







一.总结
重点: 介绍了一个融合摄像头和激光雷达数据的框架,用于3D对象检测。其创新之处在于使摄像头流程不依赖激光雷达输入,解决了现有方法过度依赖激光雷达数据的局限性。
方法: BEVFusion框架使用两个独立流程来处理激光雷达和摄像头数据,然后在鸟瞰视图(BEV)层面进行融合。这种方法即使在激光雷达功能失常,或摄像头失常的情况下也保证了稳健性。
性能: 在nuScenes数据集上,BEVFusion在平均精度(mAP)方面相比现有方法如PointPillars和CenterPoint显示出显著的改进,证明了其在正常和鲁棒设置下的优越性。
二.以前的激光雷达的融合方案
(a).Point-level Fusion

将图像特征投影到原始点云上的点级融合机制,具体步骤:
(1).从点云中采样一些点,根据相机内参和外参矩阵,投影到图像中。
(2).点云投影到图像中,可以采样到图像特征,然后凭拼接回点云,这样图像的点云和图像特征都会拥有
(3).利用融合后的特征经过点云出处理模块去做3D检测
(b).Feature-level Fusion

将LiDAR 特征或建议分别投影到每个视图图像上以提取RGB信息的特征级融合机制,具体步骤:
(1).将图像模态特征和LiDAR模态特征(两种模态特征)通过内外参矩阵,进行一个拼接和投影,融合出一个完整特征。
(2).右边向左边发出Query的信息,表示查询的意思,输入它的点云,通过一个点云网络,找到他的初始位置,在初始位置上面进行一个上采样特征,采样后的结果,再拼接到原始点云(右边的)的特征上
(3).接着送入3D检测
两种办法的缺陷:
他们严重依赖于激光雷达点云,事实上,如果激光雷达的输入缺失,这些办法将不可避免的失败,这将阻碍这类算法在现实环境中的部署。
BevFusion的提出
BEvFusion是一个令人惊讶的简单而有效的融合框架,通过从激光雷达点云中分离相机分支,从根本上面克服了这个问题.
三.BevFusion的方案
1.框架介绍

第一步:Camera Stream
步骤一:首先将多视角图像使用2D骨干网来提取一个基础图像特征。
Image-view Encoder的目标是将输入图像编码为语义信息丰富的深度特征。它使用更具代表性的dual-swan-tiny作为主干网络。之后,我们在主干上使用标准的特征金字塔网络(Feature Pyramid Network,FPN)来利用多尺度分辨率的特征。为了更好地对齐这些特征,我们首先提出了一个简单的特征自适应模块(ADP)来细化上采样特征。
(1).FPN+ADF
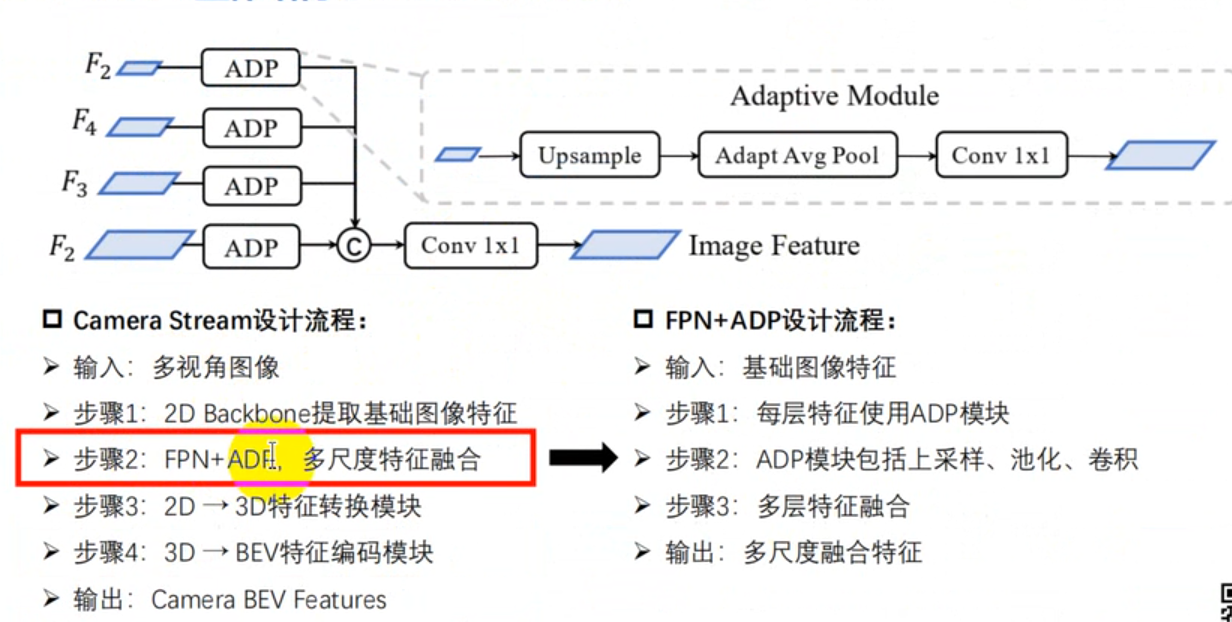
步骤二[图像编码]: 由于多尺度不能通过级联等方式融合,所以我们必须把他们尺寸变成一致。FPN(Feature Pyramid Networks) 像一个金字塔网络
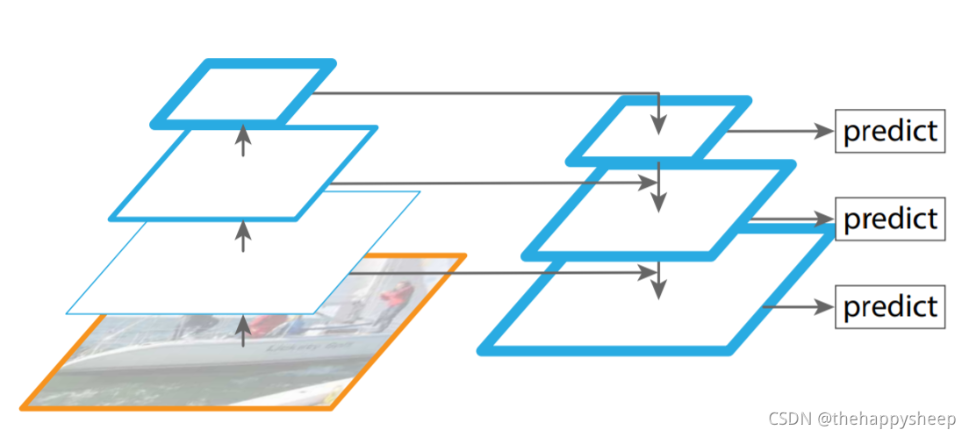
特征金字塔网络,使用一张图片,自下而上网络、自上而下网络、横向连接与卷积融合4个部分。

接下来使用ADP模块,进行上采样,池化和一个1x1的卷积。将尺寸变为一致。
步骤三[多尺度特征融合]:接下来进行一个多尺度特征融合,得到一个融合后的一个图象特征,它包含多尺寸特征信息。
(2).2D->3D特征转换

步骤一:就是对每个像素位置进行一个深度分布的预测,预测一系列离散的深度概率,深度概率就相当于a0,a1等等,作为一个权重概率再乘上图像特征feature c。
步骤二:乘上每个特征点后,从2D空间按照这个深度分布去做的这个深度转换映射,每个像素点按着射线去进行一个特征投影。把所有像素都投影完它就会组成我们所说的3D空间,所以就得到一个3D伪体素的特征(
![]()
)。
(3)BEV特征编码模块
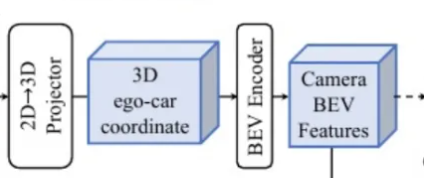
Bev encoder 模块是为了进一步将伪体素特征
![]()
编码为BEV空间特征
![]()
![]()
,我们并没有采用池化或者stride步长为2的3D卷积来叠加来压缩z维,而是采用了Spatial to Channel(S2C)操作,通过重塑将V(伪体素)从4D张量转换为3D张量,保留语义信息并且降低成本。然后,我们使用4个3x3卷积层,将通道维数逐渐降为
![]()
,最终可以提取到Camera BEV features。
第二步:Lidar Stream(从点云到BEV空间)

同样,我们的框架可以结合任何将LDAR点转换为BEV特征的网络,我们采用了三种3D特征提取网络,如PointPillars、CenterPoint和TransFusion作为我们的LiDAR流来展示我们框架的泛化能力。
第三步:Fusion Module
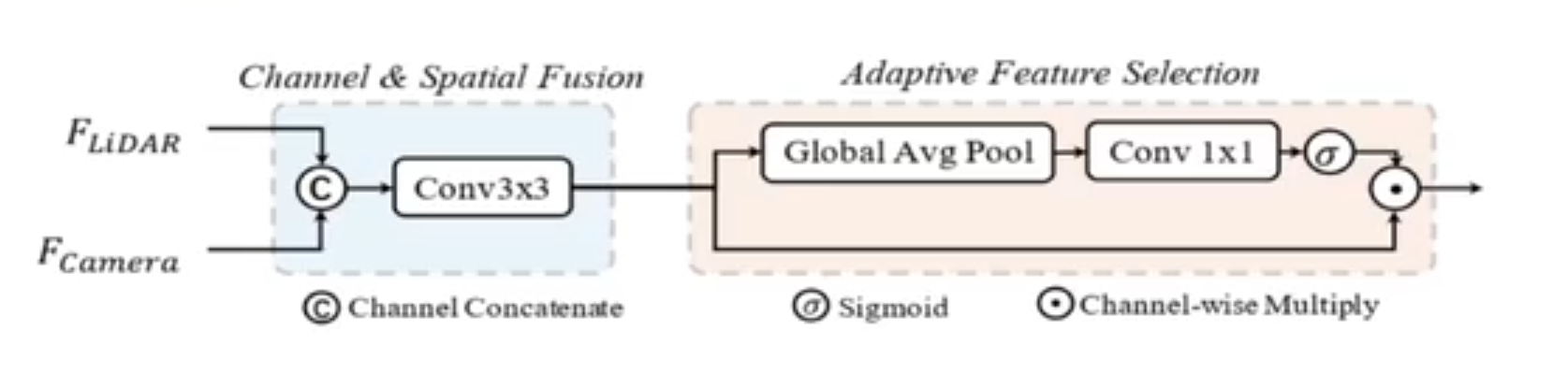
Fusion Module 设计流程:
输入:点云和图像BEV特征
步骤1:按通道维度进行一个级联点云和图像bev特征,在通过卷积网络(3x3)提取级联后的特征。
步骤2:接着通过AFS(Adaptive Feature Selection) (特征的自信选择),首先通过全局平均池化和卷积预测,实现对级联特征的自适应挑选,
![]()
这个是对权重的一个预测,
![]()
这个步骤是对点云特征和图像特征(通道特征)进行一个重新的加权。
步骤3:得到了点云和图像融合后的模块,之后就送入3d目标检测
















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









