






目录
2.3 Scala插件 (版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装)
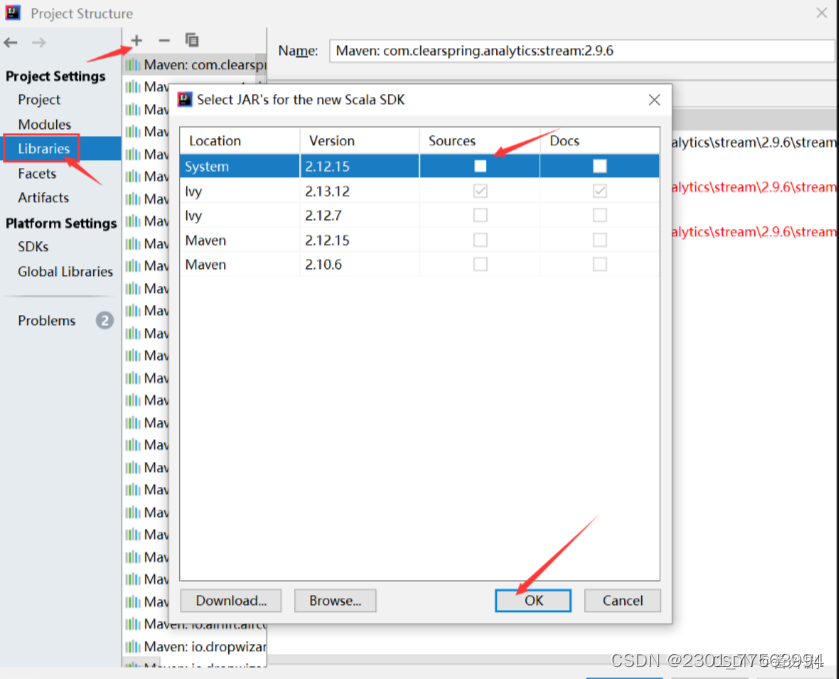
2.6 鼠标点击java文件夹,右键new--->Scala Class
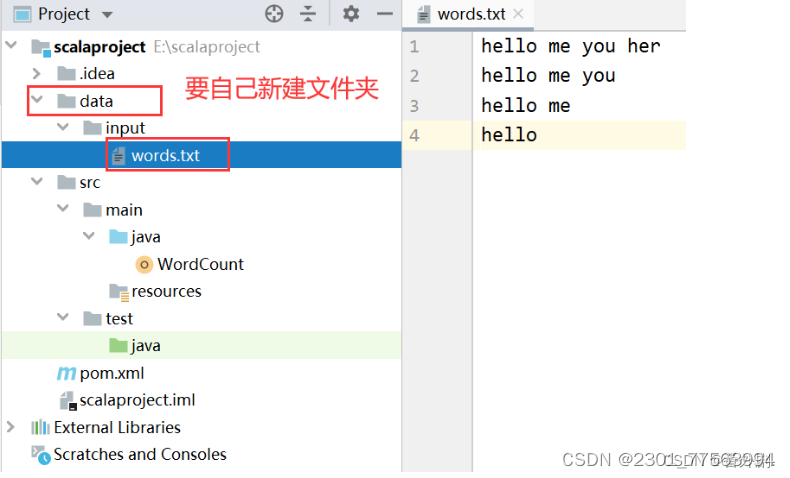
2.7 准备好测试文件words.txt,将文件存放在scalaproject-->data-->input-->words.txt
5.2 WordCount.scala文件在yarm上运行:
一、Spark和Hadoop的区别
Hadoop虽然已经成为大数据技术的事实标准,但其本身存在很多缺陷。比如,mapreduce计算模型延迟过高,无法实现实时快速计算的需求,只适用于离线批处理,I/O磁盘开销大。spark在借鉴mapreduce优点同时,很好解决了mapreduce存在的缺陷:
- spark计算也属于mapreduce计算,但不局限于map和reduce操作;
- spark提供内计算,中间结果放入内存,提高迭代运算效率
- 基于DAG的任务调度执行机制,优于mapreduce调度机制。
二、安装IDEA
可以在官网下载安装社区版本:
IntelliJ IDEA – the Leading Java and Kotlin IDE
2.1安装Scala
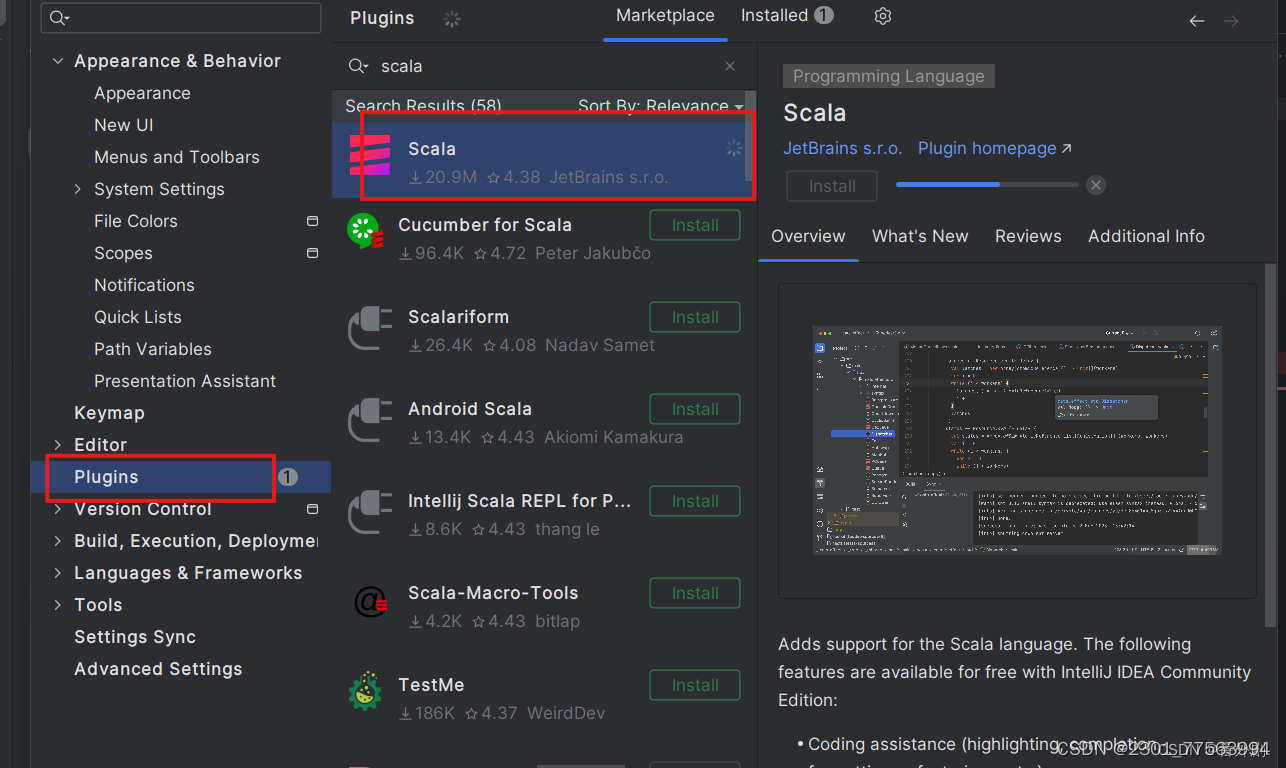
在File菜单->Settings->Plugins 插件安装界面搜索scala插件安装。
2.2 Scala下载
(我选择的版本是2.12.15)安装及环境变量的配置
官方下载地址:The Scala Programming Language (scala-lang.org)
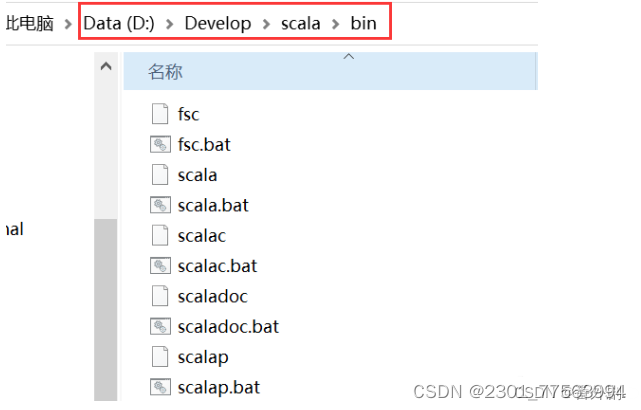
双击打开下载好的安装程序,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将scala软件安装在了D盘目录下的Develop文件夹,bin路径如下:
配置scala的系统环境变量,将scala安装的bin目录路径加入到系统环境变量path中:

win+R打开命令窗口输入:scala -verison ,进行检测是否成功配置环境变量

2.3 Scala插件 (版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装)
Scala - IntelliJ IDEs Plugin | Marketplace
下载完成后,将下载的压缩包解压到IDEA安装目录下的plugins目录下
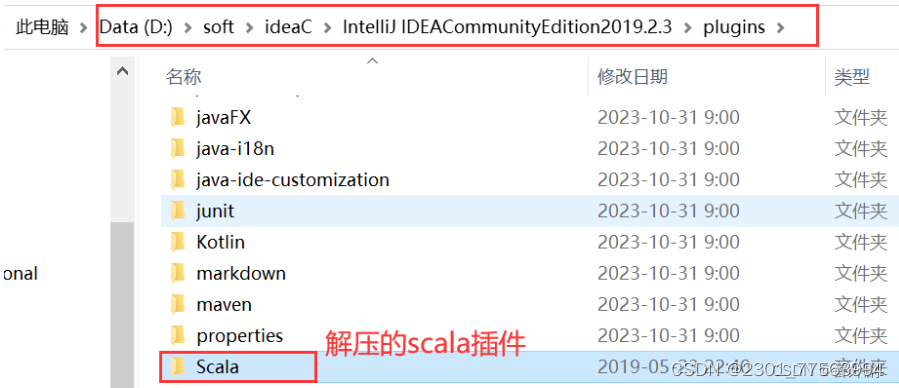
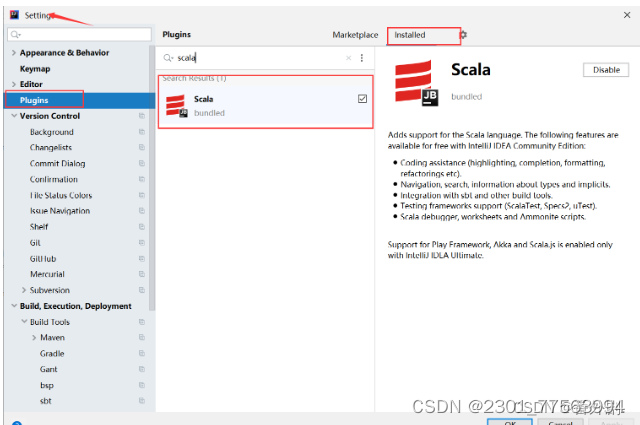
2.4 检测Scala插件是否在IDEA中已经安装成功
2.5 新建scala类文件编写代码
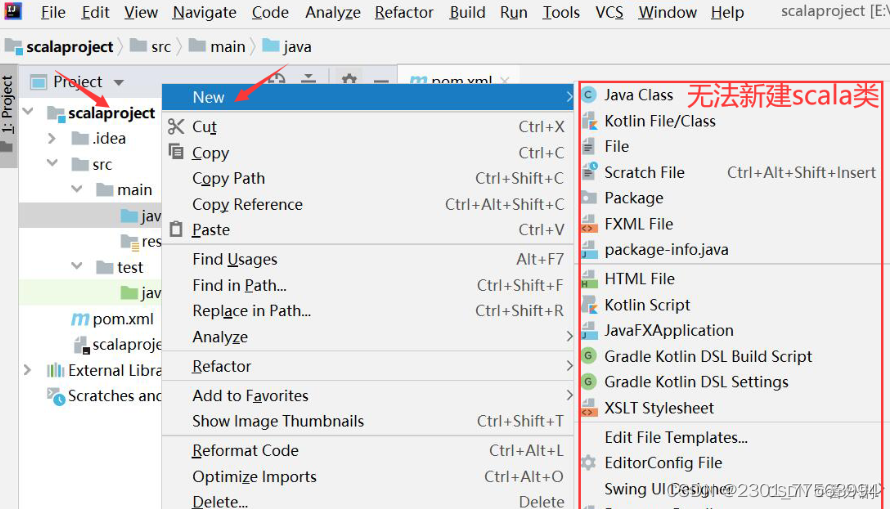
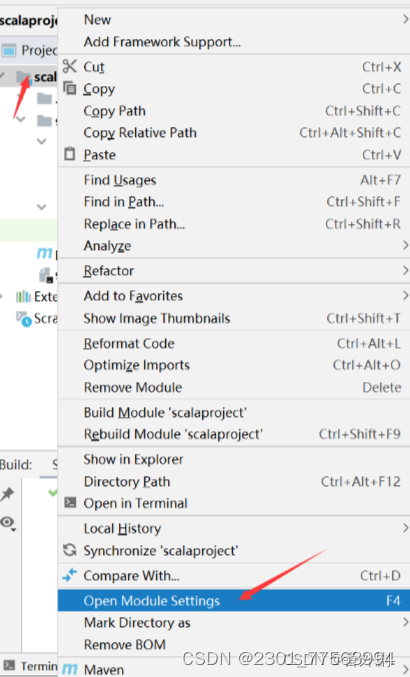
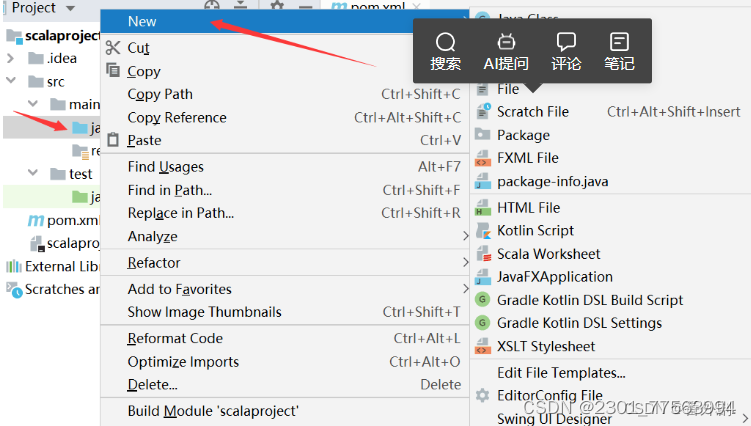
2.6 鼠标点击java文件夹,右键new--->Scala Class
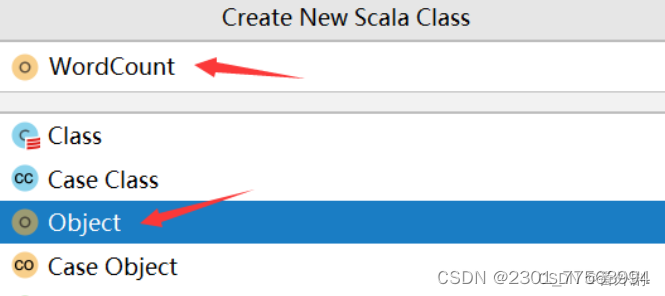
在WordCount文件中编写如下代码:
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("word count")
.getOrCreate()
val sc = spark.sparkContext
val rdd = sc.textFile("data/input/words.txt")
val counts = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
counts.collect().foreach(println)
println("全部的单词数:"+counts.count())
counts.saveAsTextFile("data/output/word-count")
}
}2.7 准备好测试文件words.txt,将文件存放在scalaproject-->data-->input-->words.txt

运行WordCount程序:
运行结果:

三、编写本地运行的Spark程序
3.1 编写pom.xml文件
管理spark程序依赖jar,此时要能上网,在pom.xml文件中,添加如下配置信息
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<properties>
<encoding>UTF-8</encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.10</scala.version>
<spark.version>3.0.1</spark.version>
<hadoop.version>2.7.7</hadoop.version>
</properties>
<dependencies>
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>刷新maven工程,会自动下载所需依赖jar,此时会下载时间较长,耐心等待
3.2 编写程序
WordCount .scala文件实现单词计数关键代码的解析如下:
//1.env/准备sc/SparkContext/Spark上下文执行环境
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//2.source/读取数据
val lines: RDD[String] = sc.textFile("data/input/words.txt")
//(这里要特别注意一下,你自己电脑的目录下要保证有这个words.txt文件)
//3.transformation/数据操作/转换
//切割:RDD[一个个的单词]
val words: RDD[String] = lines.flatMap(_.split(" "))
//记为1:RDD[(单词, 1)]
val wordAndOnes: RDD[(String, Int)] = words.map((_,1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_)
//4.输出
//直接输出
result.foreach(println)
//输出到指定path(可以是文件/夹)
result.repartition(1).saveAsTextFile("data/output/result")
//为了便于查看Web-UI可以让程序
Thread.sleep(1000 * 60)
//5.关闭资源
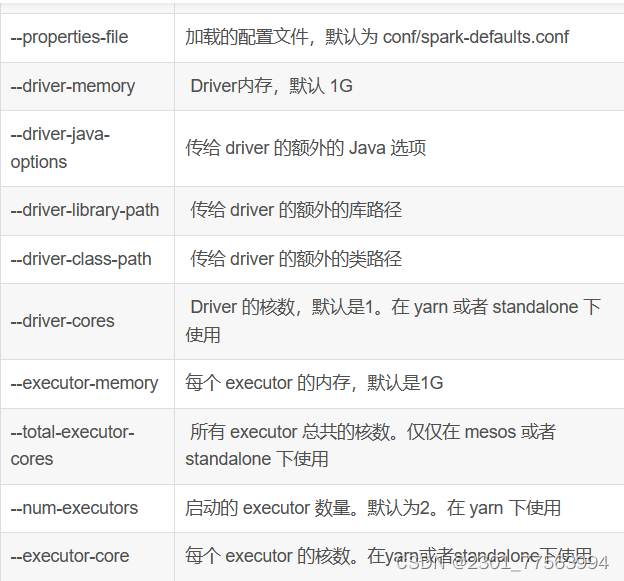
sc.stop()四、spark-submit 详细参数说明

五、完整代码实现
5.1 WordCount.scala文件在本地运行:
package net.objet
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.env/准备sc/SparkContext/Spark上下文执行环境
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//2.source/读取数据
val lines: RDD[String] = sc.textFile("data/input/words.txt")
//3.transformation/数据操作/转换
//切割:RDD[一个个的单词]
val words: RDD[String] = lines.flatMap(_.split(" "))
//记为1:RDD[(单词, 1)]
val wordAndOnes: RDD[(String, Int)] = words.map((_,1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_)
//4.输出
//直接输出
result.foreach(println)
//输出到指定path(可以是文件/夹)
result.repartition(1).saveAsTextFile("data/output/result")
//为了便于查看Web-UI可以让程序
Thread.sleep(1000 * 60)
//5.关闭资源
sc.stop()
}
}5.2 WordCount.scala文件在yarm上运行:
package net
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
if(args.length < 2){
println("请指定input和output")
System.exit(1)//非0表示非正常退出程序
}
//1.env/准备sc/SparkContext/Spark上下文执行环境
val conf: SparkConf = new SparkConf().setAppName("wc") //.setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//2.source/读取数据
val lines: RDD[String] = sc.textFile(args(0))
//3.transformation/数据操作/转换
//切割:RDD[一个个的单词]
val words: RDD[String] = lines.flatMap(_.split(" "))
//记为1:RDD[(单词, 1)]
val wordAndOnes: RDD[(String, Int)] = words.map((_,1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_)
//4.输出
//直接输出
result.foreach(println)
//输出到指定path(可以是文件/夹)
result.repartition(1).saveAsTextFile(args(1))
//为了便于查看Web-UI可以让程序Thread.sleep(1000 * 60)
//5.关闭资源
sc.stop()
}
}














 3345
3345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









