







目录
导入csv文件
导入csv文件时除了指明文件路径,还需要设置编码格式。Python 中用得比较多的两种编码格式是UTF-8和gbk,默认编码格式是UTF 8。
我们要根据导入文件本身的编码格式进行设置,通过设置参数 encoding来设置导入的编码格式。
【示例】导入.csv文件,文件编码格式是gbk。
pd.read_csv('stu_data.csv',encoding='gbk')用分隔符号进行分隔。常用的分隔符除了逗号、空格,还有制表符 (\t)。
【示例】导入.csv文件,指明分隔符
df=pd.read_csv("stu_data.csv",encoding='gbk',sep =' ')
pd.read_csv('stu_data.csv',encoding='gbk',sep =',')变量类型的转换
Pandas 支持的数据类型
- float
- int
- string
- bool
- datetime64[nsr] datetime64[nsr,tz] timedelta[ns]
- category
- object
df.dtypes:查看各列的数据类型
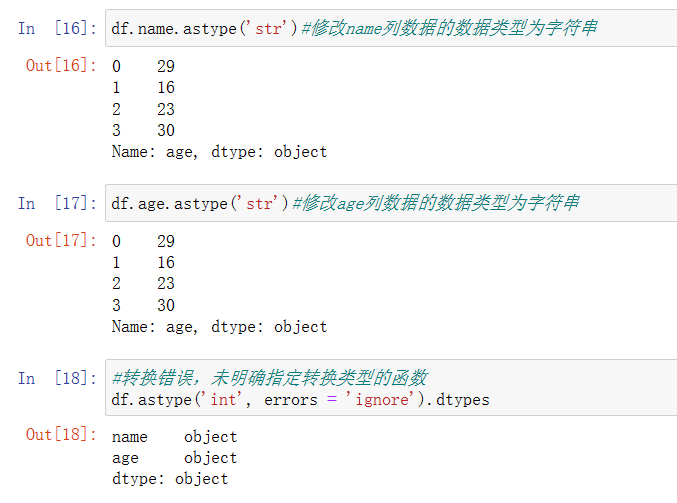
在不同数据类型间转换:df.astype(
dtype :指定希望转换的数据类型,可以使用 numpy 或者 python 中的数据类型: int/float/bool/str
copy = True :是否生成新的副本,而不是替换原数据框
errors = 'raise' :转换出错时是否抛出错误, raise/ ignore )
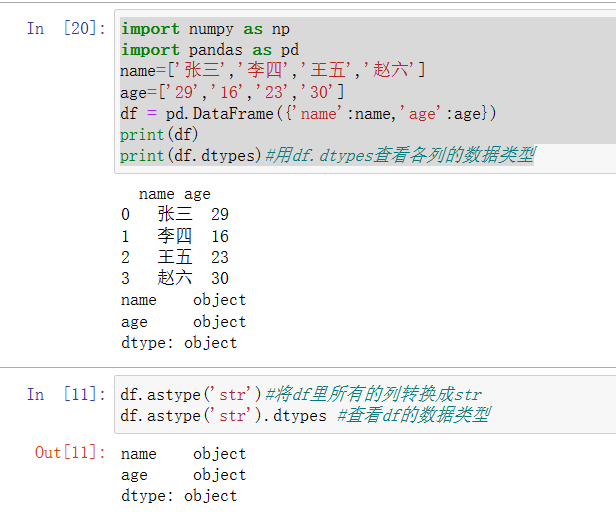
示例代码:
import numpy as np
import pandas as pd
name=['张三','李四','王五','赵六']
age=['29','16','23','30']
df = pd.DataFrame({'name':name,'age':age})
print(df)
print(df.dtypes)#用df.dtypes查看各列的数据类型
结果演示:
建立索引
所有的数据框默认都已经使用从 0 开始的自然数索引。下面介绍的都是自定义索引。
新建数据框时建立索引
df2 = pd.DataFrame( {'varl' : 1.0, ' var2' : [1,2,3,4], 'var3' : ['test', 'python','test', 'hello'] , 'var4' : 'cons'} , index = [0,1,2,3]) 
读入数据时建立索引


指定某列为索引列
df.set_index(
keys :被指定为索引的列名,复合索引用 list格式提供
drop = True :建立索引后是否删除该列
append = False :是否在原索引基础上添加索引,默认是直接替换原索引
inplace = False :是否直接修改原数据框 )
df_new = df.set_index (keys=['学号','性别'],drop = False)
df_new = df.set_index (keys='学号', append=True, drop=False)
将索引还原变量列
df.reset_index(
drop = False :是否将原索引直接删除,而不是还原为变量列
inplace = False :是否直接修改原数据框 )



xue














 2818
2818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









