5 卷积层,步长为 4,填充为 2
nn.BatchNorm2d(32),#对于输出通道为32的卷积层进行批归一化
nn.ReLU(True),
nn.Conv2d(32, 64, 5, stride=2, padding=2),##输入通道数为32,输出通道数为 64 的 5x5 卷积层,步长为 2,填充为 2
nn.BatchNorm2d(64),##对于输出通道为64的卷积层进行批归一化
nn.ReLU(True),
)
self.depthnet = nn.Sequential(
nn.Conv2d(in_channels + 64, in_channels, 3, padding=1),#输入通道数为 in_channels + 64,输出通道数为 in_channels 的 3x3 卷积层,填充为 1。
nn.BatchNorm2d(in_channels),#对于输出通道数为 in_channels 的卷积层进行批归一化。
nn.ReLU(True),
nn.Conv2d(in_channels, in_channels, 3, padding=1),
nn.BatchNorm2d(in_channels),
nn.ReLU(True),
nn.Conv2d(in_channels, self.D + self.C, 1),
)
if downsample > 1:
assert downsample == 2, downsample
self.downsample = nn.Sequential(
nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True),
nn.Conv2d(
out_channels,
out_channels,
3,
stride=downsample,
padding=1,
bias=False,#没有偏置顶
),
nn.BatchNorm2d(out_channels),
nn.ReLU(True),
nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(True),
)
else:
self.downsample = nn.Identity()get_cam_feats
def get_cam_feats(self, x, d):
B, N, C, fH, fW = x.shape#批次大小为 B,样本数量为 N,通道数为 C,特征图高度为 fH,特征图宽度为 fW
d = d.view(B * N, *d.shape[2:])#重塑d视图
x = x.view(B * N, C, fH, fW)#重塑x视图
d = self.dtransform(d)#对 d 进行变换
x = torch.cat([d, x], dim=1)#拼接
x = self.depthnet(x)#输入到 self.depthnet 网络
depth = x[:, : self.D].softmax(dim=1)
#目的是对 x 张量中的深度信息进行 softmax 归一化,以获得表示深度概率的张量 depth。
x = depth.unsqueeze(1) * x[:, self.D : (self.D + self.C)].unsqueeze(2)
#将 depth 张量的维度从 (B * N, self.D) 变为 (B * N, 1, self.D),在新添加的
#维度上进行扩展。这样做是为了与 x 的形状匹配,以便进行元素级乘法运算。
x = x.view(B, N, self.C, self.D, fH, fW)
x = x.permute(0, 1, 3, 4, 5, 2)#维度重新排序
return x雷达特征提取:
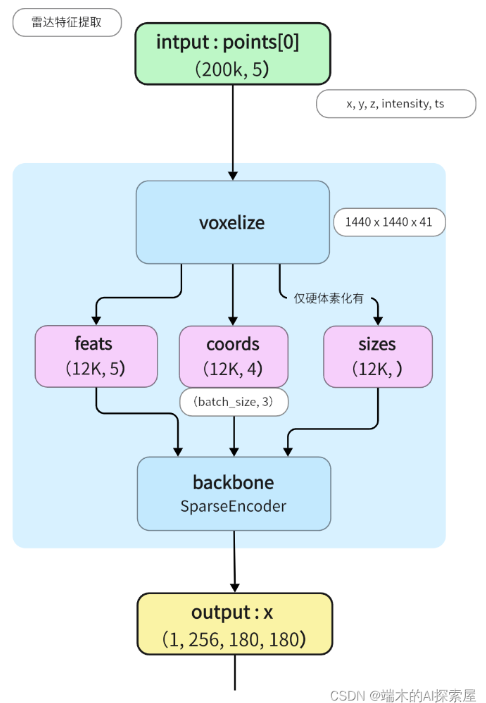
SparseEncoder bevfusion-main\mmdet3d\models\backbones\sparse_encoder.py
class SparseEncoder(nn.Module):
def __init__(
self,
in_channels,#输入通道数
sparse_shape,#稀疏张量的形状
order=("conv", "norm", "act"),#卷积模块顺序
norm_cfg=dict(type="BN1d", eps=1e-3, momentum=0.01),#规范化层的配置
base_channels=16,#conv_input层的输出通道数
output_channels=128,#conv_out层的输出通道数
encoder_channels=((16,), (32, 32, 32), (64, 64, 64), (64, 64, 64)),#每个编码块的卷积通道数
encoder_paddings=((1,), (1, 1, 1), (1, 1, 1), ((0, 1, 1), 1, 1)),#每个编码块的填充数
block_type="conv_module",#块类型
):
super().__init__()
assert block_type in ["conv_module", "basicblock"]
self.sparse_shape = sparse_shape
self.in_channels = in_channels
self.order = order
self.base_channels = base_channels
self.output_channels = output_channels
self.encoder_channels = encoder_channels
self.encoder_paddings = encoder_paddings
self.stage_num = len(self.encoder_channels)
self.fp16_enabled = Falseforward
def forward(self, voxel_features, coors, batch_size, **kwargs):
coors = coors.int()#体素坐标转为整数类型
input_sp_tensor = spconv.SparseConvTensor(
voxel_features, coors, self.sparse_shape, batch_size
)#spconv.SparseConvTensor创建一个稀疏卷积张量 input_sp_tensor
x = self.conv_input(input_sp_tensor)
#作为输入传递给输入层的卷积模块self.conv_input
encode_features = []
for encoder_layer in self.encoder_layers:
x = encoder_layer(x)#给每个编码器层
encode_features.append(x)#x传入encode_features
out = self.conv_out(encode_features[-1])#编码器最后一层的输出特征encode_features[-1]作为输入传递给输出层的卷积模块self.conv_out,得到输出特征out
spatial_features = out.dense()#输出特征out转换为密集张量形式
N, C, H, W, D = spatial_features.shape
spatial_features = spatial_features.permute(0, 1, 4, 2, 3).contiguous()
#permute对spatial_features 进行维度的重排。#contiguous()使得 spatial_features 的内存布局连续化
spatial_features = spatial_features.view(N, C * D, H, W)
#spatial_features 重排为新的形状,N 表示批次大小,C * D 表示新的通道数(将深度维度展开到通道维度),H 表示高度,W 表示宽度
return spatial_features二.Fuser部分
两个bev特征(相机特征和雷达特征)融合部分
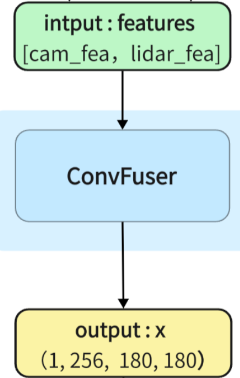
ConvFuser代码的部分:bevfusion-main\mmdet3d\models\fusers\conv.py
class ConvFuser(nn.Sequential):#表示 ConvFuser 类继承自 nn.Sequential 类,从而继承了 nn.Sequential 类的属性和方法。
def __init__(self, in_channels: int, out_channels: int) -> None:
self.in_channels = in_channels
self.out_channels = out_channels
super().__init__(
nn.Conv2d(sum(in_channels), out_channels, 3, padding=1, bias=False),
#一个二维卷积层对象,#没有偏置顶
nn.BatchNorm2d(out_channels),#二维批归一化层对象
nn.ReLU(True),#一个 ReLU 激活函数的对象
)
def forward(self, inputs: List[torch.Tensor]) -> torch.Tensor:
return super().forward(torch.cat(inputs, dim=1))
#torch.cat(inputs, dim=1) 表示将输入列表中的张量按照维度1进行拼接。三.Decoder
提取融合后的bev特征
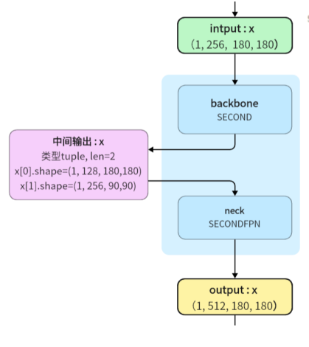
Backbone部分的 SECOND代码的部分: bevfusion-main\mmdet3d\models\backbones\second.py
class SECOND(BaseModule):
def __init__(
self,
in_channels=128,
out_channels=[128, 128, 256],
layer_nums=[3, 5, 5],#表示每个层的重复次数,每个阶段中的层数列表
layer_strides=[2, 2, 2],#一个包含三个元素的列表,表示每个层的步长。
norm_cfg=dict(type="BN", eps=1e-3, momentum=0.01),
#BN:表示归一化层的类型为批归一化(Batch Normalization)
#epsilon=1e-3,用于防止除以零的情况
#momentum用于计算每个小批量数据的均值和方差的移动平均值。
conv_cfg=dict(type="Conv2d", bias=False),
#卷积层的类型为二维卷积(Conv2d),bias表示卷积层不使用偏置项
init_cfg=None,#不进行模型初始化配置
pretrained=None,#表示不加载预训练权重的配置
):
super().__init__(init_cfg=init_cfg)
assert len(layer_strides) == len(layer_nums)
#确保 layer_strides 和 layer_nums 的长度相等,否则出现AssertionError异常
assert len(out_channels) == len(layer_nums)
#确保 layer_nums 和 out_channels 的长度相等,否则出现AssertionError异常
in_filters = [in_channels, *out_channels[:-1]]
#用于创建一个列表in_filters,包含输入通道数和out_channels除了列表中最后一个元素之外的所有元素
blocks = []
for i, layer_num in enumerate(layer_nums):
block = [
build_conv_layer(
conv_cfg,#指定卷积层的类型和参数
in_filters[i],#卷积层的输入通道数
out_channels[i],#卷积层的输出通道数
3,#卷积核大小
stride=layer_strides[i],#表示卷积操作的步长
padding=1,#填充大小
),
build_norm_layer(norm_cfg, out_channels[i])[1],
#norm_cfg:归一化层的类型和参数,out_channels[i]输出通道数,
#表示归一化层的输入通道数
nn.ReLU(inplace=True),
#PyTorch 中的 ReLU 激活函数的类,并指定在原地进行操作
]
for j in range(layer_num):
block.append(
build_conv_layer(
conv_cfg, out_channels[i], out_channels[i], 3, padding=1
)#conv_cfg:卷积层的类型和参数 out_channels:输出通道数 3: 卷积核大小 padding:1像素的填充
)
block.append(build_norm_layer(norm_cfg, out_channels[i])[1])
#norm_cfg:归一化层的类型和参数,out_channels[i]输出通道数的结果的第二个元素
block.append(nn.ReLU(inplace=True))
block = nn.Sequential(*block)
#用于将多个层按顺序组合在一起。星号 * 在这里的作用是将列表 block 展开,将其中的元素作为参数传递给 nn.Sequential。
blocks.append(block)
self.blocks = nn.ModuleList(blocks)
#初始化方式和预训练权重只能选择一个进行设置
assert not (
init_cfg and pretrained
), "init_cfg and pretrained cannot be setting at the same time"
if isinstance(pretrained, str):
warnings.warn(
"DeprecationWarning: pretrained is a deprecated, "
'please use "init_cfg" instead'
)
self.init_cfg = dict(type="Pretrained", checkpoint=pretrained)
#这表示所使用的初始化方式为预训练权重
else:
self.init_cfg = dict(type="Kaiming", layer="Conv2d")
#指定了 Kaiming 初始化方法适用于卷积层
def forward(self, x):
outs = []
for i in range(len(self.blocks)):
x = self.blocks[i](x)
#输入x通过第i个卷积块self.blocks[i](x)进行向前传播
outs.append(x)
return tuple(outs)
Backbone部分的 SECONDFPN 代码部分:bevfusion-main\mmdet3d\models\necks\second.py
class SECONDFPN(BaseModule):
def __init__(
self,
in_channels=[128, 128, 256],#输入通道数的列表
out_channels=[256, 256, 256],#输出通道数的列表
upsample_strides=[1, 2, 4],#上采样步幅的列表
norm_cfg=dict(type="BN", eps=1e-3, momentum=0.01),#归一化层的配置字典
upsample_cfg=dict(type="deconv", bias=False),
#上采样层的配置字典,定义了上采样层的类型(反卷积)以及相应的参数设置
conv_cfg=dict(type="Conv2d", bias=False),
#卷积层的配置字典,定义了卷积层的类型(2D卷积)以及相应的参数设置
use_conv_for_no_stride=False,
#是否使用卷积层代替步幅为 1 的上采样
init_cfg=None,#模型初始化的配置字典
):
super(SECONDFPN, self).__init__(init_cfg=init_cfg)
assert len(out_channels) == len(upsample_strides) == len(in_channels)
self.in_channels = in_channels
self.out_channels = out_channels
self.fp16_enabled = False
deblocks = []
for i, out_channel in enumerate(out_channels):
stride = upsample_strides[i]
#upsample_strides是一个列表,存储了每个卷积块中上采样操作的步幅。
if stride > 1 or (stride == 1 and not use_conv_for_no_stride):
upsample_layer = build_upsample_layer(
upsample_cfg,#上采样层的配置字典
in_channels=in_channels[i],#输入通道数
out_channels=out_channel,#输出通道数
kernel_size=upsample_strides[i],#上采样层的卷积核大小
stride=upsample_strides[i],#上采样层的步幅大小
)
else:
stride = np.round(1 / stride).astype(np.int64)#四舍五入取浮点数,将结果转换为整数类型
upsample_layer = build_conv_layer(
conv_cfg,#卷积层的配置字典
in_channels=in_channels[i],#卷积层的输入通道数
out_channels=out_channel,#卷积层的输出通道数
kernel_size=stride,#卷积核大小
stride=stride,
)
deblock = nn.Sequential(
upsample_layer,#上采样层对象
build_norm_layer(norm_cfg, out_channel)[1],#构建归一化层
nn.ReLU(inplace=True),#创建ReLU激活函数层对象
)
deblocks.append(deblock)
self.deblocks = nn.ModuleList(deblocks)
#nn.ModuleList 将列表 deblocks 转换为一个模块列表
if init_cfg is None:
self.init_cfg = [
dict(type="Kaiming", layer="ConvTranspose2d"),#初始化的层类型为 ConvTranspose2d(反卷积层)
dict(type="Constant", layer="NaiveSyncBatchNorm2d", val=1.0),#初始化的层类型为批归一化层
]四.Head部分
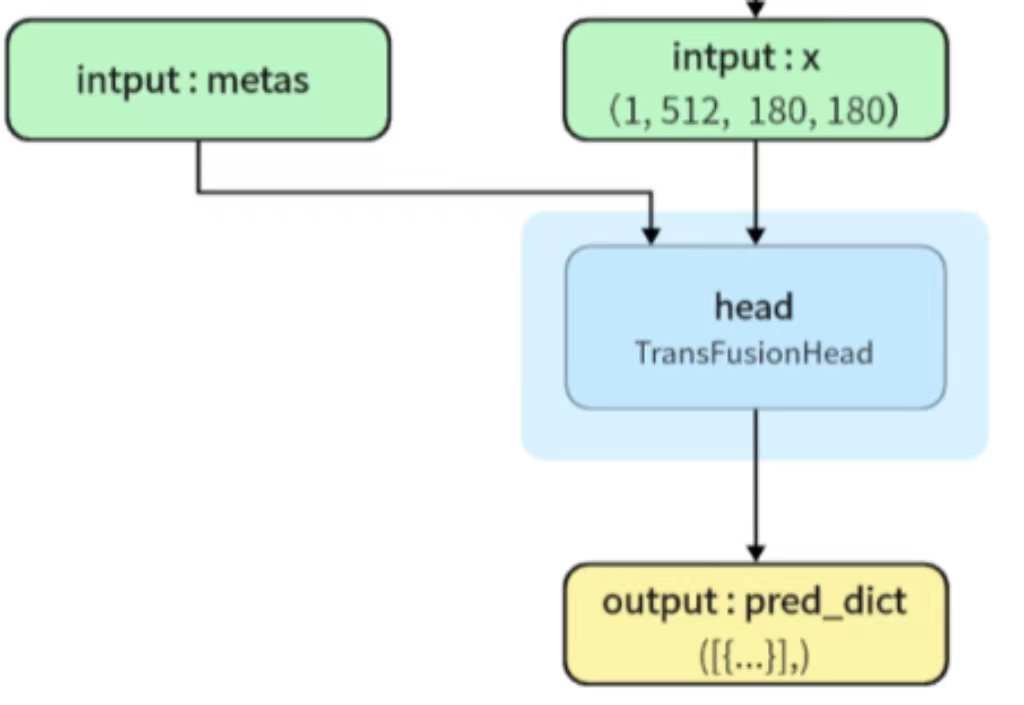
TransFusionHead 路径:bevfusion-main\mmdet3d\models\heads\bbox\transfusion.py
TransFusionhead类的定义
class TransFusionHead(nn.Module):
def __init__(
self,
num_proposals=128,#默认参数,指定了预测的边界框数量
auxiliary=True,#指定使用辅助损失
in_channels=128 * 3,#输入通道数
hidden_channel=128,#隐藏层的通道数
num_classes=4,#分类任务中的输出类别数
num_decoder_layers=3,#解码器数量,通常用于Transformer模型中
num_heads=8,#检测头数量,用于多头注意力机制中
nms_kernel_size=1,#非极大值抑制(NMS)的卷积核大小
ffn_channel=256,#前馈神经网络(FFN)的通道数
dropout=0.1,#Dropout层的丢弃率,用于正则化模型
bn_momentum=0.1,#批归一化层的动量
activation="relu",#指定激活函数的类型ReLU
# config for FFN
common_heads=dict(),#通用头部的配置参数
num_heatmap_convs=2,#检测头卷积层的数量
conv_cfg=dict(type="Conv1d"),#指定卷积层的配置参数
norm_cfg=dict(type="BN1d"),#指定归一化层的配置参数
bias="auto",#使用偏置项
# loss
loss_cls=dict(type="GaussianFocalLoss", reduction="mean"),#分类损失函数的配置参数
loss_iou=dict(
type="VarifocalLoss", use_sigmoid=True, iou_weighted=True, reduction="mean"
),#指定IoU损失函数的配置参数。
loss_bbox=dict(type="L1Loss", reduction="mean"),#指定边界框回归损失函数的配置参数。
loss_heatmap=dict(type="GaussianFocalLoss", reduction="mean"),#指定热图损失函数的配置参数
# others
train_cfg=None,#训练过程的配置参数
test_cfg=None,
bbox_coder=None,#边界框编码的对象
):
super(TransFusionHead, self).__init__()
self.fp16_enabled = False
self.num_classes = num_classes
self.num_proposals = num_proposals
self.auxiliary = auxiliary
self.in_channels = in_channels
self.num_heads = num_heads
self.num_decoder_layers = num_decoder_layers
self.bn_momentum = bn_momentum
self.nms_kernel_size = nms_kernel_size
self.train_cfg = train_cfg
self.test_cfg = test_cfgPrediction Head和Position Embedding
self.prediction_heads = nn.ModuleList()#创建一个空的nn.ModuleList对象
for i in range(self.num_decoder_layers):#迭代地创建多个预测头
heads = copy.deepcopy(common_heads)
#并将common_heads的内容深度复制给heads。
heads.update(dict(heatmap=(self.num_classes, num_heatmap_convs)))
#将一个名为heatmap的键值对添加到heads字典中
self.prediction_heads.append(
FFN(
hidden_channel,
heads,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
bias=bias,
)
)
self.init_weights()
self._init_assigner_sampler()
x_size = self.test_cfg["grid_size"][0] // self.test_cfg["out_size_factor"]
#测试配置中的网格大小的第一个维度
y_size = self.test_cfg["grid_size"][1] // self.test_cfg["out_size_factor"]
#测试配置中的网格大小的第二个维度
self.bev_pos = self.create_2D_grid(x_size, y_size)
#以 x_size 和 y_size 作为参数创建了一个二维网格。
self.img_feat_pos = None
self.img_feat_collapsed_pos = Noneimage to BEV
lidar_feat_flatten = lidar_feat.view(
batch_size, lidar_feat.shape[1], -1
)
# [BS, C, H*W]其中 batch_size 表示批量大小,C 表示通道数,H 和 W 表示高度和宽度。
#这行代码使用 view() 函数对 lidar_feat 进行形状变换,
#将高度和宽度的维度合并成一个维度,方便后续的计算。
bev_pos = self.bev_pos.repeat(batch_size, 1, 1).to(lidar_feat.device)
#通过 repeat() 函数,将 bev_pos 在batch(0) 维上重复 batch_size 次,与 LiDAR 特征的批量大小相匹配。
#使用 to() 方法将 bev_pos 移动到与 lidar_feat 相同的设备上(通常是 GPU 设备),以便在后续计算中进行统一操作image guided query initialization
dense_heatmap = self.heatmap_head(lidar_feat)
#用于生成热图的神经网络层或模块
dense_heatmap_img = None
heatmap = dense_heatmap.detach().sigmoid()
# 使用 detach() 方法将其从计算图中分离出来,然后应用 sigmoid() 函数对其
#进行激活,将其转换为概率密度形式的热图。
padding = self.nms_kernel_size // 2
#计算了一个变量 padding,它表示 NMS 中使用的填充大小。
local_max = torch.zeros_like(heatmap)
#一个与 heatmap 相同形状的零张量 local_max,用于表示局部最大值。transformer decoder layer (LiDAR feature as K,V)
ret_dicts = []
for i in range(self.num_decoder_layers):#表示解码器的层数
prefix = "last_" if (i == self.num_decoder_layers - 1) else f"{i}head_"
#根据当前层次的索引 i 来确定前缀。如果是最后一层,前缀设为 "last_";否则,前缀设为 i 加上 "head_"。
query_feat = self.decoder[i](
query_feat, lidar_feat_flatten, query_pos, bev_pos
)
#self.decoder[i]是Transformer解码器的第i层。处理的具体操作可能包括注意力机制、多头自注意力、前馈神经网络等。
res_layer = self.prediction_heads[i](query_feat)
#对query_feat进行预测操作,得到预测结果的字典res_layer。
res_layer["center"] = res_layer["center"] + query_pos.permute(0, 2, 1)
first_res_layer = res_layer
ret_dicts.append(res_layer)
#将res_layer添加到ret_dicts列表中,以便存储每一层的预测结果
query_pos = res_layer["center"].detach().clone().permute(0, 2, 1)
#detach()将张量从计算图中分离出来,使其成为一个独立的新张量,不再与原来的计算图关联。
#clone()创建res_layer["center"]的副本,并将其进行维度转置。
#.permute(0, 2, 1) 方法对张量的维度进行重新排列transformer decoder layer (img feature as K,V)
ret_dicts[0]["query_heatmap_score"] = heatmap.gather(
index=top_proposals_index[:, None, :].expand(-1, self.num_classes, -1),
dim=-1,
)
#heatmap.gather函数从heatmap中根据给定的索引进行收集,并将结果存储在ret_dicts[0]字典的键"query_heatmap_score"下。
ret_dicts[0]["dense_heatmap"] = dense_heatmap
#存储在ret_dicts[0]字典的键"dense_heatmap"
if self.auxiliary is False:
return [ret_dicts[-1]]
new_res = {}
for key in ret_dicts[0].keys():
if key not in ["dense_heatmap", "dense_heatmap_old", "query_heatmap_score"]:
new_res[key] = torch.cat(
[ret_dict[key] for ret_dict in ret_dicts], dim=-1
)#函数将多个张量按照最后一个维度(dim=-1)进行拼接。
else:
new_res[key] = ret_dicts[0][key]
#那么直接将ret_dicts[0]字典中的相应键key的值复制到new_res字典中的相应键key下。
return [new_res]
















 4570
4570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









