







来源于哔站书生浦语大模型训练营视频课程
此文章为个人学习笔记,想了解更多内容请观看原版视频
一、Finetune简介:

Finetune也就是我们常说的微调。
大模型是在海量的内容上进行无监督或者半监督的方式来进行训练的,训练出的模型涵盖多个领域但是不精确,回答专业知识不太准确,而微调就是为了解决这个问题,使模型在专业领域的回答更好一点。
1.1LLM下游应用中常常用到的俩种微调模式:
增量预训练微调:
使用场景:让基座模型学习到一些新知识,如某个垂直领域的常识
训练数据:文章、书籍、代码等
指令跟随微调:
使用场景:让模型学会对话模板,根据人类指令进行对话
训练数据:高质量的对话、问答数据
应用举例:
不经过微调会答非所问

数据处理使用流程:
标准数据格式:在internLM中是.json格式

1.2指令跟随微调
指令跟随微调是为了得到能够实际对话的LLM
介绍指令跟随微调前,需要先了解如何使用LLM进行对话
在实际对话时,通常会有三种角色
System 给定一些上下文信息,比如“你是一个安全的AI助手"
User 实际用户,会提出一些问题,比如“世界第一高峰是?”
Assistant 根据 User 的输入,结合System的上下文信息,做出回答,比如“珠穆朗玛峰”在使用对话模型时,通常是不会感知到这三种角色的
1.2.1指令微调中的角色指定
在实际操纵中,我们会进行角色指定,把问题给user角色,把答案(珠穆朗玛峰)给assistant角色,system按自己微调的目标领域来书写。同一微调中system一般是固定的。
到此我们完成了一个对话模板的构建,具体如下:

每个开源模型使用的对话模板都不一样,LlaMa 2 和internLM的区别如下左图

以上的内容都是微调的部分,也就是微调阶段。在预测阶段是不需要用户进行角色分配的,用户输入的内容默认放入了user,system由模板自动添加,在启动预测时候可以指定。(Xtuner)
1.2.2指令微调的原理:
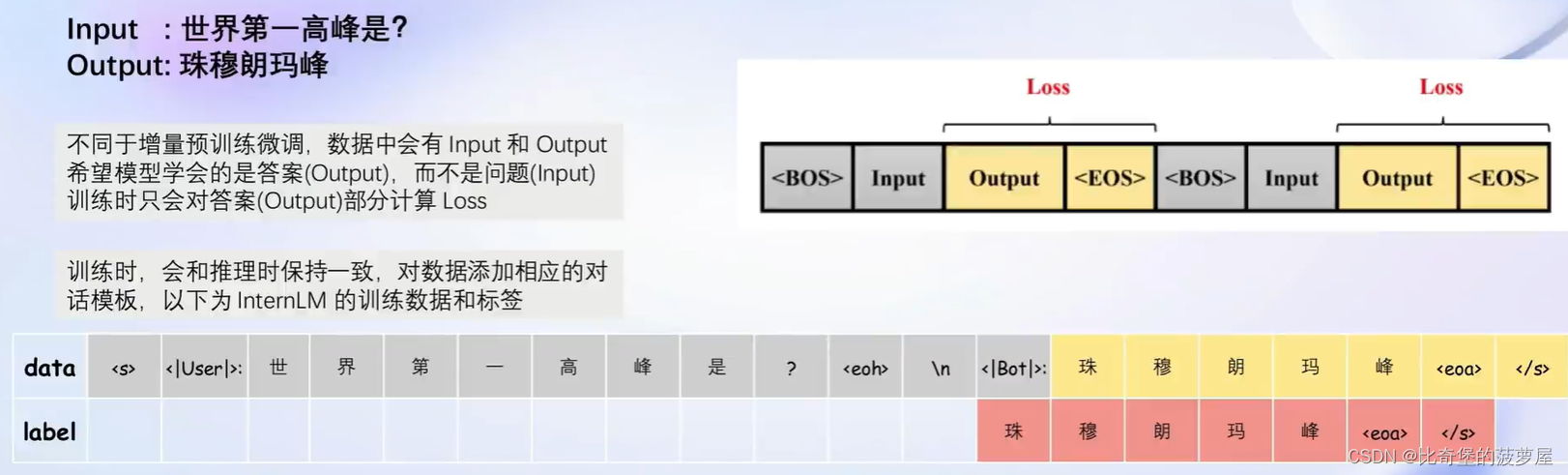
1.3增量预训练微调:
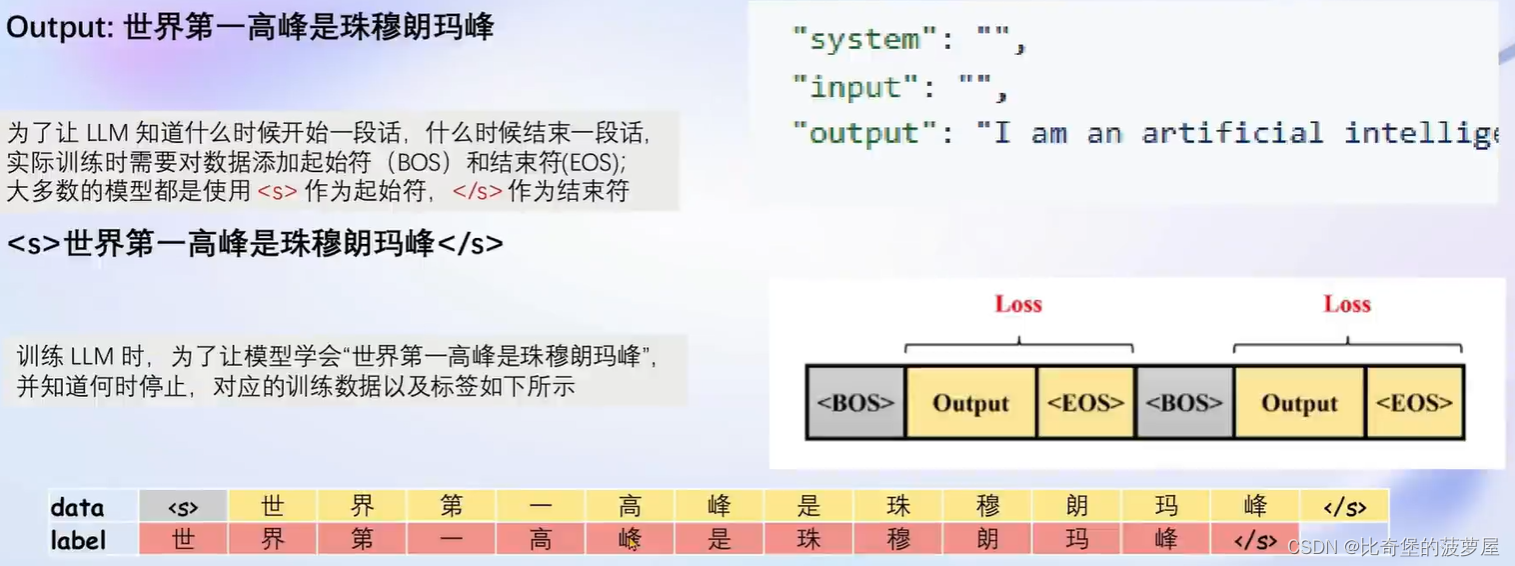
增量预训练是在称述事实,并不是指令微调那种一问一答的形式,因此按照之前的模板,我们只需要把system和user角色内容留空,增量预训练的数据放入assistant的角色中。
1.4LoRA和QLoRA
在SD中LoRA可以换图片的风格,其实是在较大的基座模型的基础上套了一个LoRA模型,不同的LoRA会有不同的风格。应用到这里就是我们可以不用花费大量显存去动庞大的底座模型,以较小的开销达到我们的目的。
全参数微调LoRA和QLoRA的对比:
全参数微调:
全参数模型及其优化器全部加载到显存当中,对显存消耗较大。
LoRA:
模型、LoRA的优化器加载即可
QLora:
4 bit 不精确加载,QLora优化器还可以在CPU、GPU上换。


二、XTuner介绍:
0基础的非专业人士也可以使用的微调框架,对显存需求较少(最小8GB)
1.多生态适配

2.集成化微调工具
总体使用步骤:
1.安装
pip install xtuner2.挑选配置模版
xtuner list-cfg -p internlm_20b3.一键训练
xtuner train internlm_20b_qlora_oasst1_512_e3其中各部分分别代表: xtuner train-模型名称-使用算法-数据集-数据长度-epoch
4.对话
xtuner chat internlm/internlm-chat-20b (--bits 4) --adapater $ADAPTER_DIR微调后生成的是adapter文件,加载adapter模型对话
5.其他工具类模型可以去仓库查看:
HuggingFace Hub (xtuner/Llama-2-7b-qlora-moss-003-sft)
3.数据流处理工具
xtuner内置了多种热门数据集和对话模板的映射函数,使得开发者可以更加专注于数据内容,不必花费精力处理复杂数据格式。


三、8GB显存玩转LLM

俩种优化方式可以大幅度降低显存消耗。
四、internLM2 1.8B模型

五、多模态LLM
1.多模态LLM原理简介(安装电子眼)
文本单模态和文本+图像的多模态的工作流程:
从单模态到多模态的训练过程主要是在训练image projector

2.LLaVA方案简介(电子眼型号)
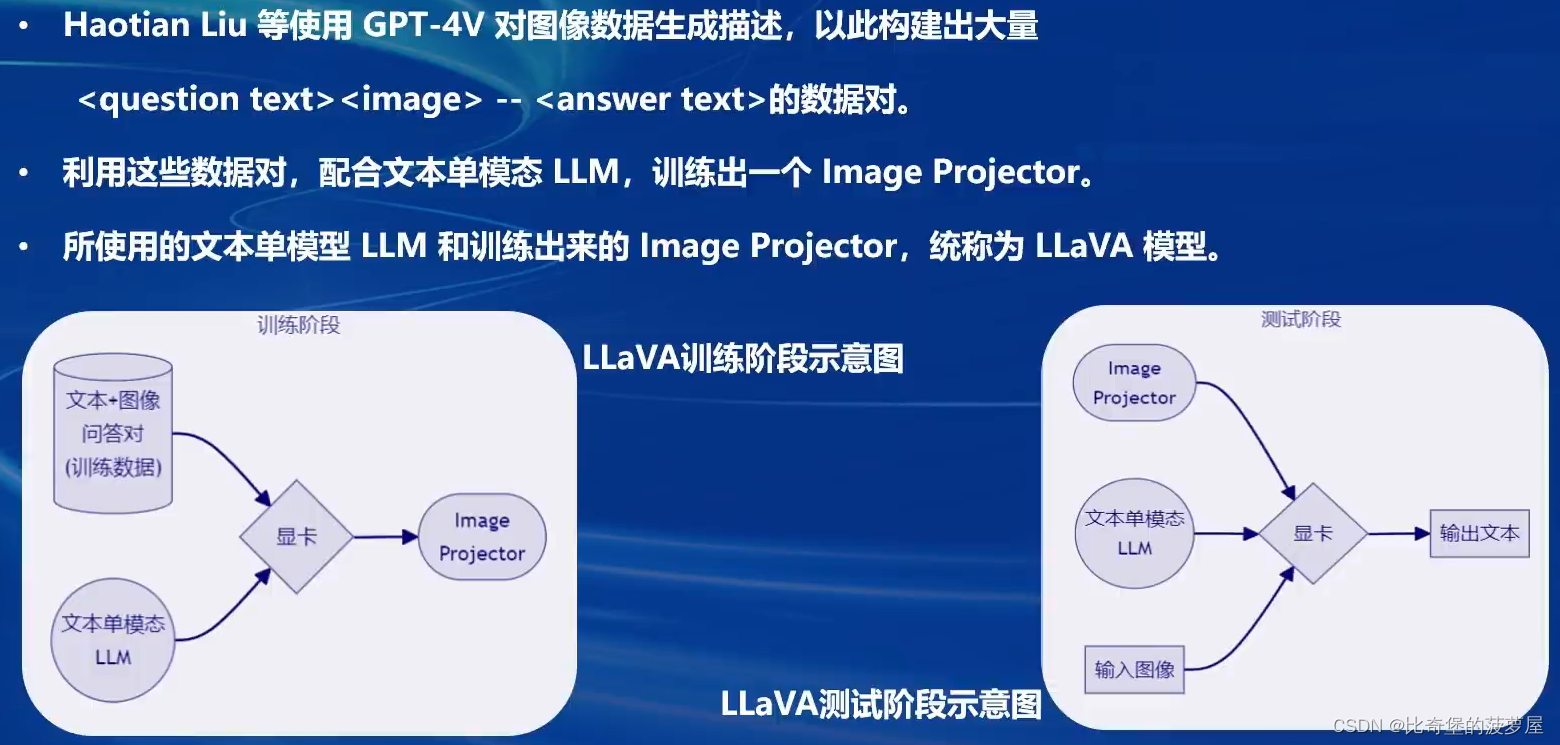
image projector的训练和测试,类似于LoRA微调方案。二者都是在已有的LLM基础上,用新的数据训练一个新的小文件。只不过,LLM套上了LoRA之后,有了新的角色,而LLM套上image projector之后,才有了眼睛。
3.internLM2_Chat_1.8B + LLaVA(使用方法)
预训练阶段数据是网络爬取数据,目的是为了让单模态文本模型的到图像的描述或者标签。(属于增量预训练)
微调阶段使用的是高质量监督数据。(属于指令微调)
















 2288
2288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









