






第1关:Concat与Append操作
编程要求
data.csv和data1.csv是两份与各国幸福指数排名相关的数据,为了便于查看排名详情,所以需要将两份数据横向合并。数据列名含义如下:
列名 说明
Country (region) 国家
Ladder 排名
SD of Ladder 排名的偏差
Positive affect 积极影响
Negative affect 消极影响
Social support 社会福利
Freedom 自由度
Corruption 腐败程度
Generosity 慷慨程度
Log of GDP per capita 人均GDP的对数
Healthy life expectancy 健康程度
读取step1/data.csv和step1/data1.csv两份数据;
首先将两个数据横向合并;
将索引设为排名(Ladder)列;
填充空值为0;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
####测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
Country (region) Freedom ... Negative affect Social support
Ladder …
1 Finland 5.0 … 10.0 2.0
2 Denmark 6.0 … 26.0 4.0
3 Norway 3.0 … 29.0 3.0
4 Iceland 7.0 … 3.0 1.0
5 Netherlands 19.0 … 25.0 15.0
6 Switzerland 11.0 … 21.0 13.0
7 Sweden 10.0 … 8.0 25.0
8 New Zealand 8.0 … 12.0 5.0
9 Canada 9.0 … 49.0 20.0
10 Austria 26.0 … 24.0 31.0
11 Australia 17.0 … 37.0 7.0
12 Costa Rica 16.0 … 87.0 42.0
13 Israel 93.0 … 69.0 38.0
14 Luxembourg 28.0 … 19.0 27.0
15 United Kingdom 63.0 … 42.0 9.0
16 Ireland 33.0 … 32.0 6.0
17 Germany 44.0 … 30.0 39.0
18 Belgium 53.0 … 53.0 22.0
19 United States 62.0 … 70.0 37.0
20 Czech Republic 58.0 … 22.0 24.0
21 United Arab Emirates 4.0 … 56.0 72.0
22 Malta 12.0 … 103.0 16.0
23 Mexico 71.0 … 40.0 67.0
24 France 69.0 … 66.0 32.0
25 Taiwan 102.0 … 1.0 48.0
26 Chile 98.0 … 78.0 58.0
27 Guatemala 25.0 … 85.0 78.0
28 Saudi Arabia 68.0 … 82.0 62.0
29 Qatar 0.0 … 0.0 0.0
30 Spain 95.0 … 107.0 26.0
… … … … … …
127 Congo (Kinshasa) 125.0 … 95.0 107.0
128 Mali 110.0 … 122.0 112.0
129 Sierra Leone 116.0 … 149.0 135.0
130 Sri Lanka 55.0 … 81.0 80.0
131 Myanmar 29.0 … 86.0 96.0
132 Chad 142.0 … 151.0 141.0
133 Ukraine 141.0 … 44.0 56.0
134 Ethiopia 106.0 … 74.0 119.0
135 Swaziland 113.0 … 57.0 103.0
136 Uganda 99.0 … 139.0 114.0
137 Egypt 129.0 … 124.0 118.0
138 Zambia 73.0 … 128.0 115.0
139 Togo 120.0 … 147.0 149.0
140 India 41.0 … 115.0 142.0
141 Liberia 94.0 … 146.0 127.0
142 Comoros 148.0 … 114.0 143.0
143 Madagascar 146.0 … 96.0 128.0
144 Lesotho 97.0 … 64.0 98.0
145 Burundi 135.0 … 126.0 152.0
146 Zimbabwe 96.0 … 34.0 110.0
147 Haiti 152.0 … 119.0 146.0
148 Botswana 60.0 … 65.0 105.0
149 Syria 153.0 … 155.0 154.0
150 Malawi 65.0 … 110.0 150.0
151 Yemen 147.0 … 75.0 100.0
152 Rwanda 21.0 … 102.0 144.0
153 Tanzania 78.0 … 50.0 131.0
154 Afghanistan 155.0 … 133.0 151.0
155 Central African Republic 133.0 … 153.0 155.0
156 South Sudan 154.0 … 152.0 148.0
[156 rows x 11 columns]
开始你的任务吧,祝你成功!
示例代码如下:
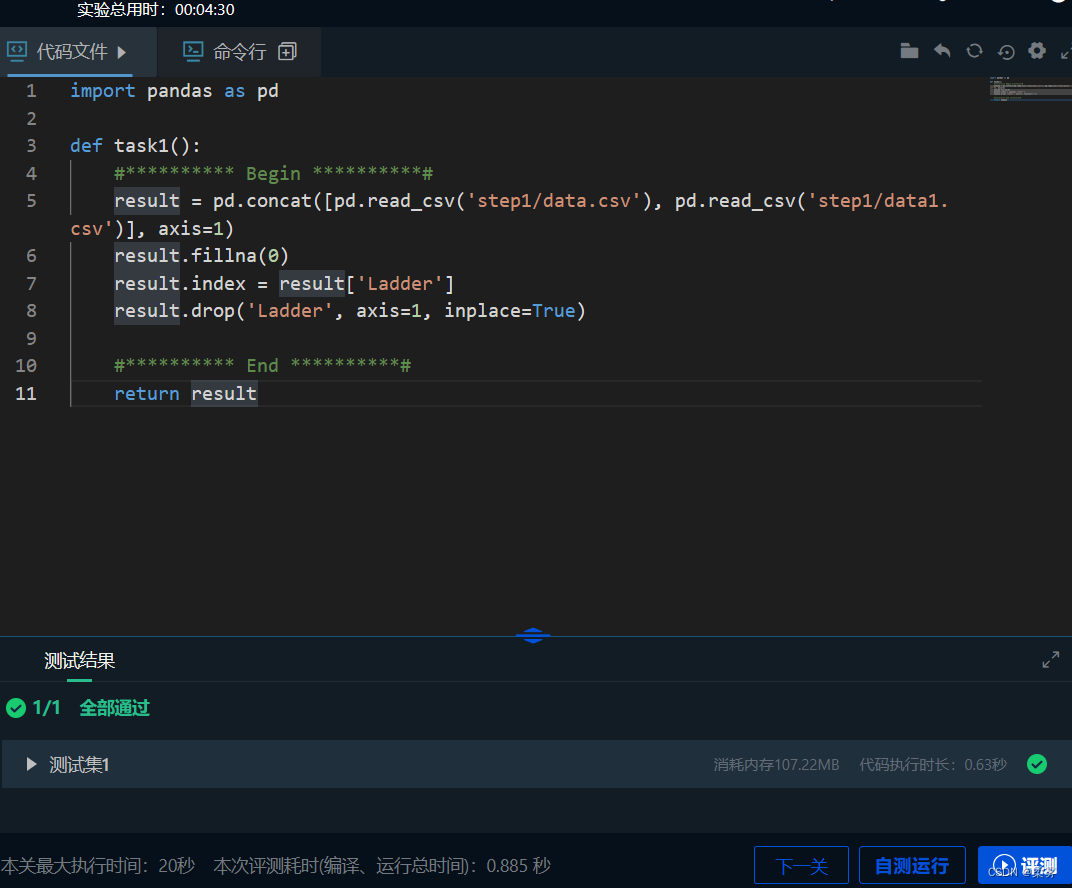
import pandas as pd
def task1():
#********** Begin **********#
result = pd.concat([pd.read_csv('step1/data.csv'), pd.read_csv('step1/data1.csv')], axis=1)
result.fillna(0)
result.index = result['Ladder']
result.drop('Ladder', axis=1, inplace=True)
#********** End **********#
return result
第2关:合并与连接
编程要求
在实际应用中,经常会遇到数据需要连接但是数据源不同的情况,如以下两个数据:
mysql中查询的数据;
[{‘city’: ‘BeiJing’, ‘user_id’: 1},
{‘city’: ‘NanJing’, ‘user_id’: 2},
{‘city’: ‘BeiJing’, ‘user_id’: 3},
{‘city’: ‘TianJin’, ‘user_id’: 4}]
mongodb中查询的数据;
[{‘page_click_count’: 20, ‘user_id’: 1},
{‘page_click_count’: 38, ‘user_id’: 2},
{‘page_click_count’: 10, ‘user_id’: 3}]
o\fracle中查询的数据;
c = [{‘id’: 4, “page_click_count”: 18, “city”: ‘TianJin’},
{‘id’: 5, “page_click_count”: 5, “city”: ‘BeiJing’},
{‘id’: 6, “page_click_count”: 25, “city”: ‘ShangHai’},
{‘id’: 7, “page_click_count”: 16, “city”: ‘GuangZhou’},
{‘id’: 8, “page_click_count”: 19, “city”: ‘ChangSha’},
{‘id’: 9, “page_click_count”: 50, “city”: ‘HangZhou’}]
我们需要分析不同城市的人对某个网页的点击次数,如果通过普通程序编写逻辑来实现肯定是可以做到的,但是当要连接的表超过十个,甚至百个时,这个方法就不好使了。这时使用pd.merge()来连接绝对是明智的选择。所以我们就来实践一下吧。
列名 说明
city 城市
user_id 用户id
id 用户id(同user_id,名字不同)
page_click_count 页面点击次数
将mysql、mongodb和o\fracle中的数据转换成DataFrame;
mysql:
mongodb:
o\fracle:
然后通过合并、连接、排序等操作,得到下图所示目标数组;
具体要求请参见后续测试样例。
提示:drop_duplicates()函数可以根据某一列来删除重复值。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
开始你的任务吧,祝你成功!
示例代码如下:
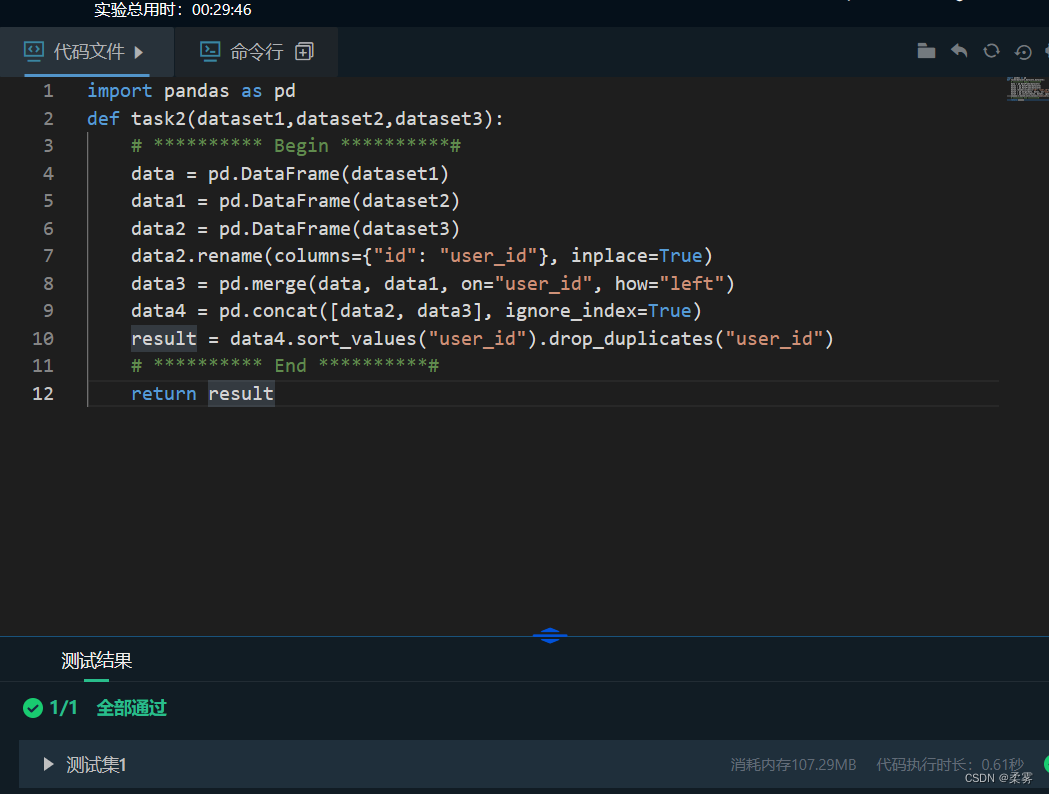
import pandas as pd
def task2(dataset1,dataset2,dataset3):
# ********** Begin **********#
data = pd.DataFrame(dataset1)
data1 = pd.DataFrame(dataset2)
data2 = pd.DataFrame(dataset3)
data2.rename(columns={"id": "user_id"}, inplace=True)
data3 = pd.merge(data, data1, on="user_id", how="left")
data4 = pd.concat([data2, data3], ignore_index=True)
result = data4.sort_values("user_id").drop_duplicates("user_id")
# ********** End **********#
return result
第3关:案例:美国各州的统计数据
编程要求
使用read_csv()函数读取step3文件夹中的state-population.csv(pop)、state-areas.csv(areas)、state-abbrevs.csv(abbrevs)文件;
合并pop和abbrevs。我们需要将pop的state/region列与abbrevs的abbreviation列进行合并,还需要通过how='outer’确保数据没有丢失,得到合并后的结果,发现有一个重复列需要删除,所以,删除abbreviation列;
来全面检查一下数据是否有缺失,对每个字段逐行检查是否有缺失值,通过结果可知只有population和state列有缺失值;
查看population这一列为缺失值的特征。通过结果可以得到好像所有的人口缺失值都出现在2000年之前的波多黎各,此前并没有统计过波多黎各的人口;
从上面的结果可以发现state这一列也有缺失值,通过下列代码可以查看是哪些州有缺失值;
merged.loc[merged[‘state’].isnull(),‘state/region’].unique()
我们可以快速解决这个问题:人口数据中包含波多黎各(PR)和全国总数(USA),但这两项没有出现在州名称缩写表中。我们可以用以下代码来填充对应的全称;
merged.loc[merged[‘state/region’] == ‘PR’, ‘state’] = ‘Puerto Rico’
merged.loc[merged[‘state/region’] == ‘USA’, ‘state’] = ‘United States’
然后我们用类似的规则将面积数据和处理完后的merged合并起来。数据合并的键为state,连接方式为左连接;
检查缺失值,从结果中可以发现,area列中还有缺失值;
查看是哪个地区面积缺失。结果如下:
从上面的结果可以得出缺少的是全美国的面积数据,但是我们的目标数据并不需要全美国的面积数据,所以我们需要删掉这些缺失值;
取year为2010年的数据,并将索引设为state列;
计算人口密度,将2010年的人口population除以面积area (sq. mi);
由于人口密度中分为成年人的人口密度和未成年人的人口密度,所以我们需要对两个值进行求合得到最终的人口密度;
对值进行排序,取人口密度结果的前5名与倒数5名;
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
无测试输入
预期输出:
前5名:
state
District of Columbia 10388.735294
Puerto Rico 1313.841536
New Jersey 1245.668425
Rhode Island 825.732686
Connecticut 792.459776
dtype: float64
后5名:
state
South Dakota 13.217619
North Dakota 11.661617
Montana 8.254689
Wyoming 7.151782
Alaska 1.373759
dtype: float64
开始你的任务吧,祝你成功!
示例代码如下:
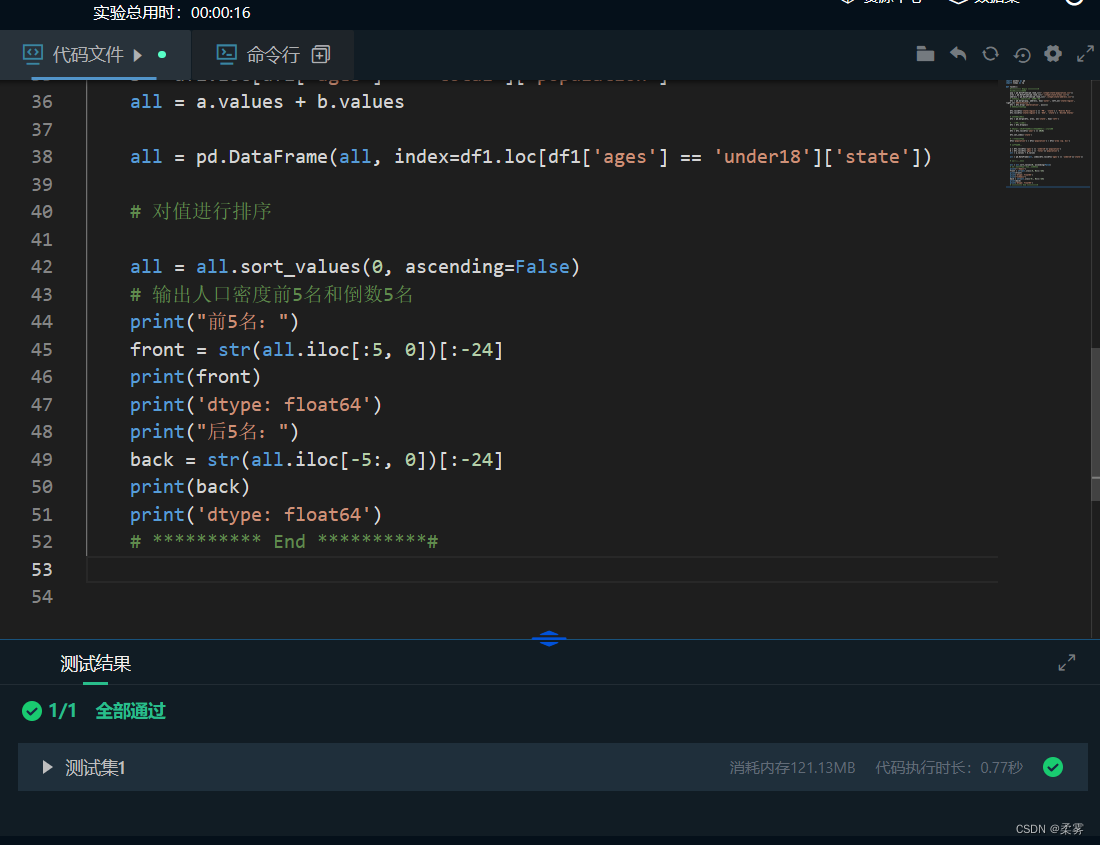
import pandas as pd
import numpy as np
def task3():
#********** Begin **********#
#读取三个csv文件
pop = pd.DataFrame(pd.read_csv("./step3/state-population.csv"))
ares = pd.DataFrame(pd.read_csv("./step3/state-areas.csv"))
abbrevs = pd.DataFrame(pd.read_csv("./step3/state-abbrevs.csv"))
# 合并pop和abbrevs并删除重复列
df1 = pd.merge(pop, abbrevs, how='outer', left_on='state/region', right_on='abbreviation')
df1 = df1.drop('abbreviation', axis=1)
# 填充对应的全称
df1.loc[df1['state/region'] == 'PR', 'state'] = 'Puerto Rico'
df1.loc[df1['state/region'] == 'USA', 'state'] = 'United States'
# 合并面积数据
df1 = pd.merge(df1, ares, on='state', how='left')
# 删掉这些缺失值
df1 = df1.dropna()
# 取year为2010年的数据,并将索引设为state列
df1 = df1.loc[df1['year'] == 2010]
df1.set_index('state')
# 计算人口密度
df1['population'] = df1['population'] / df1['area (sq. mi)']
# 对密度求和
a = df1.loc[df1['ages'] == 'under18']['population']
b = df1.loc[df1['ages'] == 'total']['population']
all = a.values + b.values
all = pd.DataFrame(all, index=df1.loc[df1['ages'] == 'under18']['state'])
# 对值进行排序
all = all.sort_values(0, ascending=False)
# 输出人口密度前5名和倒数5名
print("前5名:")
front = str(all.iloc[:5, 0])[:-24]
print(front)
print('dtype: float64')
print("后5名:")
back = str(all.iloc[-5:, 0])[:-24]
print(back)
print('dtype: float64')
# ********** End **********#















 3972
3972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









