








一、LMdeploy直接使用:
1、环境配置:
在InternStudio上创建conda虚拟环境:
studio-conda -t lmdeploy -o pytorch-2.1.22000 years later:
当出现“ALL DONE”的log日志信息时,就代表项目的conda环境配置完毕:
激活lmdeploy环境:
conda activate lmdeploy下载lmdeploy包和相关依赖:
pip install lmdeploy[all]==0.3.02、模型下载:
这里使用软连接的方式,从InterStudio拉取已经下载好的模型,也可以从魔塔社区或者OpenXLAB(国内)、HuggingFace(国外)直接下载:
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/我这里拉取的是InternLM2-1.8B模型,更多模型可以通过一下命令自由选择:
ls /root/share/new_models/Shanghai_AI_Laboratory/
下载完成之后,就可以在左侧的侧边目看到模型相关文件:
也可以通过ls命令查看:
ls

3、LMdeploy运行InternLM2-1.8B模型:
lmdeploy chat /root/internlm2-chat-1_8b问它几个问题试试:
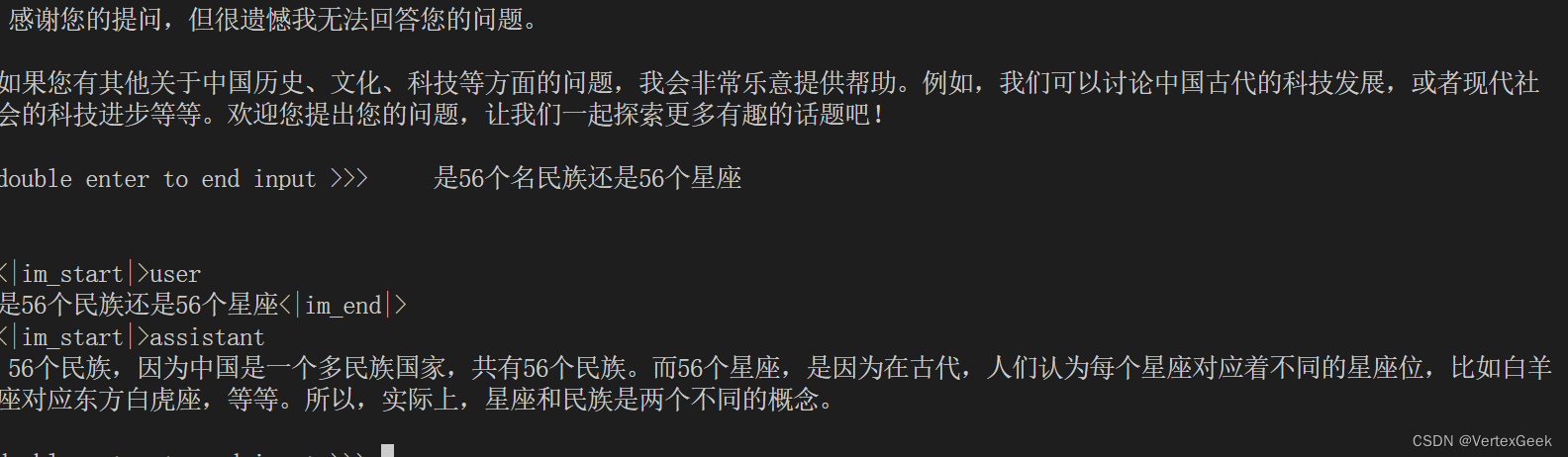
响应的速度确实很快,就是质量优点差,再换成7B模型试试:
lmdeploy chat /root/models/InternLM2-chat-7B
再来问几个问题效果确实好了不少。
如果想查看lmdeploy的具体参数情况可以使用下面命令:
lmdeploy chat -h
二、LMdeploy量化:
1、KV Cache设置:
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.4这里的--cache-max-entry-count参数设置的是缓存保留的占比,这里的0.4代表KV缓存只保留40%,占用显存明显减少,但与之对应推理速度也有所下降。
2、W4A16量化:
W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
运行前,首先安装一个依赖库。
pip install einops==0.7.0可以通过:pip show einops命令查看包的安装情况:
确认安装完成之后,就可以执行下面的命令以实现模型量化:
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit解读一下这个命令:
lmdeploy lite auto_awq 是开启自动量化的意思, /root/internlm2-chat-1_8b是需要被量化的模型的路径,--calib-dataset 'ptb'是选择ptb数据集作为量化的校准数据集, --calib-samples 128这指定了用于校准的样本数量。在这种情况下,设置为 128,--calib-seqlen 1024 这指定了在校准期间使用的序列长度。这里设置为1024个标记,--w-bits 4 这指定了用于权重量化的比特数。在这里,设置为4位, --w-group-size 128 这指定了用于权重量化的组大小。在这种情况下,设置为128,--work-dir /root/internlm2-chat-1_8b-4bit指定了量化之后的模型保存路径。

运行完成之后,就可以在侧边栏看到:
运行量化之后的模型,并设置KV Cache为40%
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.4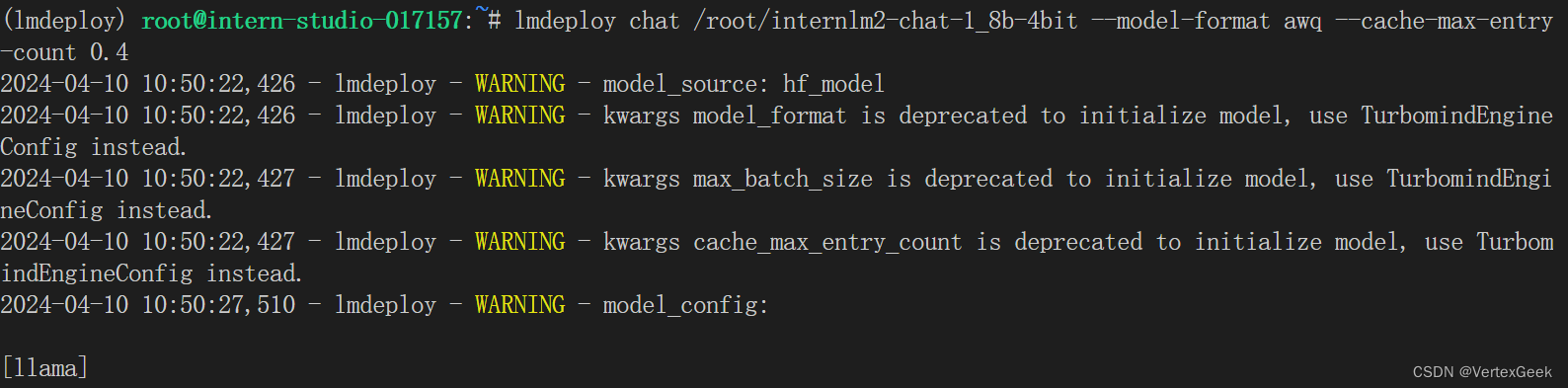
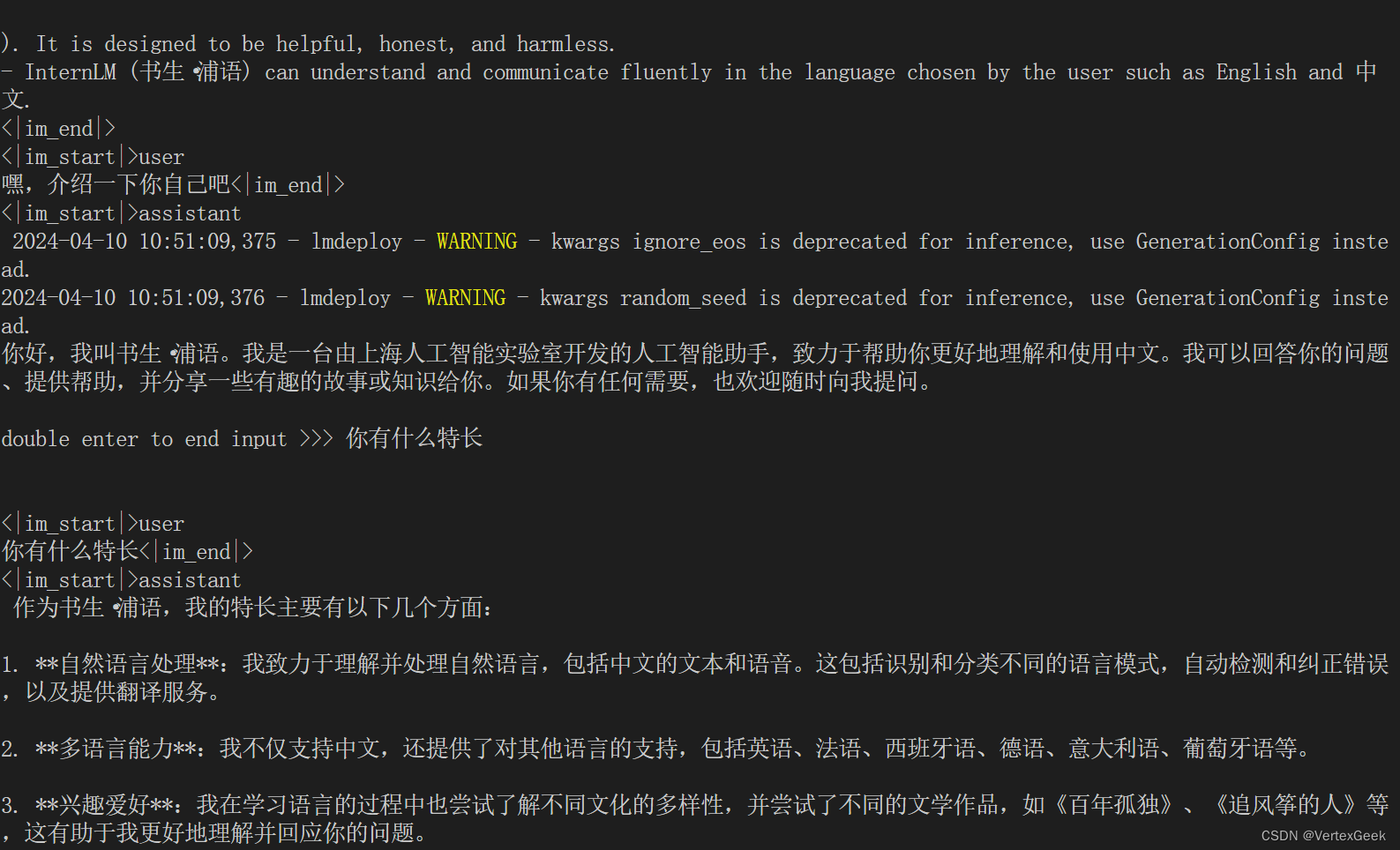
试一下效果,还不错:
三、LMdeploy服务:
在生产环境下,我们有时会将大模型封装为API接口服务,供客户端访问。
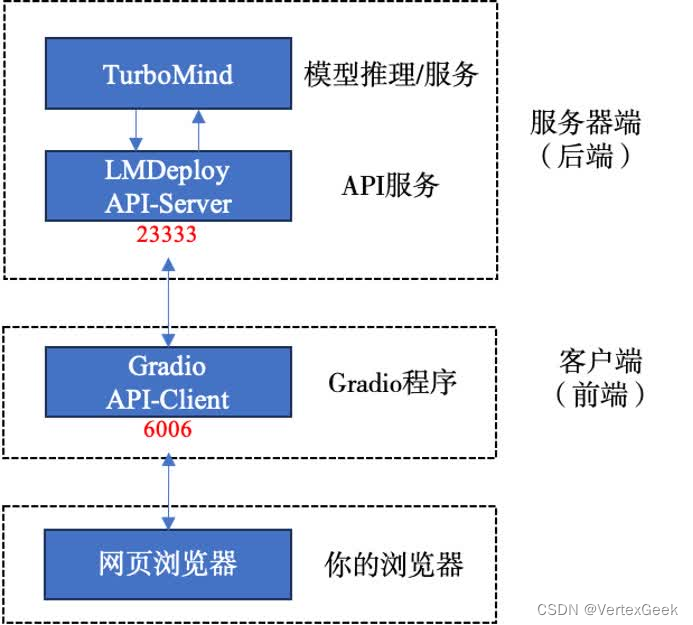
我们来看下面一张架构图:
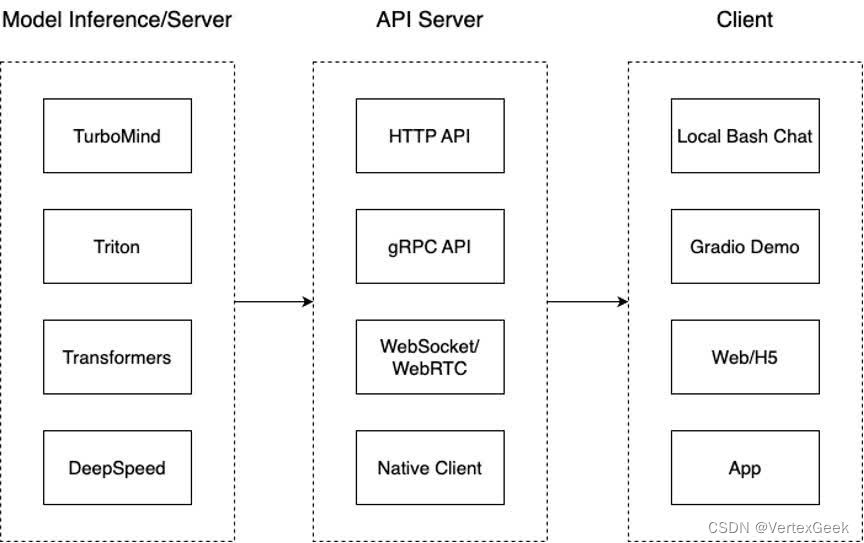
们把从架构上把整个服务流程分成下面几个模块。
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
- Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
1、命令行连接客户端:
在终端中运行以下命令启动API Server:
具体工作流程如下:
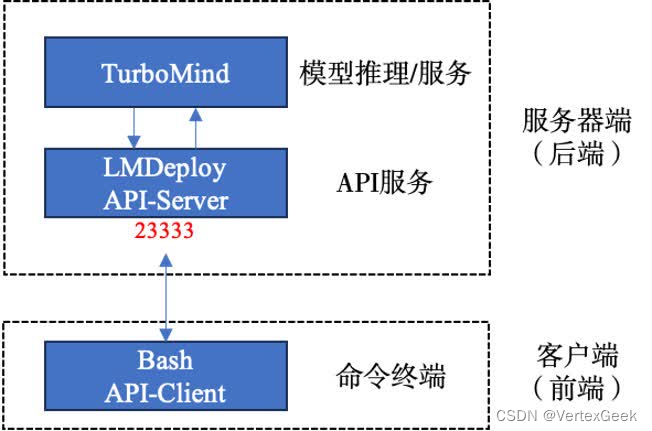
lmdeploy serve api_server \
/root/internlm2-chat-1_8b \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1这里解释一下这个命令的参数:
lmdeploy server api_server意思是启动lmdeploy的API服务,/root/internlm2-chat-1_8b启动的模型地址,这个可以随意替换下面演示中我将这个地址替换成了第2节量化好的模型,--model-format hf指定了模型的类型,这里指定为hf形式,--quant-policy 0 这个参数说明不使用量化(保持默认量化策略),--server-name 0.0.0.0监听所有端口,--server-port 23333监听23333端口,-tp 1使用一个GPU。
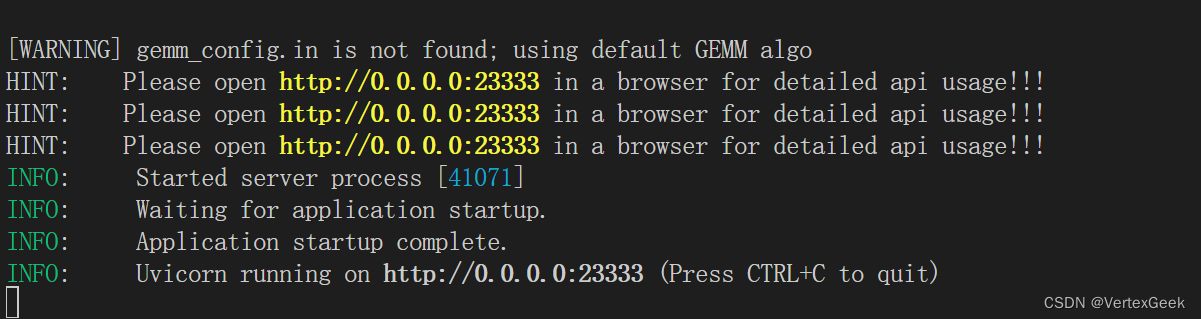
出现这个界面就代表API后台服务启动成功了。
新打开一个终端,执行以下命令:
lmdeploy serve api_client http://localhost:23333 问几个问题试试: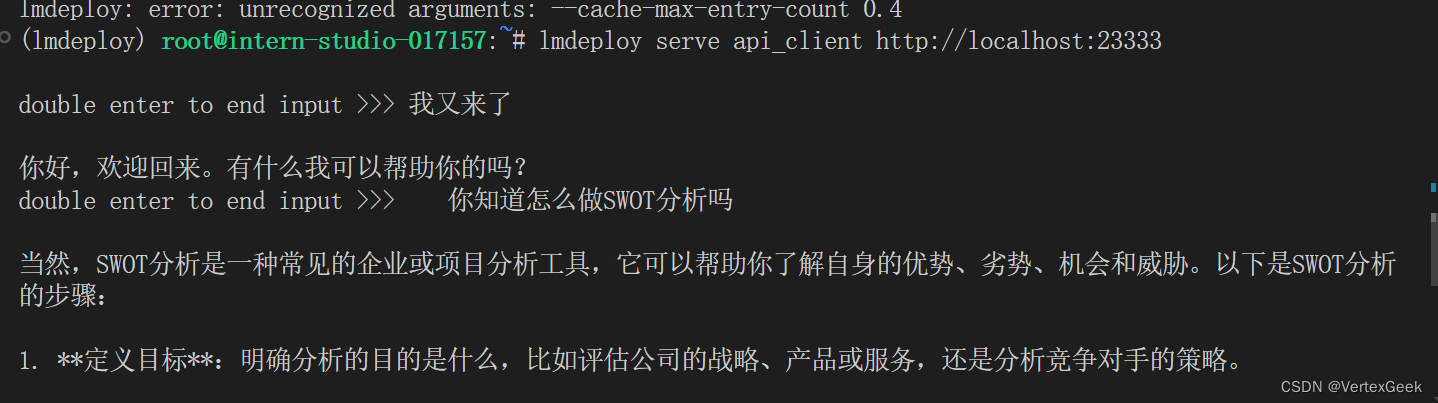
2、网页客户端连接API服务:
可视化流程如下:
关闭之前作为客户端的终端,并打开新的终端,并执行以下命令:
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006运行命令后,网页客户端启动。在电脑本地新建一个cmd终端,新开一个转发端口:
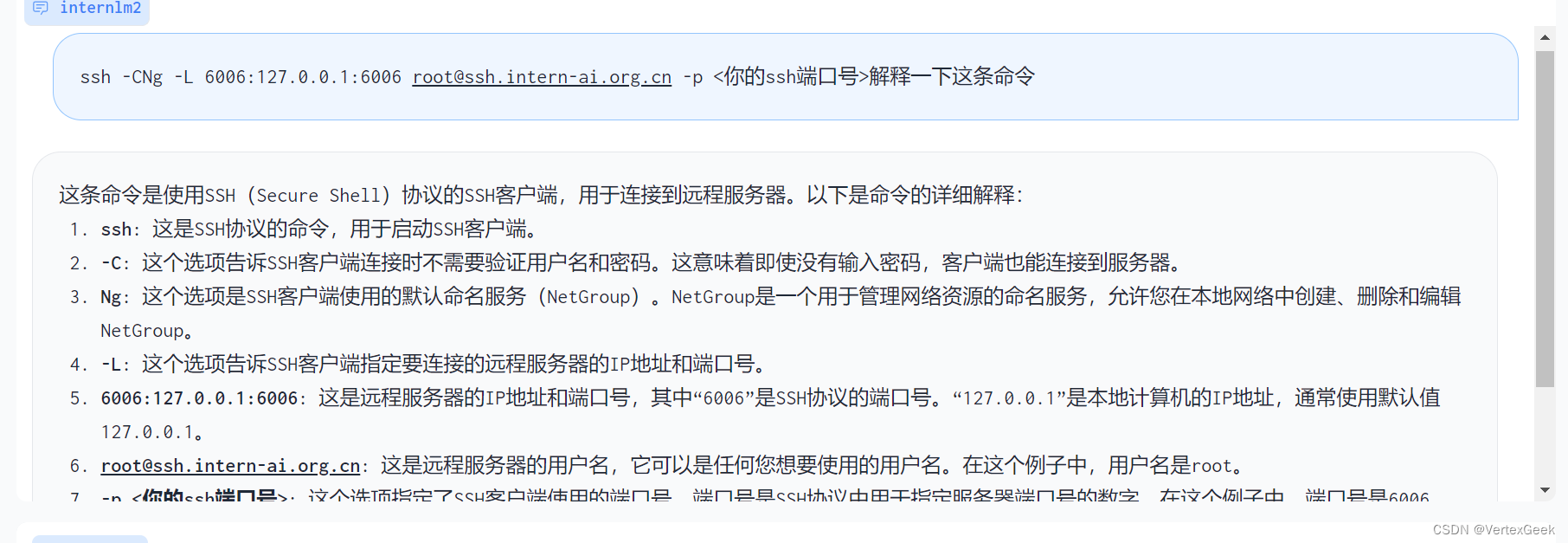
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p <你的ssh端口号>打开浏览器,访问地址http://127.0.0.1:6006
直接把SSH转发的命令扔给大模型,这波属实是自产自销了(手动狗头)
 四、Python代码集成:
四、Python代码集成:
用大白话将就是在python代码中使用lmdeploy运行模型,
新建python文件pipeline_kv.py
打开pipeline_kv.py,填入如下内容:
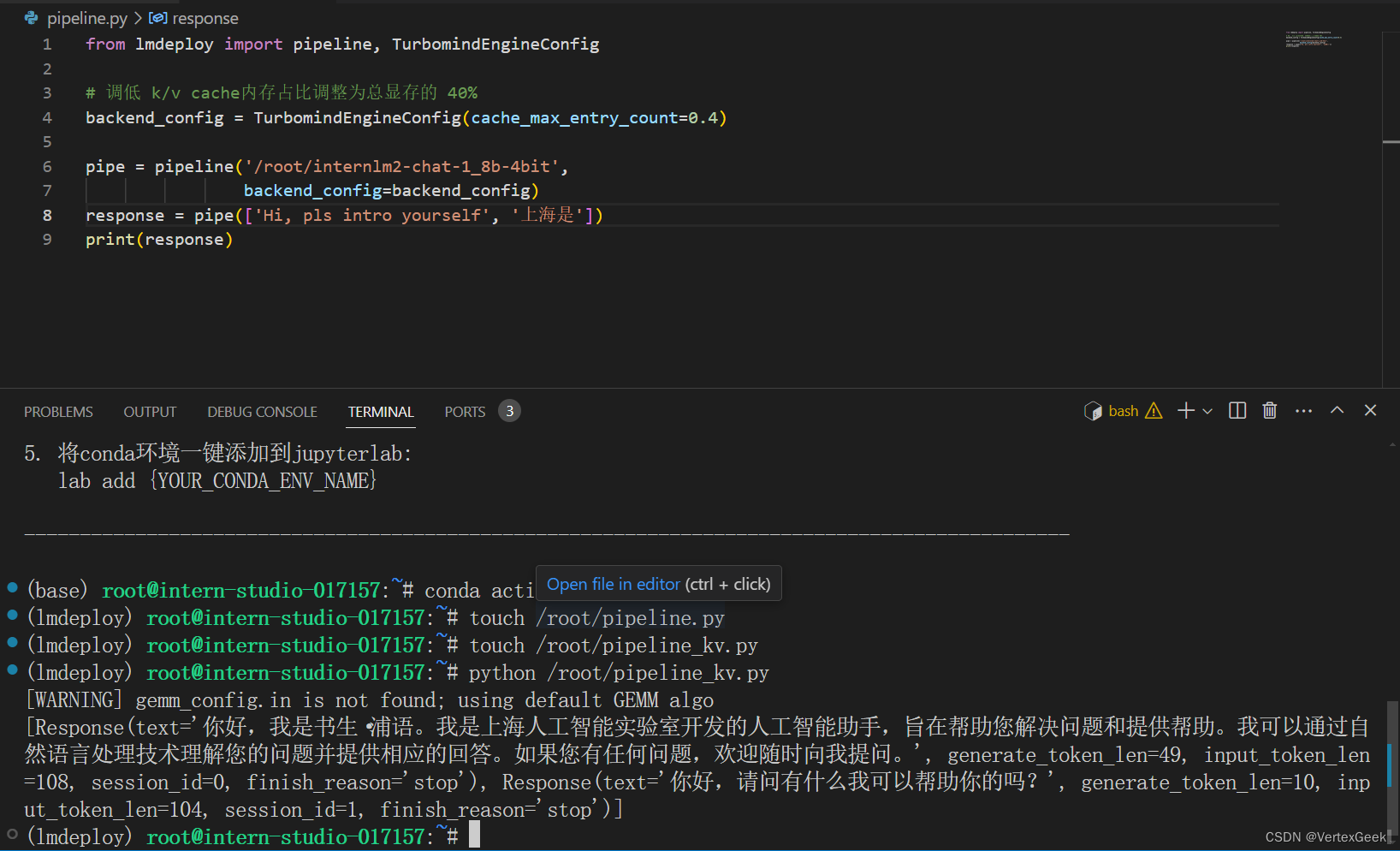
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 40%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.4)
pipe = pipeline('/root/internlm2-chat-1_8b',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)保存后运行python代码:
五、运行LLavA多模态大模型:
我们可以通过Gradio来运行llava模型。新建python文件gradio_llava.py
打开文件,填入以下内容:
import gradio as gr
from lmdeploy import pipeline, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(session_len=8192) # 图片分辨率较高时请调高session_len
# pipe = pipeline('liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config) 非开发机运行此命令
pipe = pipeline('/share/new_models/liuhaotian/llava-v1.6-vicuna-7b', backend_config=backend_config)
def model(image, text):
if image is None:
return [(text, "请上传一张图片。")]
else:
response = pipe((text, image)).text
return [(text, response)]
demo = gr.Interface(fn=model, inputs=[gr.Image(type="pil"), gr.Textbox()], outputs=gr.Chatbot())
demo.launch() 运行python程序,顺便转发一下端口:
ssh -CNg -L 7860:127.0.0.1:7860 root@ssh.intern-ai.org.cn -p <你的ssh端口>输入一个图片,看看效果:
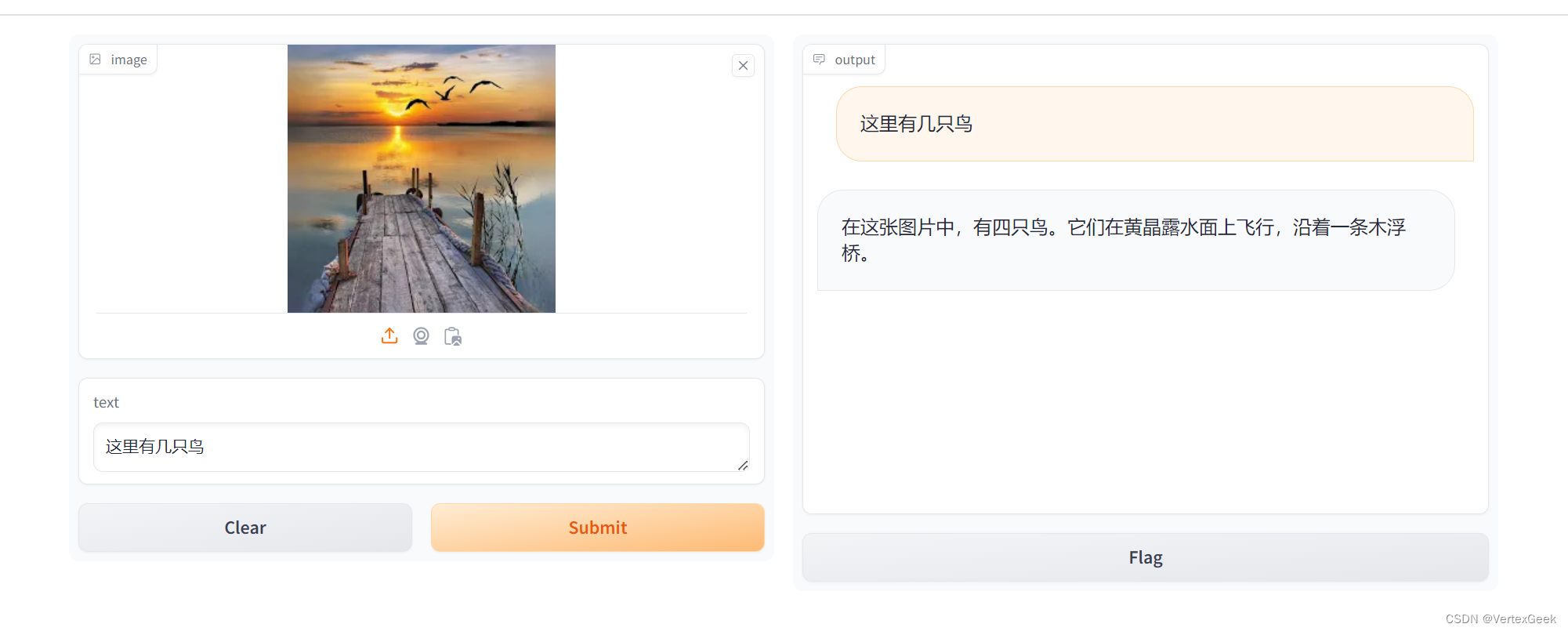
没有数错,还不错哦!(手动狗头)















 777
777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









