






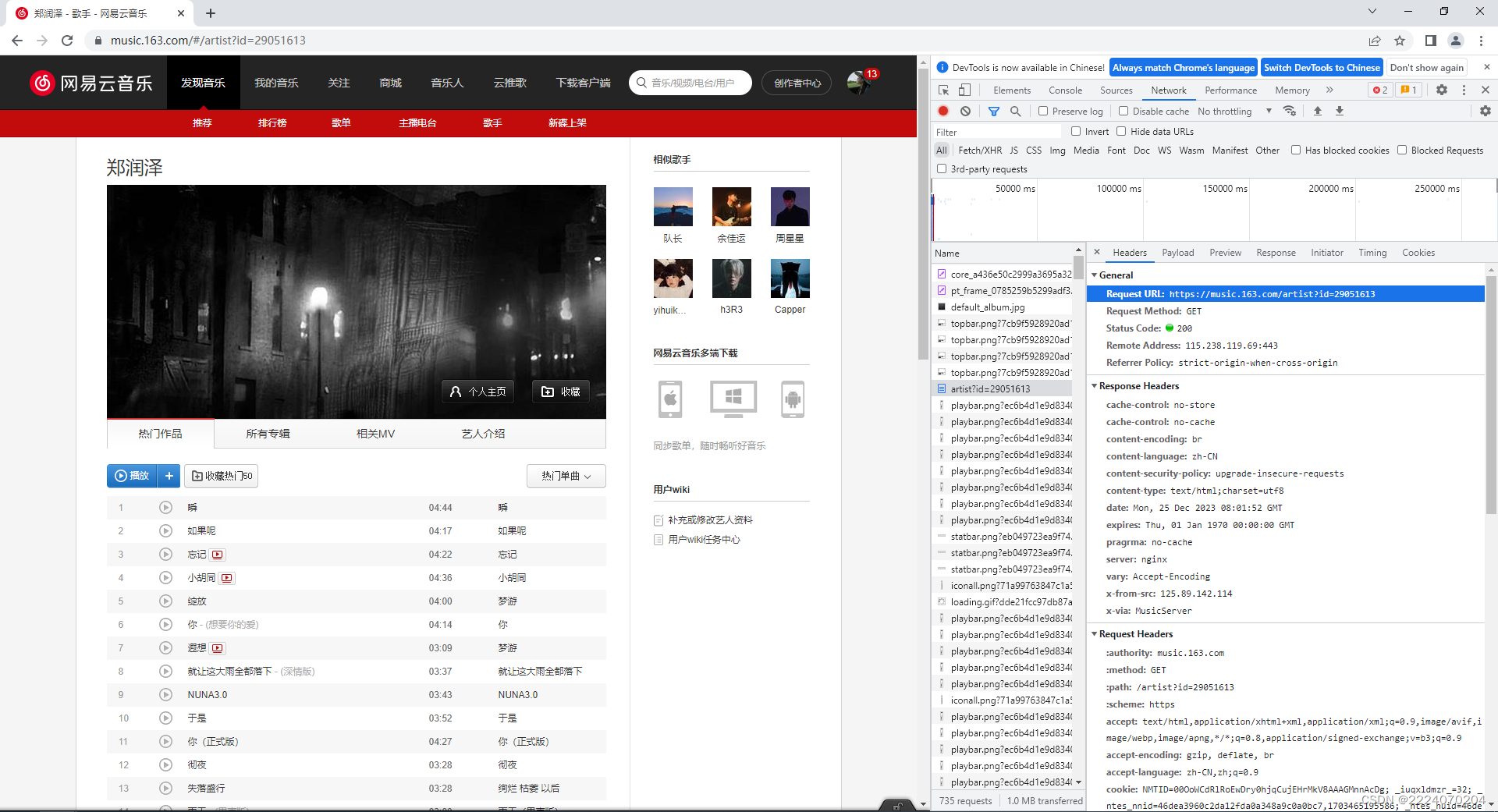
1、打开网易云选择喜欢的歌手
2、爬取网站
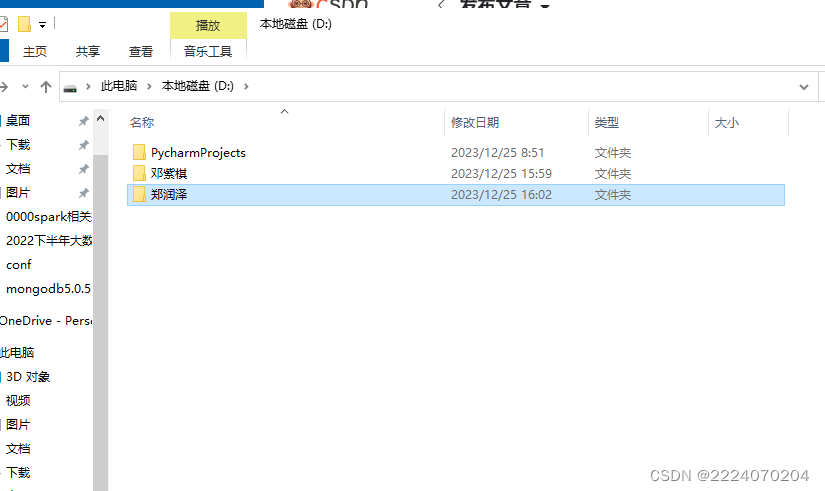
3、创建文件夹
import requests
from bs4 import BeautifulSoup
def music():
url = 'https://music.163.com/artist?id=29051613'
#伪装自己
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 SLBrowser/7.0.0.1071 SLBChan/21',
'referer': 'https://music.163.com/'
}
data = {
"params": "+H6D23233AX7 + ZhHr4HqHLeDwi5A9nhbtTqkxhoFC / A9Jf01CuoQpZ + AX7YFx + +W",
"encSecKey": "0b87f8306db58707587ee170832712c5781f96adc1890048e339977a819f26b86f814c91b2bafbb123a35de4da4d16678f1f5ca2af99657b48048a30dad0b18ed14e2f32c23145c6e42349af1356287119e7b1157b544f292b212d7014168b22605b83692af7fc5c4fd3395c86fa7ea9395b4b9fb560b83268044be825c61723"
}
response = requests.get(url=url,headers=headers,params=False,data=data).content.decode("utf-8")
s = BeautifulSoup(response, 'lxml')
main = s.find('ul', {'class': 'f-hide'})
list= main.find_all("a")
for i in list:
name = i.text.replace("/"," ")
music_url = 'http://music.163.com/song/media/outer/url' + i['href'][5:] + '.mp3'
# 第一次没有这两行代码,所以下载出来文件是错误的。因为请求中有重定向,禁止以后,再次访问重定向的链接就行了
response = requests.get(music_url, headers=headers, allow_redirects=False, data=data)
url = response.headers.get('Location')
music = requests.get(music_url,headers=headers,data=data).content
with open('D:/郑润泽/'+name + '.mp3', mode='wb') as file:
file.write(music)
print(name + "正在下载")
print("over!!!")
if __name__ == '__main__':
music()

















 1909
1909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









