







Storage
storage页面展示spark任务在执行过程中persist或者catche的RDD状态信息,由于这部分RDD只会在执行过程中出现,所以一个任务一旦执行完毕这个页面就不会在显示信息。对于数仓同学来说,这个页面比较少的关注,也基本不起到什么作用,可以只作为知识了解即可。

点击具体的RDD后,可以看到下面的详细信息
 有关storage页面的自问自答
有关storage页面的自问自答
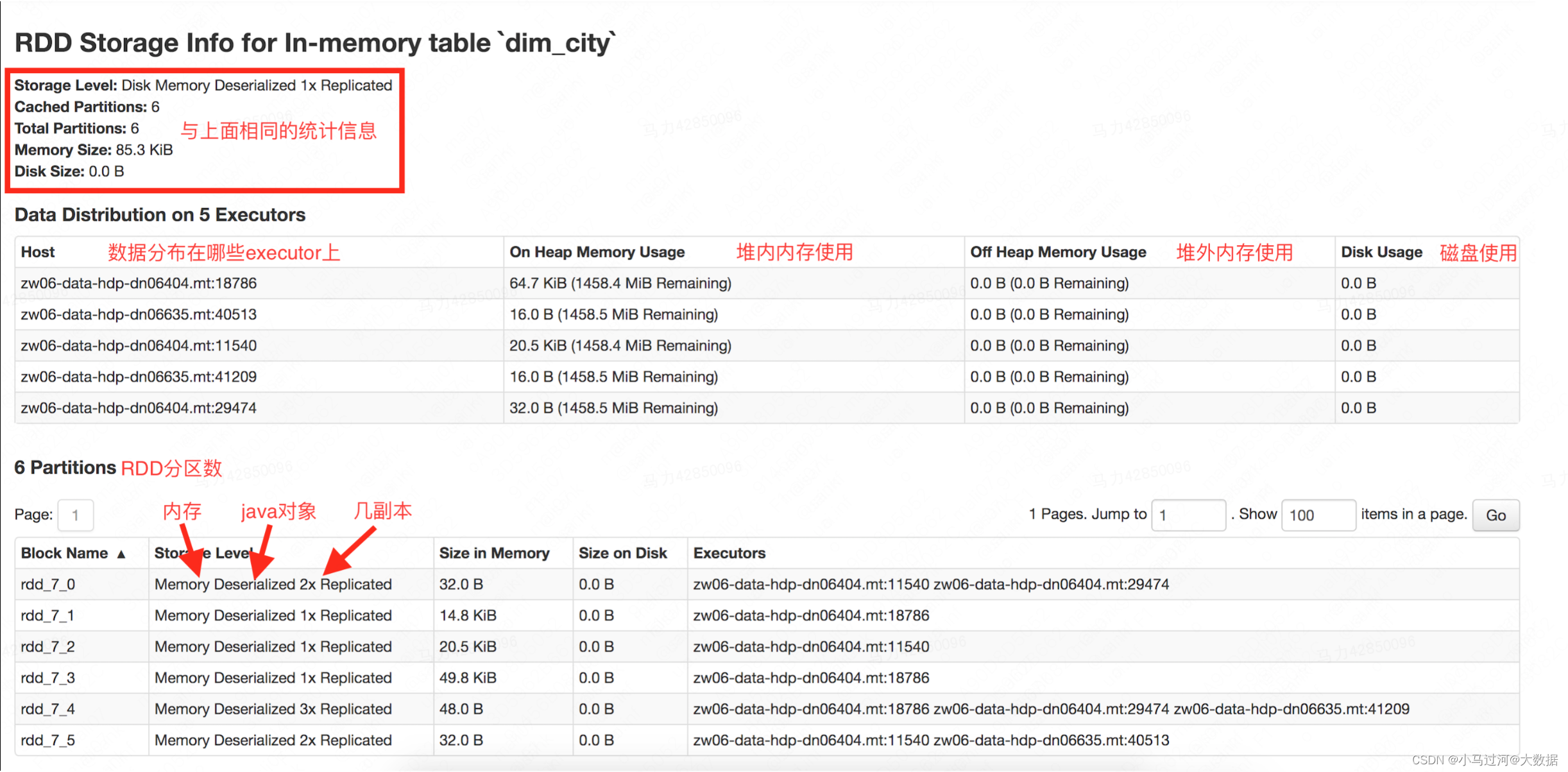
1.StorageLevel都有哪些
具体含义可以看下面的截图,大致分为内存对象、内存和磁盘、内存序列化、内存和磁盘序列化、磁盘、双副本、堆外内存。
通常情况下,在内存对象和内存序列化访问速度最快。
至于为什么RDD的StorageLevel是Disk Memory Deserialized 1x replicated,而RDD partition的StorageLevel是Memory Deserialized 1x/2x/3x replicated,上下不一致的原因还不是很清楚。
2.cache table有什么用,和broadcast有什么关系或者区别吗
首先cache table和broadcast join并没有绝对的关系。
cache table是把数据缓存在内存(绝大部分情况)或本地磁盘上,适用的场景主要是缓存一段“反复使用的逻辑的结果”。比如我们经常写的with xxx as是把一段逻辑封装成一个虚拟表,但是真正在计算时,多次引用会多次触发这段逻辑计算,所以只是写起来精简,但执行上并没有一次运行多次复用。使用了cache table则能把这段逻辑的结果进行缓存,后面代码在引用时不会重新计算这段逻辑生成结果,实现了一次计算多次复用。有时我们使用create [temporary] table来固话一段逻辑的结果也可以实现类似的效果,只不过cache table大多在内存中,访问速度会非常快,非常适合内存中的迭代计算。
由于cache table多是缓存在内存中,数据量一般很小,很大概率会小于参数spark.sql.autoBroadcastJoinThreshold设置的值,因而触发了自动的广播。

















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









