






机器学习第八周周报
- 摘要
- Abstract
- 一、RNN
- 1.Slot Filling
- 2.Recurrent Neural NetWork(RNN)
- 3.Bidirectional RNN
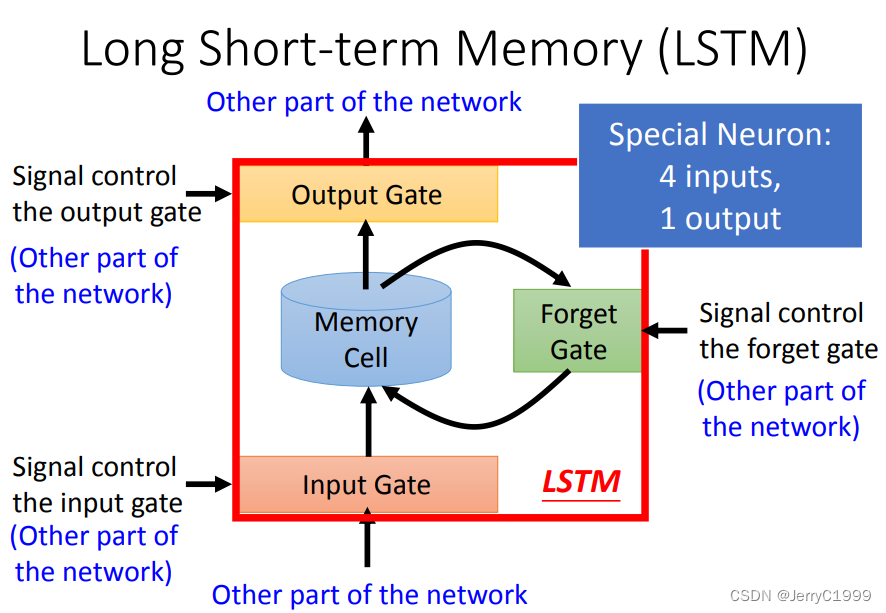
- 4.Long Short-term Memory (LSTM)
- 5.Learning Target
- 6.RNN的问题
- 7.Helpful Techniques
- 8.Many To One
- 9.Many To Many (Output is shorter)
- 10.Many to Many (No Limitation)
- 11.Beyond Sequence
- 12.Sequence To Sequence Auto Encoder
- 13.RNN vs Structured Learning
摘要
循环神经网络是一类以序列数据为输入,在序列的演进方向进行递归且所有节点按链式连接的递归神经网络。循环神经网络具有记忆性、参数共享并且图灵完备,因此在对序列的非线性特征进行学习时具有一定优势。循环神经网络在自然语言处理,例如语音识别、语言建模、机器翻译等领域有应用,也被用于各类时间序列预报。引入了卷积神经网络构筑的循环神经网络可以处理包含序列输入的计算机视觉问题。
Abstract
Recurrent Neural Network is a kind of recursive neural network which takes sequence data as input, recurses in the direction of sequence evolution and all nodes are connected by chain. Recurrent Neural Network has the characteristics of memory, parameter sharing and Turing completeness. So it has certain advantages in learning the nonlinear characteristics of sequences. Recurrent Neural Network is applied in natural language processing, such as speech recognition, language modeling, machine translation and other fields, and it is also used in all kinds of time series prediction. The Recurrent Neural Network constructed by convolution neural network can deal with the computer vision problem including sequence input.
一、RNN
1.Slot Filling
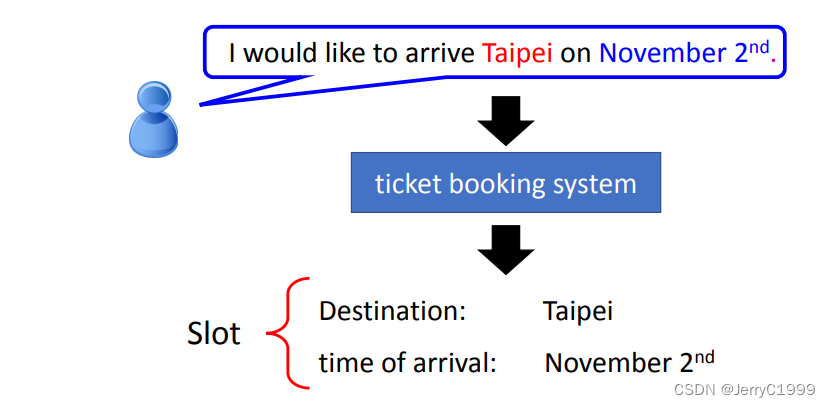
想实现这个效果,最简单的想法就是,直接将词汇转化为向量传给一个全连接网络,输出是词汇属于每个 Slot 的概率
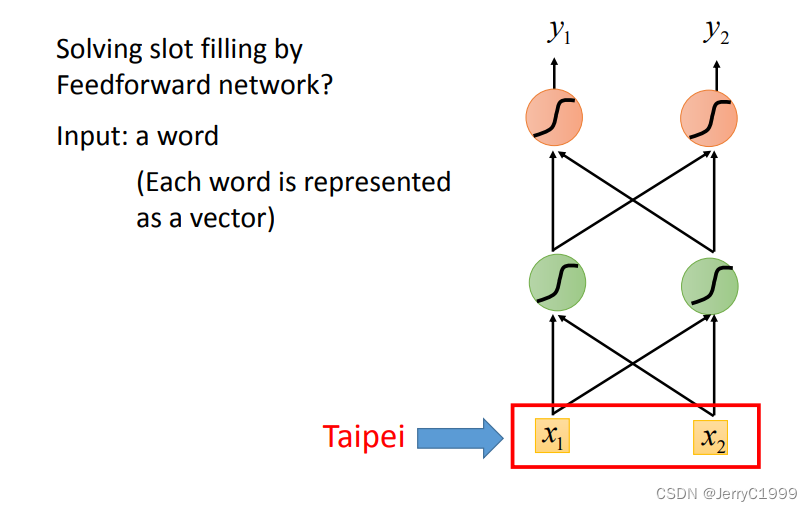
那么怎么将词汇转化为向量呢?
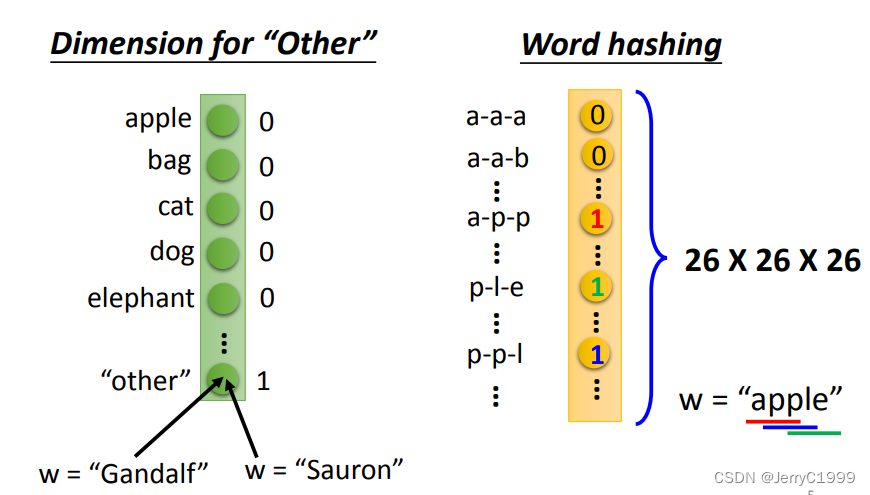
可以用1-of-N Encoding,1-of-N Encoding中有一个存有很多词的词典,然后我们可以用类似one-hot编码的方式根据词典将词汇转化为向量

使用单纯使用全连接网络的方法解 Slot Filling 问题会出现下图所示的问题。第一句话中的“Taipei”是目的地,但是第二句话中的“Taipei”却是出发地。两个完全相同的单词在不同的语句中,却应该属于不同的 Slot,这相当于要让模型在输入相同词汇的情况下有时候输出目的地,有时候输出起始地。
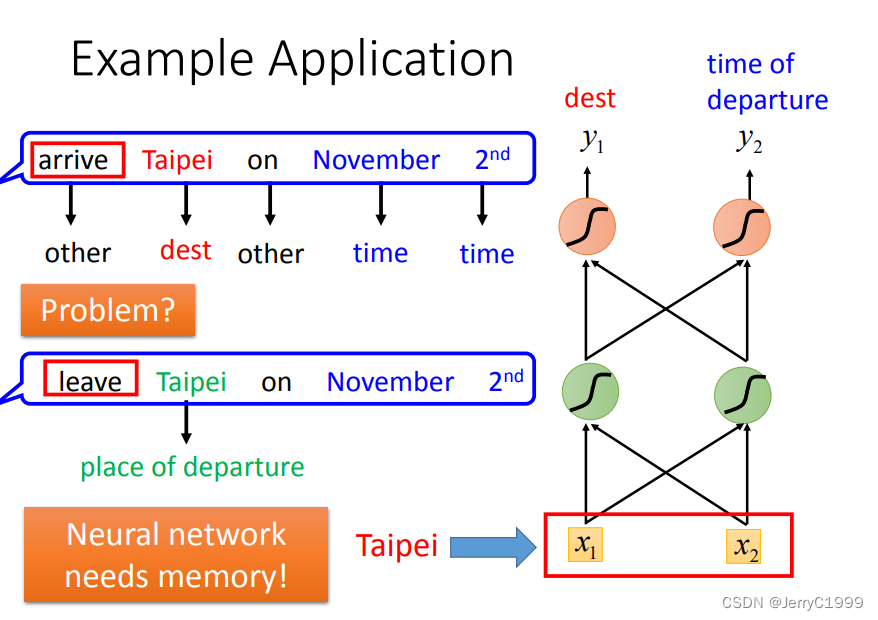
有没有方法可以让神经网络具有“记忆力”,即可以记住一些上下文的咨询,帮助模型更好地理解当前词汇,输出最符合语境的结果?
——Recurrent Neural NetWork(RNN),即循环神经网络
2.Recurrent Neural NetWork(RNN)
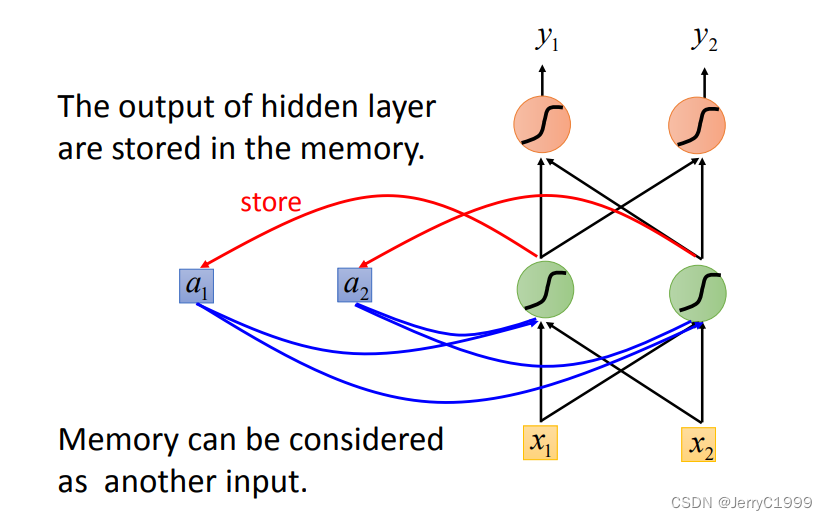
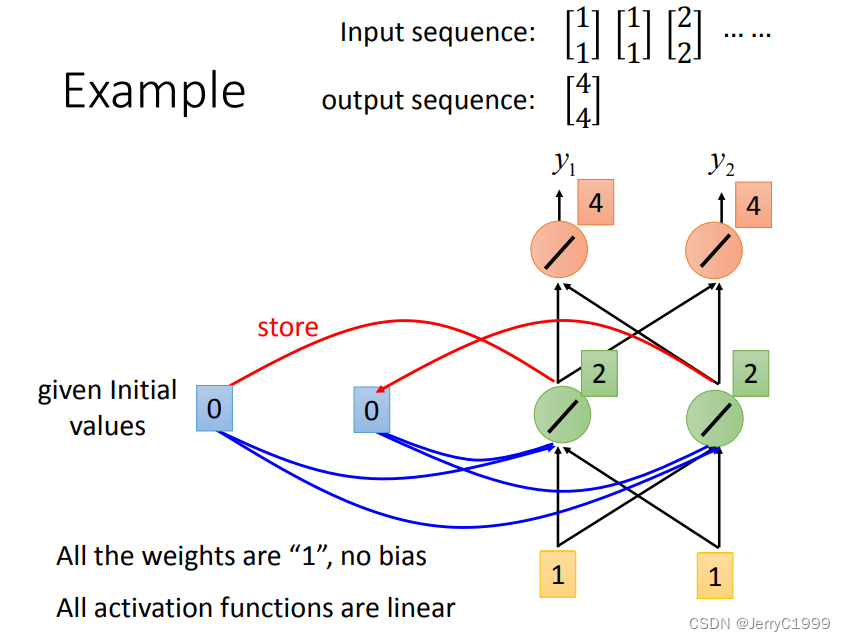
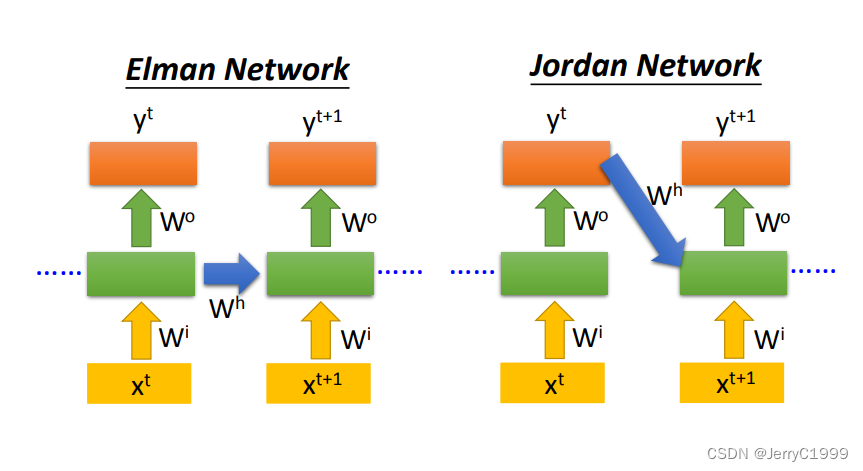
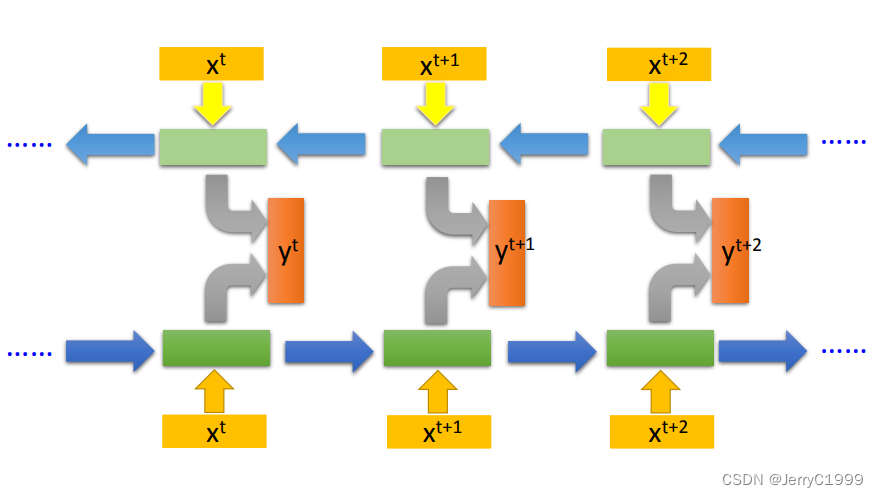
3.Bidirectional RNN
4.Long Short-term Memory (LSTM)
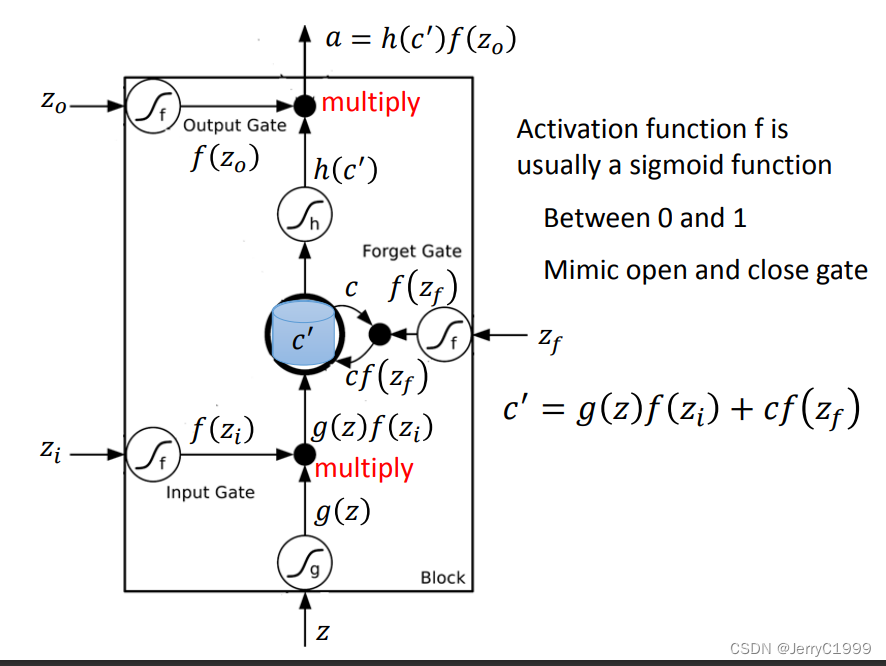
那么LSTM单元在神经网络单元里是怎么连接的?
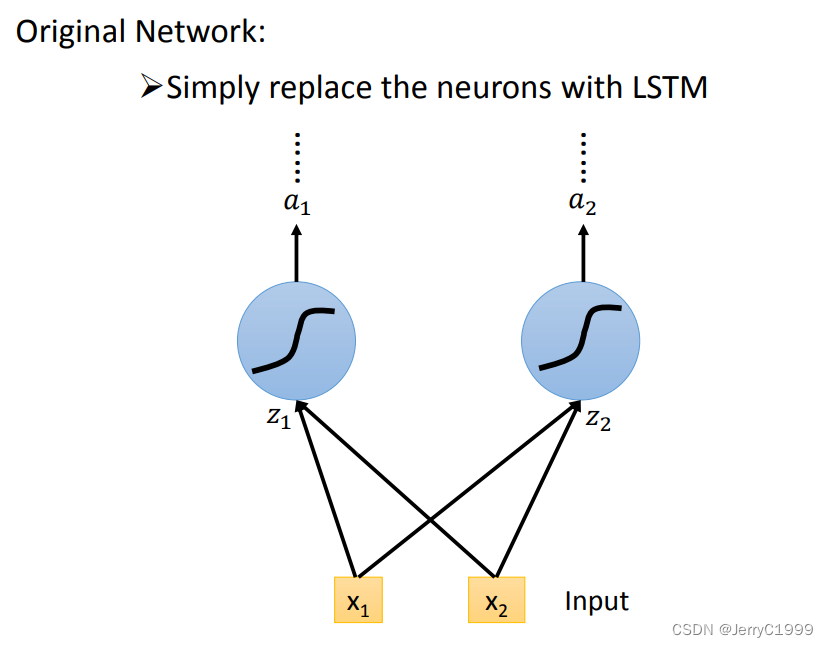
下面先看普通的神经网络神经元和输入之间的连接
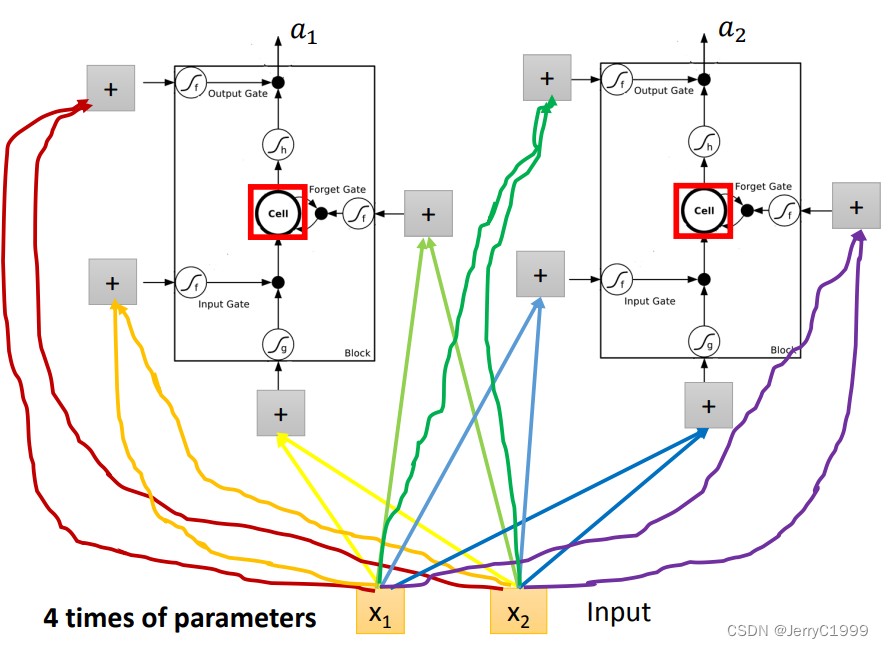
然后再把LSTM当作一个特殊的神经元,从下图我们可以看出,由于LSTM多出了三个门,所以输入需要额外地与LSTM进行3次连接,即LSTM需要4个Input,这也就意味着LSTM的参数量是普通神经元的4倍
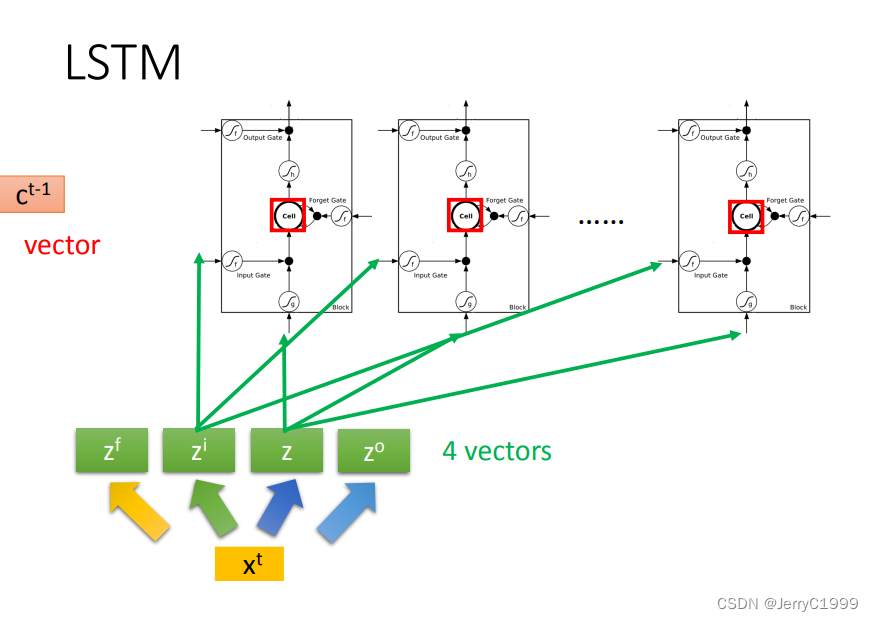
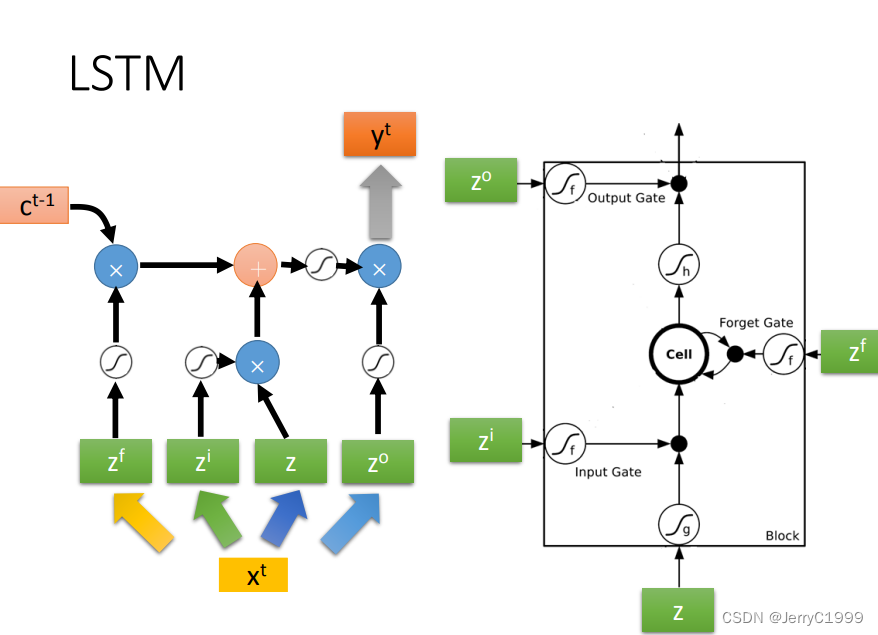
我们用结构图表示一下LSTM的传播流程:
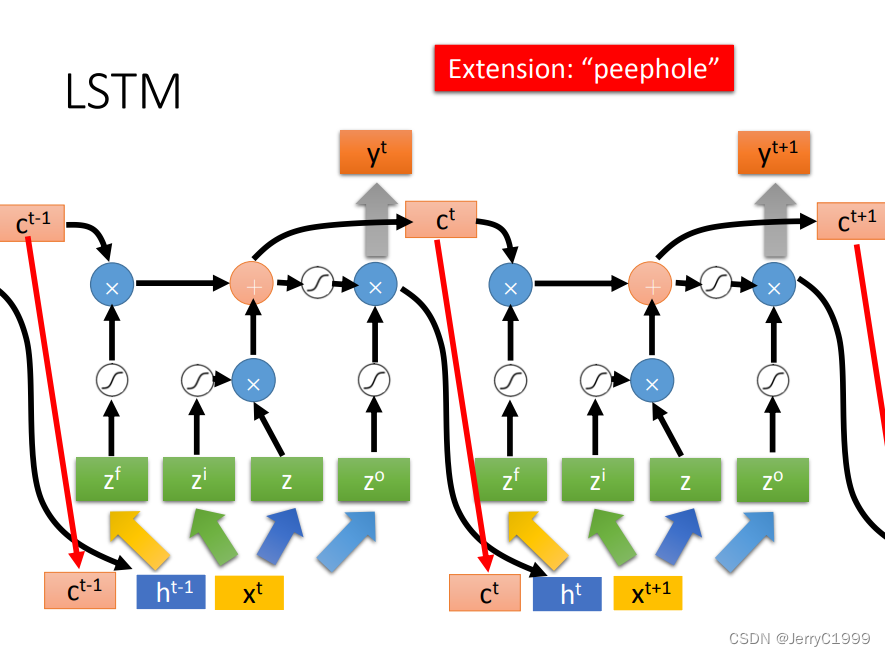
然后是同层之间,LSTM单元的连接,即不同词汇间的连接,记忆的传递
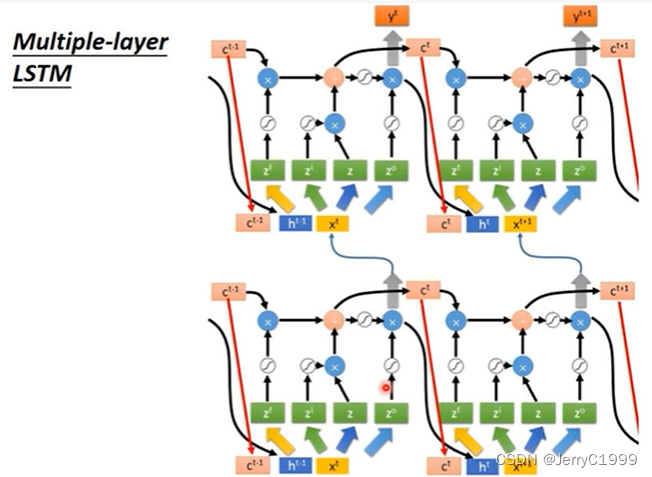
然后是多层的LSTM
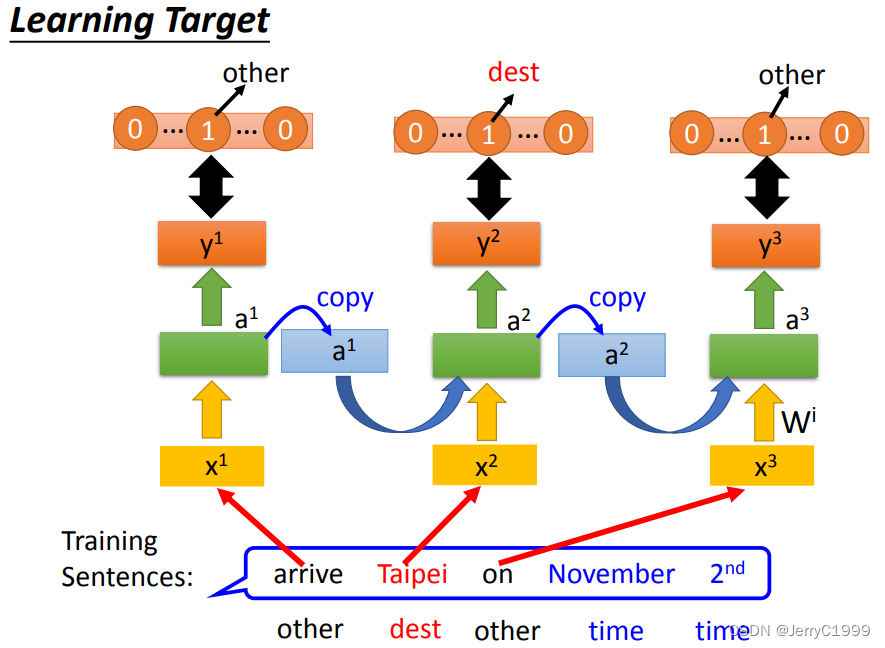
5.Learning Target
每个词汇都有一个概率输出,表示其属于每个Slot的概率。损失函数就用交叉熵损失。目标是使得预测整个语句的交叉熵总和最小。
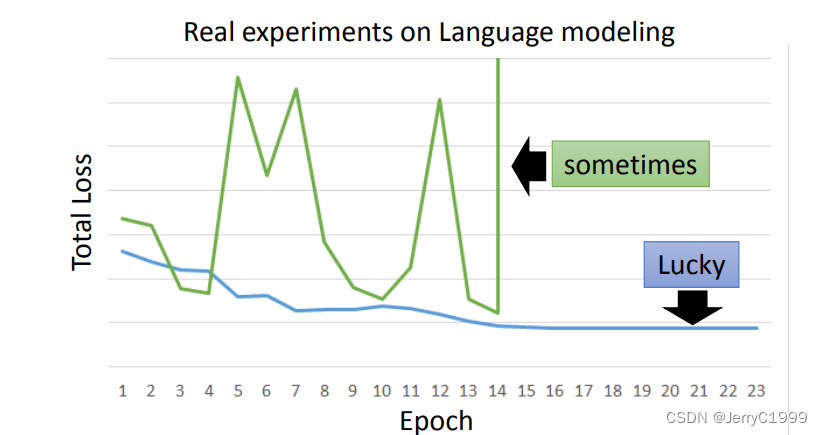
6.RNN的问题
RNN-based network is not always easy to learn
RNN是很难Train的,在RNN刚被提出时,很少有人能Train起来。其Loss曲线通常如下图绿线所示,蓝线是正常的Loss曲线。
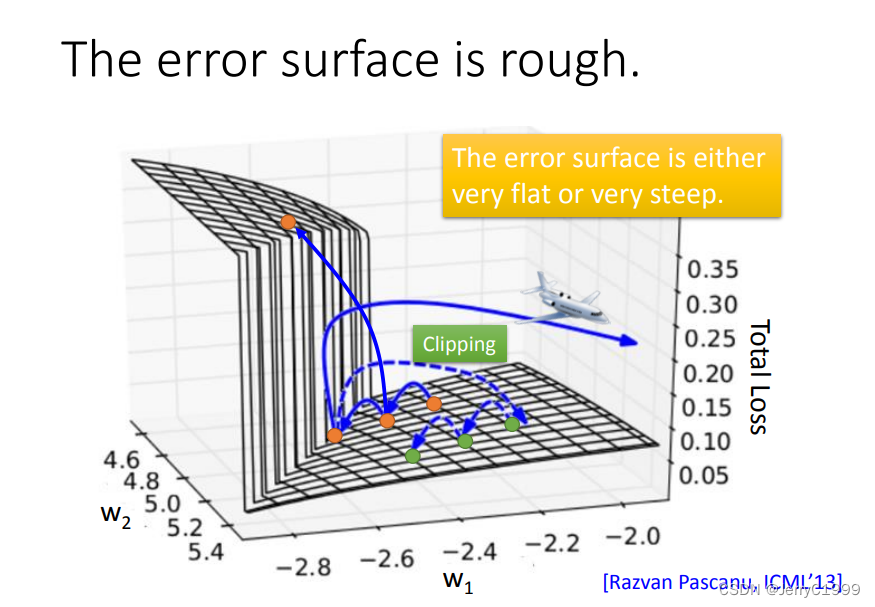
因为RNN的error surface的某些区域非常陡峭,在陡峭的区域,就可能导致参数只改动一点,却使得Loss产生巨大的变化。假设从橙色的点用gradient decent 开始调整参数两次,正好跳过悬崖,loss暴增;有时可能正好踩在悬崖上,悬崖上的gradient 很大,之前的都很小,可能learning rate就很大,很大的gradient 和learning rate就导致参数飞出去了。
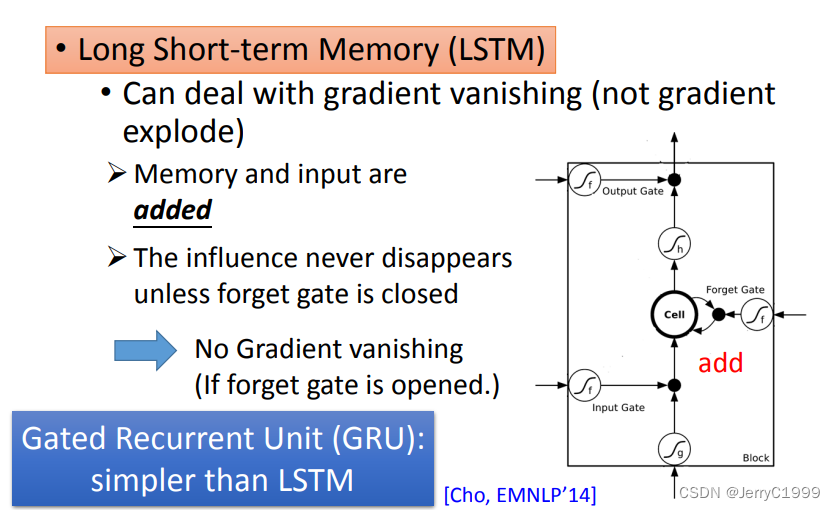
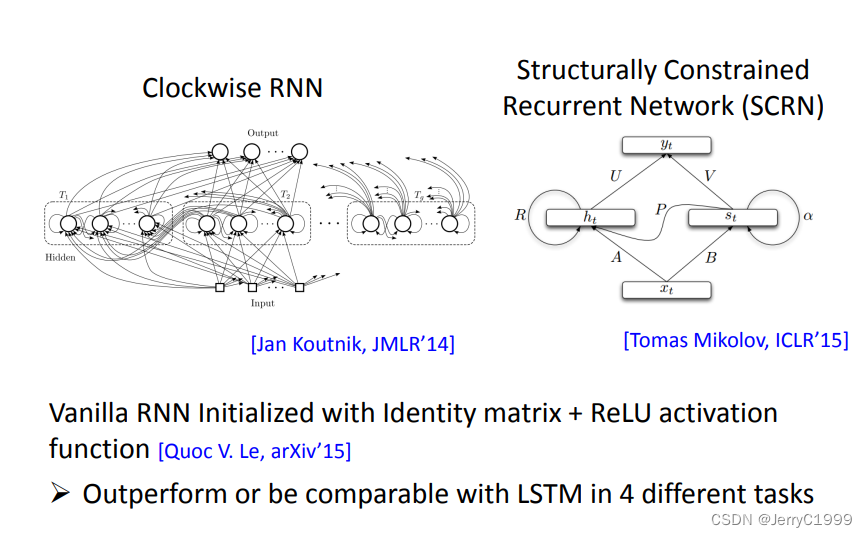
7.Helpful Techniques
(1)LSTM
RNN中,每个时间点,Memory里的咨询会被覆盖。但是在LSTM中,它的Memory是加权叠加性的,所以原来存在Memory里的值基本都会有所残留。
(2)GRU
GRU和LSTM一样,也可以解决该问题。
(3)其他
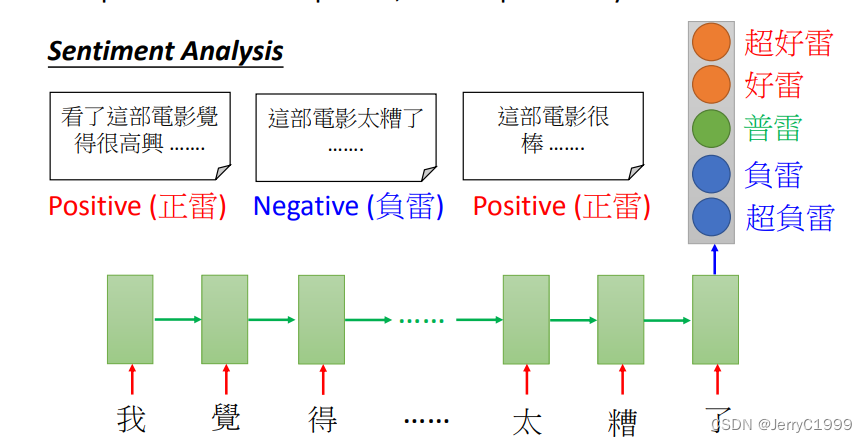
8.Many To One
Input is a vector sequence, but output is only one vector
(1)Sentiment Analysis
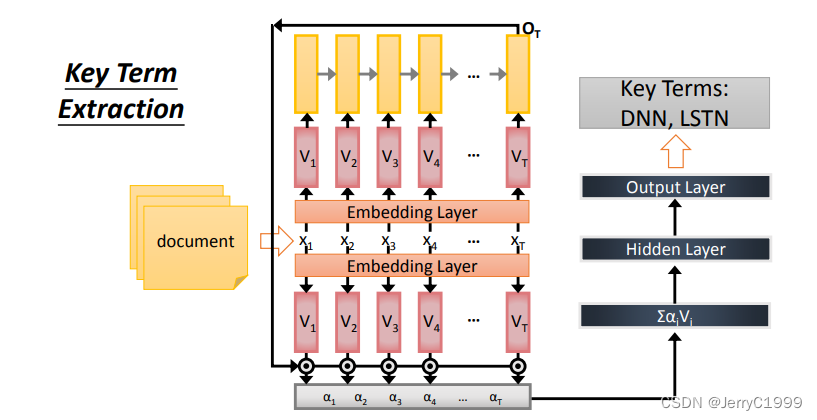
(2)Key Term Extraction
9.Many To Many (Output is shorter)
(1)Speech Recognition
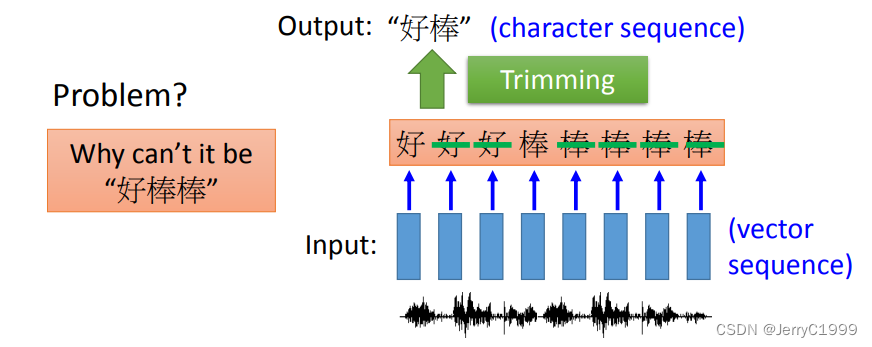
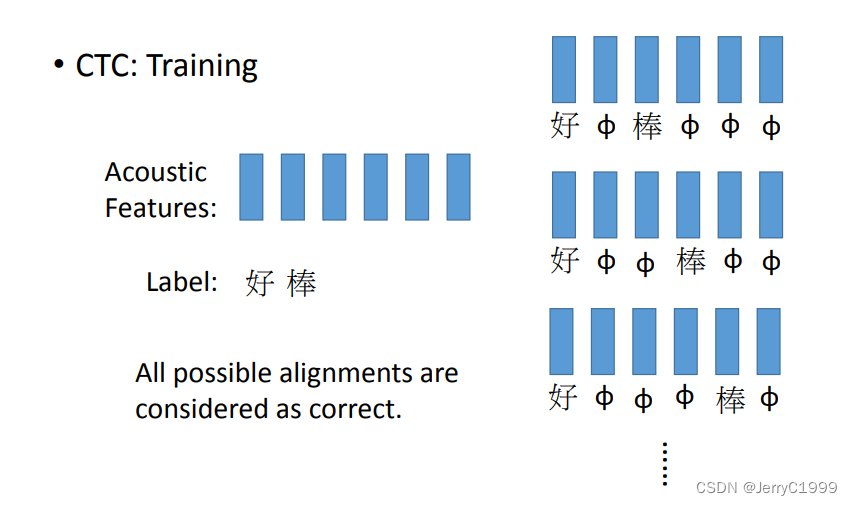
在用CTC法进行Train的时候,我们认为去掉代表空的符号之后是“好棒”的所有排列组合都是正确的
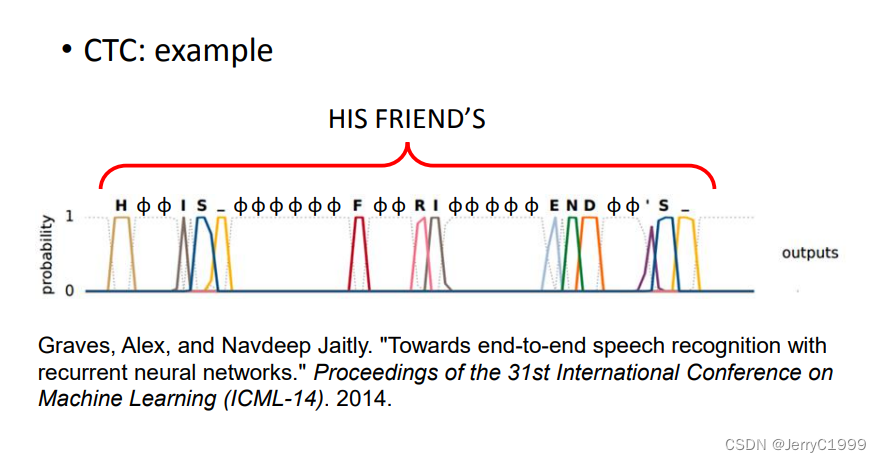
下面是一个CTC的例子,最终得到识别结果为 “HIS FRIEND’S”
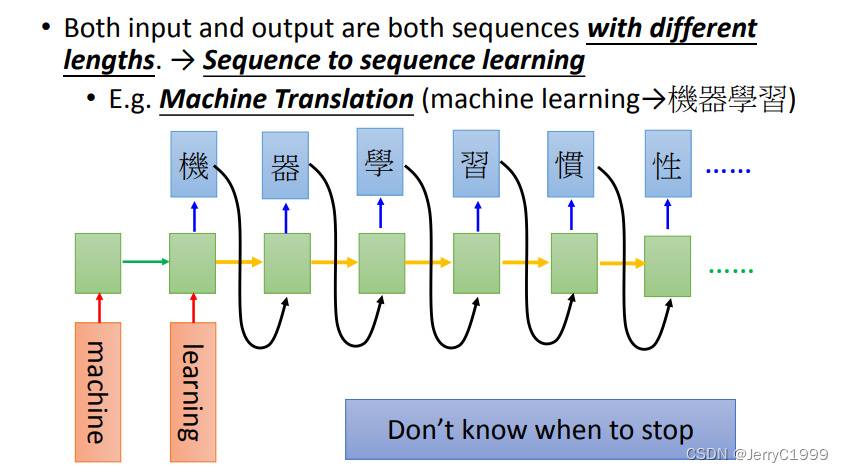
10.Many to Many (No Limitation)
11.Beyond Sequence
12.Sequence To Sequence Auto Encoder
(1)Text
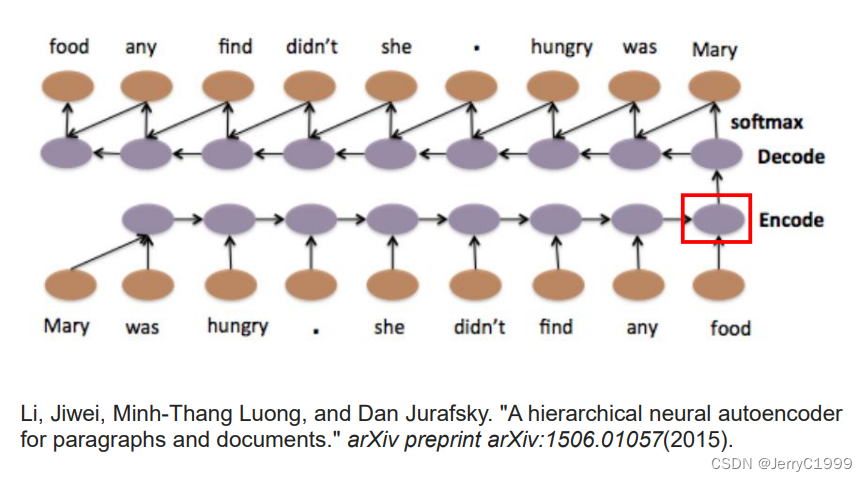
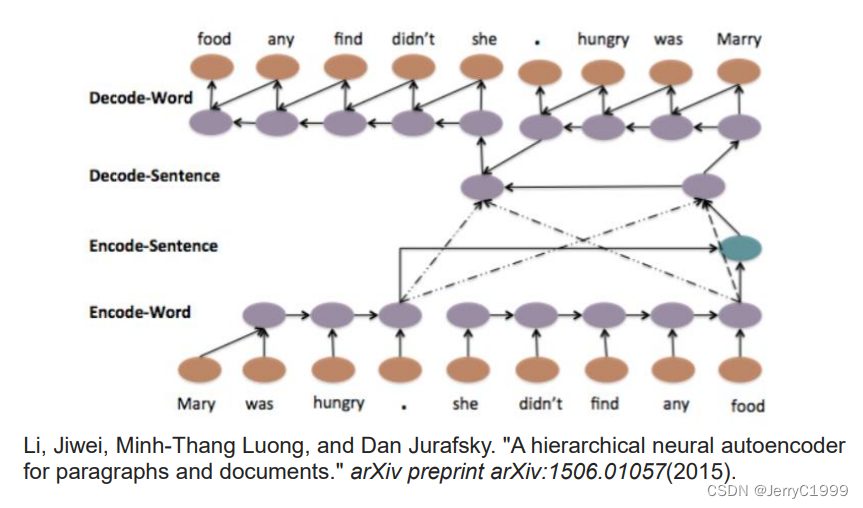
(2)Speech
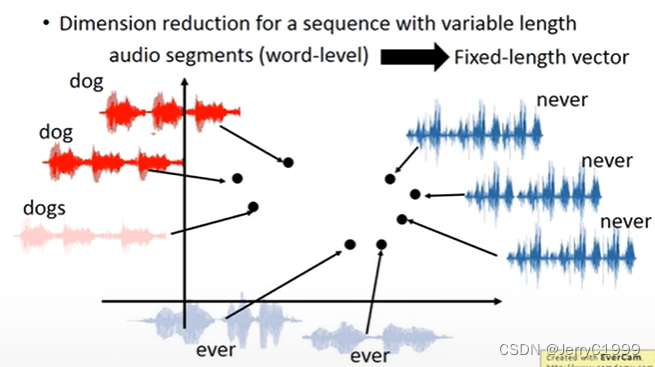
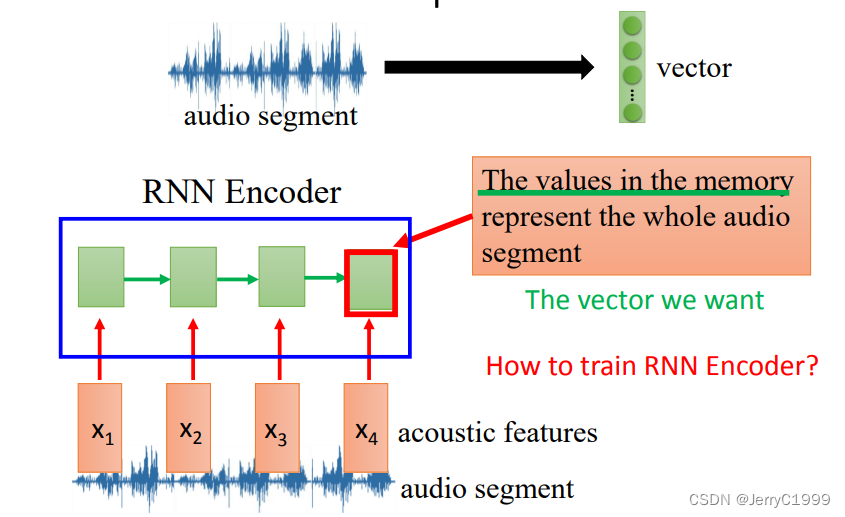
13.RNN vs Structured Learning
















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









