







 本文探讨了如何通过微调LLM模型解决幻觉问题和领域知识不足,介绍了增量预训练、指令跟随微调以及LORA方法,重点讲解了使用XTuner工具对InternLM-7B模型进行微调的过程,包括环境配置、数据集准备、模型下载和自定义参数设置,以及如何将微调后的模型整合和部署到实际应用中。
本文探讨了如何通过微调LLM模型解决幻觉问题和领域知识不足,介绍了增量预训练、指令跟随微调以及LORA方法,重点讲解了使用XTuner工具对InternLM-7B模型进行微调的过程,包括环境配置、数据集准备、模型下载和自定义参数设置,以及如何将微调后的模型整合和部署到实际应用中。
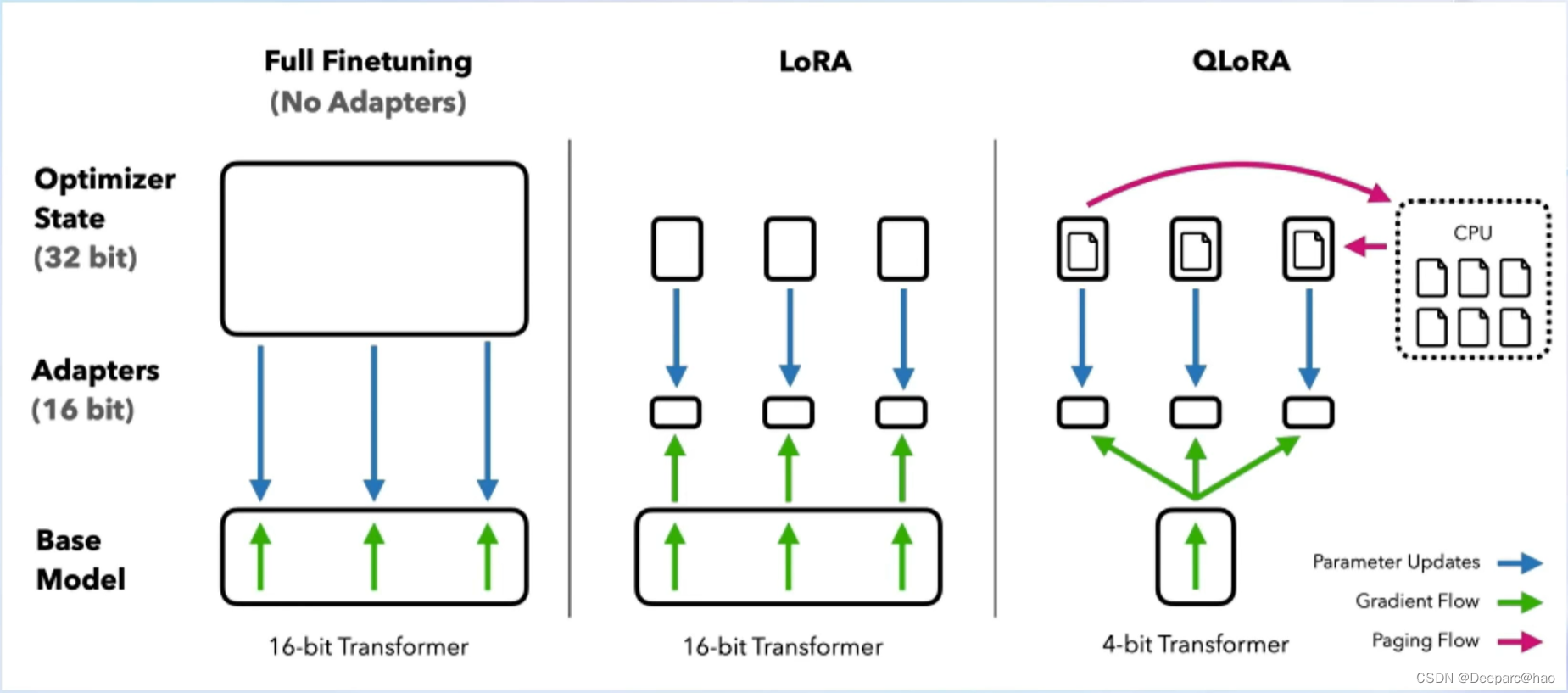
一、微调(finetune):
LLM模型存在的幻觉问题、专业知识领域不强等问题,除了可以通过第三章提到的RAG技术解决,还可以通过对大模型进行专业领域知识的微调,来提升其在专业领域的能力,减少幻觉,提高个性化水平。
1、增量预训练微调:
让基座模型学习新知识,如某垂直领域的常识数据:文章,代码,书籍等,类似于无监督学习。
2、指令跟随微调:
根据人类指令进行对话训练,提高模型的对话能力,类似于监督学习。
3、lora:
LLM的参数量主要集中在模型的linear中,将这些参数进行全量微调,需要的显存极为庞大。
LORA是一种便捷的微调方法,仅训练一部份参数,大大降低了对显存的需求。
原理:
LORA通过在linear层旁边,新增一个支路,包含两个连续的小linear,新增的这个支路通常定义为Adapter.
Adapter的参数量远远小于原来的linear,大大降低了对显存的占用。
二、利用Xtuner微调InternLM-7B模型:
1、环境配置:
Ubuntu + Anaconda + CUDA/CUDNN + 8GB nvidia显卡(软件和硬件配置)
基础的依赖包和之前安装的一致(也可以先不安装,用到再安装),直接进入创建的虚拟环境:
conda activate xtuner0.1.9创建基础文件目录,进入并拉取代码:
mkdir xtuner019 && cd xtuner019
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
xtuner list-cfg假如显示bash: xtuner: command not found的话可以考虑在终端输入 export PATH=$PATH:'/root/.local/bin'
配置文件名的解释(例子):
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3 (epoch 3 ) |
再创建一个本次训练专用的文件夹:
mkdir ~/ft-oasst1 && cd ~/ft-oasst1文件准备:
拷贝一个配置文件到当前目录: # xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .2、模型下载:
cp -r /root/share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/3、数据集准备:
复制Xtuner准备好的数据集:
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .修改其中的模型和数据集为 本地路径
cd ~/ft-oasst1
在vim界面完成修改后,请输入:wq退出。假如认为改错了可以用:q!退出且不保存。当然我们也可以考虑打开python文件直接修改,但注意修改完后需要按下Ctrl+S进行保存。
vim internlm_chat_7b_qlora_oasst1_e3_copy.py
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| ...... | ...... |
自定义数据集:
将准备好的数据转换为jsonl格式:
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]通过 python脚本:将 数据集中的 “问题” 和 “回答 ”两列 提取出来,再放入 .jsonL 文件的每个 conversation 的 input 和 output 中,这一步的 python 脚本可以请 ChatGPT 来完成。
prompt提示词:
Write a python file for me. using openpyxl. input file name is MedQA2019.xlsx
Step1: The input file is .xlsx. Exact the column A and column D in the sheet named "DrugQA" .
Step2: Put each value in column A into each "input" of each "conversation". Put each value in column D into each "output" of each "conversation".
Step3: The output file is .jsonL. It looks like:
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]
Step4: All "system" value changes to "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."划分训练集和测试集,这一步也可以利用chatgpt创作python脚本实现
my .jsonL file looks like:
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]
Step1, read the .jsonL file.
Step2, count the amount of the "conversation" elements.
Step3, randomly split all "conversation" elements by 7:3. Targeted structure is same as the input.
Step4, save the 7/10 part as train.jsonl. save the 3/10 part as test.jsonl修改internlm_chat_7b_qlora_oasst1_e3_copy.py文件的参数配置:
# 修改import部分,其实这一句改不改都行
- from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import template_map_fn_factory
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据为 MedQA2019-structured-train.jsonl 路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = 'MedQA2019-structured-train.jsonl'
# 修改 train_dataset 对象
train_dataset = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=data_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)4、微调:
执行以下代码:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的 ./work_dirs 中。
微调时间一般较长,为了避免因为网络等不可控的因素,而中断微调训练 ,可以利用Tmux进行训练:
# 更新
apt updata -y
# 下载tmux
apt install tmux -y
# 创建tmux环境,在该环境中运行微调
tmux new -s finetune
# ctrl B + D 快捷键推出
# 再次进入创建的 finetune
tmux attach finetine 微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的 ./work_dirs 中
将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf将 HuggingFace adapter 合并到大语言模型
xtuner convert merge \
${NAME_OR_PATH_TO_LLM} \
${NAME_OR_PATH_TO_ADAPTER} \
${SAVE_PATH} \
--max-shard-size 2GB
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat5、运行:
terminal:
- 修改
cli_demo.py中的模型路径
- model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b" + model_name_or_path = "merged"
- 运行
cli_demo.py以目测微调效果
python ./cli_demo.py
xtuner chat 的启动参数
| 启动参数 | 干哈滴 |
|---|---|
| --prompt-template | 指定对话模板 |
| --system | 指定SYSTEM文本 |
| --system-template | 指定SYSTEM模板 |
| --bits | LLM位数 |
| --bot-name | bot名称 |
| --with-plugins | 指定要使用的插件 |
| --no-streamer | 是否启用流式传输 |
| --lagent | 是否使用lagent |
| --command-stop-word | 命令停止词 |
| --answer-stop-word | 回答停止词 |
| --offload-folder | 存放模型权重的文件夹(或者已经卸载模型权重的文件夹) |
| --max-new-tokens | 生成文本中允许的最大 token 数量 |
| --temperature | 温度值 |
| --top-k | 保留用于顶k筛选的最高概率词汇标记数 |
| --top-p | 如果设置为小于1的浮点数,仅保留概率相加高于 top_p 的最小一组最有可能的标记 |
| --seed | 用于可重现文本生成的随机种子 |
web_demo:
在完成ssh连接之后,老规矩:streamlit run /root/personal_assistant/code/InternLM/web_demo.py --server.address 127.0.0.1 --server.port 6006
注意:web_demo运行需要streamlit包,如果前面没有安装,在运行之前还需安装一下依赖包


















 2076
2076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









