






机器学习第十四周周报
摘要
GAN网络全称generative adversarial network,是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中两个模块,即生成模型和判别模型的互相博弈学习产生相当好的输出。本周将继续上周的对GAN的学习。
Abstract
The full name of GAN network is generative adversarial network, which is a deep learning model and one of the most promising methods of unsupervised learning in complex distribution in recent years. The model produces a good output through the mutual game learning of the two modules in the framework, which are the generation model and the discriminant model. This week will continue last week’s study of GAN.
一、GAN
1.conditional GAN
Conditional GAN是跟着discriminator来进行学习的,要注意的是:在做Conditional GAN时跟一般的GAN是不一样的。在上周讲一般的GAN时,discriminator是输入一张图片,然后判断它好还是不好。现在在Conditional GAN的情况下,discriminator只输入一张图片会遇到的问题是:对于discriminator想要骗过generator太容易了,它只要永远产生好的图像就行了。举例来说,永远产生猫就可以骗过discrimination(对于discriminator来说那只猫是好的图片),然后就结束了。Generator就会学到不管现在输入什么样的文字,就一律忽视,都产生好的图片。如果discrimination只看产生出来的image,那么就产生出来的image骗过它。但是输入的文字就一纪律无视它,这显然不是我们想要的。
在进行Conditional GAN时往往有两个输入,discriminator应该同时看generator的输入(文字)和输出(图像),然后输出一个分数,这个分数同时代表两个含义。第一个含义是两个输入有多匹配,第二个含义是输入图像有多好。
训练discriminator时要给它一些好的输入,这些是要给高分的。在Conditional GAN的例子里面有文字与图像之间的关系,就可以从datasets里面sample出文字与图像,告诉discriminator看到这些文字和图像应该给出高分。
按照我们在第一部分GAN的想法,我们可能就是把文字输入generator,产生一些图像,这些文字和generator产生出来的图像要给予低分。光是这么做discriminator会学到判断现在的输入是好还是不好,不管文字的部分只管图像的部分,这显然不是我们想要的。所以在做Conditional GAN时,要给低分的case是要有两种。一个是跟一般的GAN一样是用generator生成图片,另外一个是从资料库里面sample出一些好的图片,但是给这些好的图片一些错误的文字。这时discriminator就会学到:并不是所有好的图片都是对的,如果好的图片对应都错误的文字它也是不好的。这样discriminator就会学懂文字与图像之间应该要有什么样的关系。

2.Unsupervised Conditional GAN
刚才在说Conditional GAN时我们需要输入和输出之间的对应关系,但是事实上有机会在不知道输入和输出之间的对应关系的情况下,可以教机器咋样将输入的内容转化为输出。这个技术最常见到的应用是风格转化。
接下来我们要讲的技术是Cycle GAN,Cycle GAN想要做的事情是:训练一个generator,输入doamin X(真实的画作),输出是梵高的画作。除了训练一个generator还需要训练一个discriminator,discriminator做的事情是:看很多梵高的画作,看到梵高的画作就给高分,看到不是梵高的画作就给低分。
generator为了要骗过discriminator,那我们期待产生出来的照片像是梵高的画作,光是这样做是不够的,因为generator会很快发现discriminator看的就是它的输出,那么generator就直接产生梵高的画作,完全无视输入的画作,只要骗过discriminator整个训练就结束了。

为了解决这个这也问题我们还需要再加上一个generator,这个generator要做的事情是根据第一个generator的输出还原原来的输入(输入一张Domain X,第一个generator将其转化为Domain Y的图,第二个generator在将其还原为Domain X,两者越接近越好)
现在加上了这个限制,第一个generator就不能够尽情的骗过discriminator,不能够直接产生梵高的自画像。如果直接转换为梵高的自画像,那么第二个generator就无法将梵高的自画像还原。所以第一个generator想办法将Domain ,但是原来图片最重要的资讯仍然被保留了下来,那么第二个generator才会有办法将其还原。输出跟输入越接近越好,这件事叫做Cycle consistency。
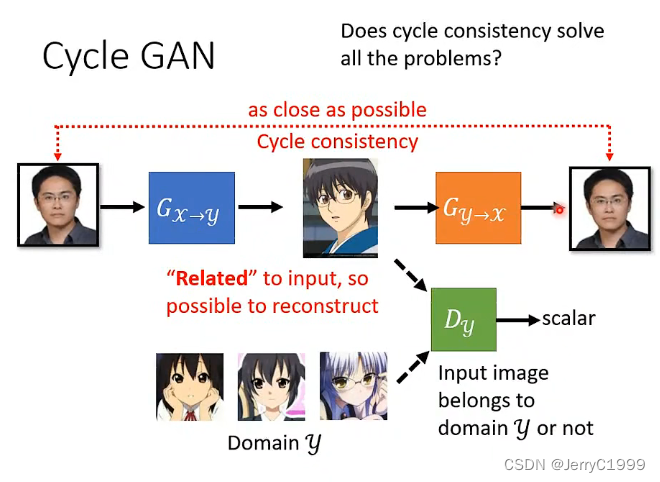
同样的技术不只是用在影像上,可以应用在其它领域上。举例来说:假设Domain X和Domain Y分别是不同人讲的话(语音),那就可以做语音的风格转换。假设Domain X和Domain Y是两种不同的风格文字,那就可以做文字的风格转化。假设我们把Domain X替换成负面的句子,将Domain Y换成正面的句子,我们就可以训练一个generator,可以将负面的句子转换为正面的句子。
如果直接将影像的技术套用到文字上是会有些问题,如果generator在做文字风格转换的时候,输入是一个句子,输出也是一个句子。如果输入和输出分别是句子的话,这时应该使用Seq2seq model作为网络架构。在训练时仍然很期待使用Backpropagation将Seq2seq和discriminator串在一起,然后使用backpropagation固定discriminator,只训练generator,希望输出的分数越接近越好。
但在文字上没有办法直接使用bachpropagation,因为Seq2seq model输出的是离散的。原来我们将generator的输看做是一个巨大network的hidden layer,那是因为在影像上generator的输出是连续的,但是在文字上generator的输出是离散的(不能微分)。
Unsupervised Conditional GAN其实除了风格转换以外还可以做其它的事情,比如说:Unsupervised 语音辨识。我们在做语音辨识时通常supervised,也就是说我们要给机器一大堆的句子,还要给除句子对应的文字是什么,这样的句子收集上万小时,然后期待机器自动学会语音辨识。但是世界上语言有7000多种,其实不太可能为每一种语言都收集训练资料。
所以能不能想象语音辨识能不能是Unsupervised的,也就是说我们收集一大堆语言,一大堆文字,但是我们没有收集语言跟文字之间的对应关系。机器做的就是听一大堆人讲话,然后上面读一大堆文章,然后期待机器自动学会语音辨识。
二、GAN理论
1.基于Maximum Likelihood Estimation的生成

以人像图片生成为例:
x是一个高维向量表征一张人像图片,假设在二维空间中存在一个区域为人像图片的空间(image space),用pdata表示,那么x在这一小部分的空间内的概率更大,而在其它部分的概率更小。
在GAN之前,大部分使用监督训练的方式通过Maximum Likelihood Estimation(极大似然估计)来估计pdata分布,具体做法如下:

通过下述理论推导,我们可以得到上述MLE的过程本质上是在最小化pdata和pG之间的KL Divergence:
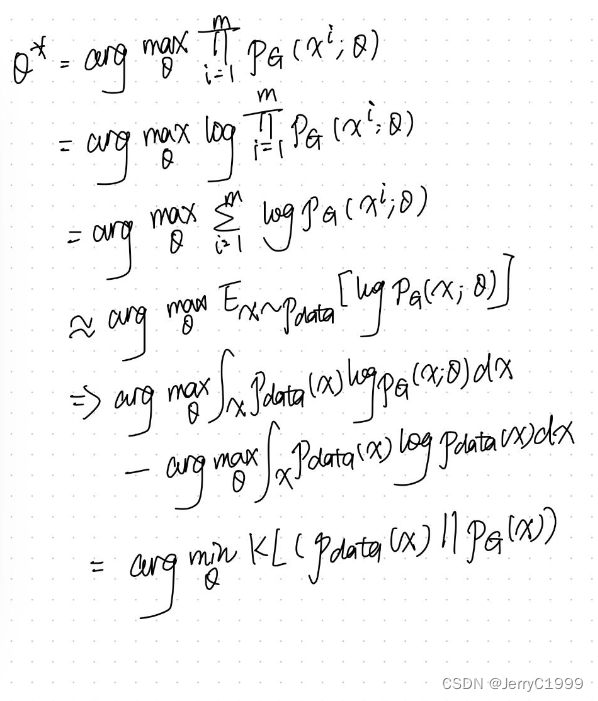
如果pG是高斯模型,则有可能求出它的似然函数,从而能够最小化它与pdata之间的KL Divergence,但是如果是比较复杂的分布(例如使用Neural Network表示),则没办法通过MLE求解。这时,Adversarial Net的提出就可以解决Generator是一个network的情形。















 1062
1062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









