






机器学习第十二周周报
摘要
本周学习了Non-Autoregressive Generation,对比了Autoregressive Sequence Generation和Non-Autoregressive Sequence Generation,学习了NAT的概念,了解了部分NAT模型的机制,NAT模型打破了生成时的串行顺序,希望一次能够解码出整个目标句子,从而解决AT模型所带来的问题。
Abstract
This week, I learned Non-Autoregressive Generation, compared Autoregressive Sequence Generation and Non-Autoregressive Sequence Generation, learned the concept of NAT, and learned the mechanism of part of the NAT model. The NAT model breaks the serial order of generation, hoping to decode the whole target sentence at one time, so as to solve the problems caused by the AT model.
一、Non-Autoregressive Generation
1.介绍
所谓的Autoregressive Sequence Generation就是从左到右的一个个的生成token。Non-Autoregressive Sequence Generation则是同时生成,下面来看一下典型的Autoregressive Sequence Generation模型:
RNN,逐个的吃token,然后生成token的时候是生成下一个token的时候要参考当前时间步的token,因此,无论是输入和输出都比较花费时间。
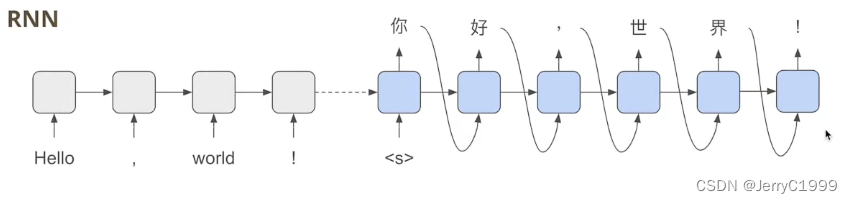
后来有了BERT,这个时候就可以用BERT替换输入模块,这个时候可以直接一次把所有的输入都吃进来,不用一个个的吃,输入的速度是解决了,但是输出还是和RNN一样,一个个的往外吐:
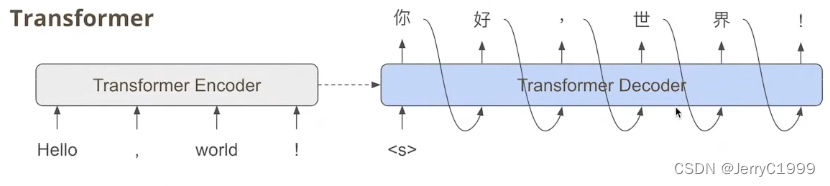
因此,就想能不能把输出也改成直接吐所有的token的模式,这个就是Non-autoregressive model的目标。
要实现上面提出的目标,有难度,借用之前学习的一个例子来说:
有一个Text-to-lmage的任务,就是给一段文字,然后模型为文字配一个图片,传统使用有监督的方式进行训练。
假如我们给出的文字是【train】,然后由于数据库中的ground truth有很多火车的图片,那模型就犯傻了,要想和所有有火车的图片都as close as possible怎么办?只能把所有火车图片都拿过来求平均,然后计算一个相似的结果。最后的的结果就是模糊不清的,模型又想像这张图片,又想像那张图片。
究其原因就是在模型的输出层上,各个神经元之间没有相互联系(No dependency on output structure),例如下图的第二神经元在输出ink的时候,它并不知道邻居神经元产生什么东西。
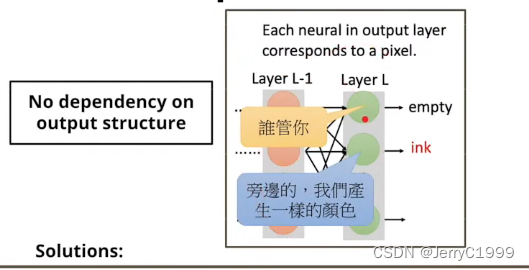
解决这个问题可以用Autoregressive model,ex: PixelRNN;另外还可以用GAN,使用GAN的discriminator来判别生成的图片是否真实,使得Generator学会生成清晰,真实的图片。
另外一个原因就是没有隐变量来控制生成结果的,例如上面已经知道,ground truth有70%几率来做白灯火车,30%几率来自黑灯火车,但是在生成结果的时候输出层并没有根据这个比例来进行生成数据。
对于整个问题,Autoregressive model也是有解决方法的,因为每个时间步中,Autoregressive model都是pick当前时间步输出分布中几率最大那个,而GAN也在输入的时候要吃一个正态分布,就是要使得输出有一个确定的方向。

2.Vanilla NAT (Non-Autoregressive Translation)
这个是第一篇用在翻译上的论文这个文章提出了几个trick,来改进Non-Autoregressive模型
(1)Fertility
这个trick就是在encoder部分加入输入单词对应的翻译结果的长度,例如,下图中的2121表示【Hello】翻译后对应2个token,【,】对应一个token,以此类推:
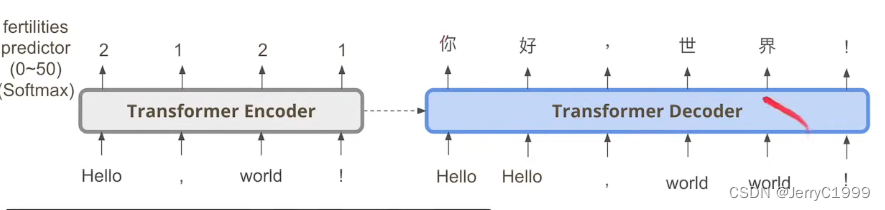
这个做法可以使得在句子层面对翻译这个任务进行提前布局,例如:
2121和1121分别对应的结果是:
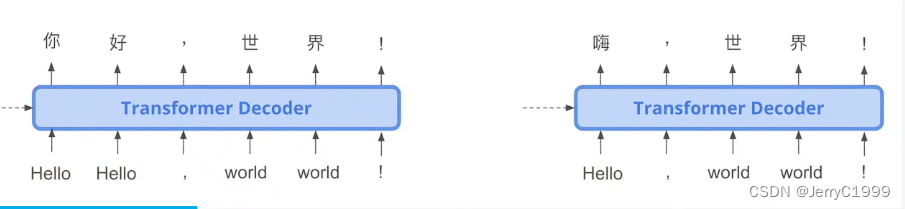
Fertility的训练有两种方法:
- Labels comes from external aligner.使用外部的aligner工具,这个工具会自动给出翻译结果对应原文的哪些字
- Observing attention weights in auto-regressive models.直接训练一个seq2seq的auto-regressive model,然后看其attention权重如何分布,就可以看出输出结果对应输入的哪个字。这个方法用在翻译上比较多。
由于Fertility模型目标和NAT模型目标不一样的,因此,需要在NAT模型训练好之后,用REINFORCE的方式对fertility classifier进行Fine-tune。
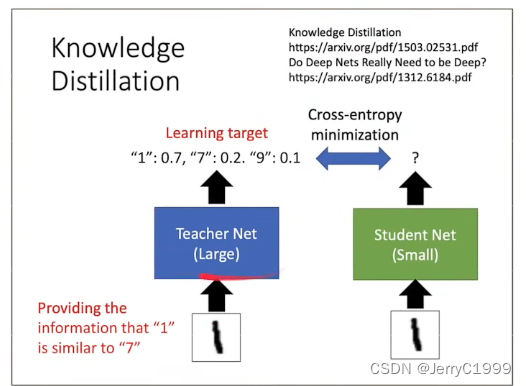
(2)Sequence-level knowledge distillation
knowledge distillation在之前的学习中学习过,就是有一个比较小的模型(绿色),这个模型训练是以另外一个大的模型(蓝色)为老师,两个模型吃相同的输入,然后大的模型已经训练好了,这个时候有一个输出,小模型的目标是输出和大模型的输出交叉熵最小化。
(3)Noisy Parallel Decoding (NPD)
首先给出不同的fertility的组合,那么这些不同的组合会使得生成的结果也不一样,然后把生成出来的不同结果丢进Autoregressive Decoder中,让Autoregressive Decoder判断哪个结果最好
这里注意,Autoregressive Decoder判断的过程不需要一个个的token进行,全部只需要一个时间步就可以搞定。
计算出每一个token对应的几率,然后把这些几率乘起来,就得到整句话的几率。
3.Evolution of NAT
(1)Vanilla NAT
a. Gu et al., ICLR′18
(2)Iterative Refinement
a. iNAT, Lee et al, EMNLP18
b. Mask-Predict, Ghazvininejad et al., EMNLP′19
这个算法的思想是在一次性输出某句话后,再把输入拿过来,重新迭代的对输出进行修正(下图中的红箭头),但是注意,这个方法在第一次的输出之后,对其进行修正时输出的长度是不变的,而是把对应的输入进行copy
(3)Insertion-based
a. Insertion Transformer, Stern et al., ICML’19
b. KERMIT, Chan et al, arXiv19
这个算法针对算法2中输出长度不能变化的缺点,设定了可以对输出进行插入的设定,使得输出的长度可以变化。例如一句话是[A,B,C,D,E,F,G],这里先生成子序列[D],再插入[D]周围词,以此类推。
0→[D]→[B,D,F]→[A,B,C,D,E,F,G]
(4)Insert+Delete
Levenshtein Transformer, Gu et al., NeurIPS’19
算法3中只对输出进行插入,如果插入了错字就没有办法进行处理,因此这个算法加入了删除功能。
(5)CTC-based
a. E2E NAT w/ CTC, Jindrich Libovick et al., EMNLP’20
b. NAT w/ Latent Alignments, Saharia et al., arXiv’20
4.NAT with Iterative Refinement
可以看到,第一个Encoder先预测target length,然后按照长度进行copy,经过第一个decoder_1,得到第一个输出Y0,然后将Y0作为输入,经过decoder_2得到第二个输出,不断重复好几次这个过程。
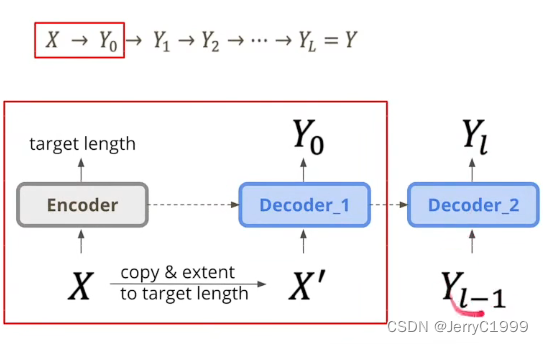
训练decoder_2可以将groud truth加入一些noise(将字进行重复,或者替换为随机字,或者交换顺序等),让decoder_2学习如何去噪。
5.Mask-Predict
在t=0时间步,先根据输入预测输出的长度,这里是6,那么就在Decoder(是BERT)中设置6个mask,然后BERT会得到第一版的翻译结果。
然后在t=1时间步,将第一版输出得到结果中几率比较低的字符替换为mask,再次丢入模型得到第二次输出。以此类推
6.Insertion Transformer
假设的输入有6个,因此其输出(粉色)也是6个,然后将这六个输出vector两两进行concat操作(紫色)
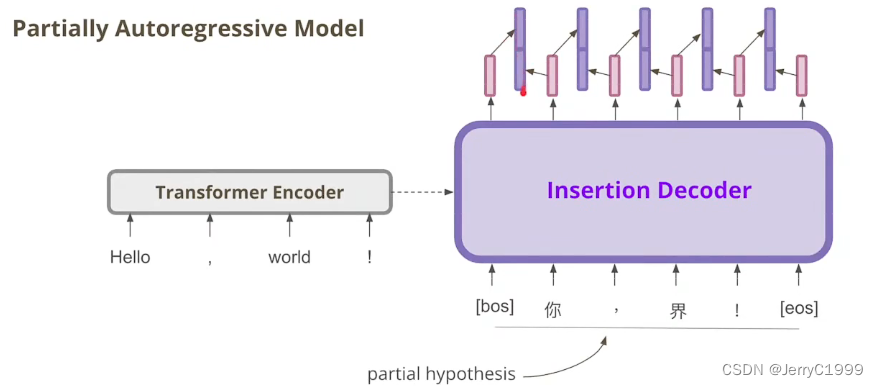
然后把concat的结果用来预测插入词。如果不需要插入则获得【end】(end of slot),如果得到字,就把字插入到原句子中。
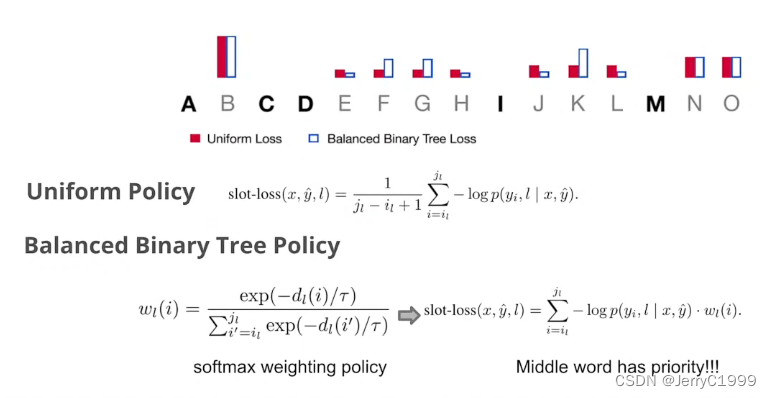
模型训练过程如下图所示,先将原句子打乱,然后随机给定一个数字,例如下图中是5,取前5个字,然后将前5个字还原回原句子的位置,其他去掉的字就形成了slots,然后就得到一个训练样本。将这个训练样本丢到模型,生成一个slot对应多个字符的情况有一个trick,这里不是为每个字符都给与相同的概率(下图中的红色),而是更加偏向生成中间的字符(下图中的蓝框),因为每次都生成中间的字符,这样整个生成过程就会按Binary tree那样效率高。
7.Levenshtein Transformer
这个模型是在插入的基础上加入了删除功能,模型如下图所示:
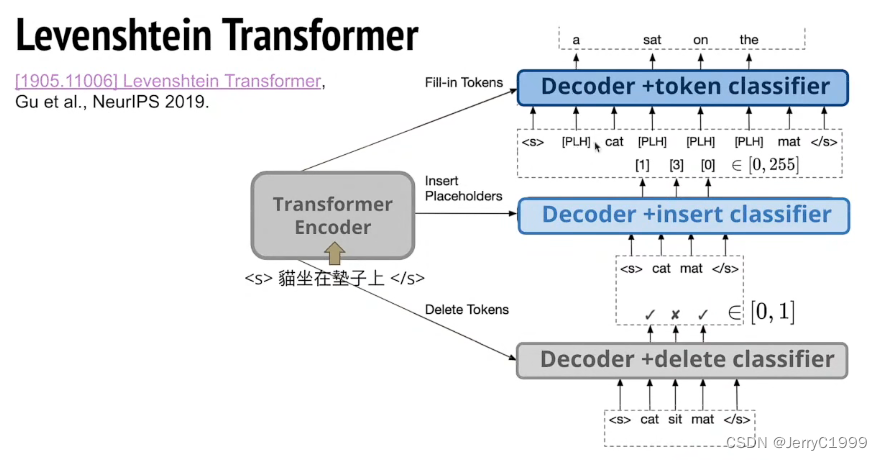
可以看到输入经过encoder之后得到初始的输出要经过三个Decoder:
第一个Decoder是一个删除分类器,判断是否需要删除当前单词;
第二个Decoder是一个插入分类器,判断是否要在当前单词与单词之间插入单词,如果插入则生成一个占位符【PLH】place holder;
第三个Decoder是token分类器,根据【PLH】的位置预测对应的单词。
这个模型训练就是采用上面提到的从另外一个模型学习的方法(knowledge distillation)。具体算法称为:Levenshtein Distance Algorithm
举例:
>>> import Levenshtein
>>> Levenshtein.distance("ABCEFGHJJ", "ABCDEFGHI")
3
>>> Levenshtein.editops("ABCEFGHJJ", "ABCDEFGHI")
[('insert', 3, 3), ('delete', 7, 8), ('replace', 8, 8)]
这个文章的算法中把最后的replace分解为删除和插入操作。
训练过程如下:
先生成一系列需要删除单词的句子ydel,这个只要将正常句子中单词替换一些就可以;
再生成一系列需要插入单词的句子yins,这个只要将正常句子中单词删除一些就可以。
有了上面的数据集后,就可以按下面的模型进行训练:

例如第一个句子输入模型,根据Levenshtein Distance Algorithm看的正确答案,第三个单词要删除,其他单词保持不变;第二个句子输入模型,根据Levenshtein Distance Algorithm看的正确答案,要在第二空位插入2个单词(第一个空位是<s>和This这两个单词中间);最后一个句子就不用说了。
8.CTC
这个模型之前有学过
- CTC也是Non-Autoregressive模型,只不过用在语音识别上;
- 语音识别没有multi-modality问题,就是一段语音对应多个结果。
但是这个模型有两个缺点:
- 虽然效果还不错,但是比不过seq2seq模型LAS;
- 语音经过Encoder之后得到的文字数据,不能再次经过refine操作进行修改,只能Encoder一次。例如下面红色明显是输出错误了,但是模型也无力回天。
9.Imputer
为了解决CTC的缺点,2020年研究人员提出了一个叫Imputer 的模型,这个模型结合了:CTC+Mask-Predict几种技术。
这个模型在t=0时刻会将一个与语音信号等长的Mask序列与语音信号丢入encoder中,得到一个初始化的输出,这个输出中可以还有Mask和确定结果
在t=1时刻,把上一个时间步得到序列结果在和语音信息重新进入Encoder,进行refine
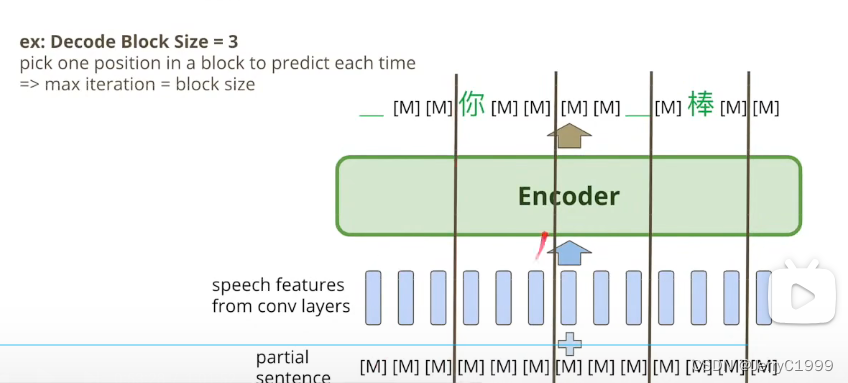
不断迭代直到输出没有变化为止。这个模型还有一个trick,叫:Block Decoding,将输入序列划分成一个个的block,并规定每个block在迭代过程,必须至少确定一个结果,下面是一个block size=3的例子:
10.总结
本周学习了部分NAT模型,下周将继续学习其他模型。














 60
60











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









