






分析背景
在社交电商与内容种草深度融合的时代,小红书已成为年轻人获取消费灵感的重要平台。从美妆护肤到母婴用品,从旅行攻略到家居好物,用户通过图文笔记和短视频记录消费体验,形成了庞大的“种草-拔草”生态。然而,面对海量的消费内容和用户行为数据,如何快速提取有价值的信息?如何发现消费趋势背后的规律?这不仅是商家优化产品策略的关键,也是个人用户理性消费的指南针。Python数据分析凭借其强大的数据处理(Pandas)、可视化(Matplotlib/Seaborn)和机器学习(Scikit-learn)能力,成为破解这一问题的利器。通过抓取小红书公开的消费相关数据,从用户画像、行为路径、消费周期等维度,提炼出可落地的运营建议。
数据介绍
指标解释
- revenue:用户的下单购买金额
- gender:男1,女0,空缺unkown
- age:年龄,空缺unkown
- engaged_last_30:最近30天在app上有参与重点活动
- lifecycle:生命周期A:注册6个月内; B:一年内; C:两年内
- days_since_last_order:最近一次下单距今的天数(小于1表示当天有下单)
- previous_order_amount:累计的用户购买金额
- 3rd_party_stores:用户过往在app中从第三方商家购买的数量,0表示购买的自营产品
#导入库
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
import seaborn as sns#导入数据
data=pd.read_csv(r'C:\Users\Lenovo\Desktop\案例集\小红书用户消费金额预测\data_red.csv')
print(data.head(10))#查看数据信息
data.info()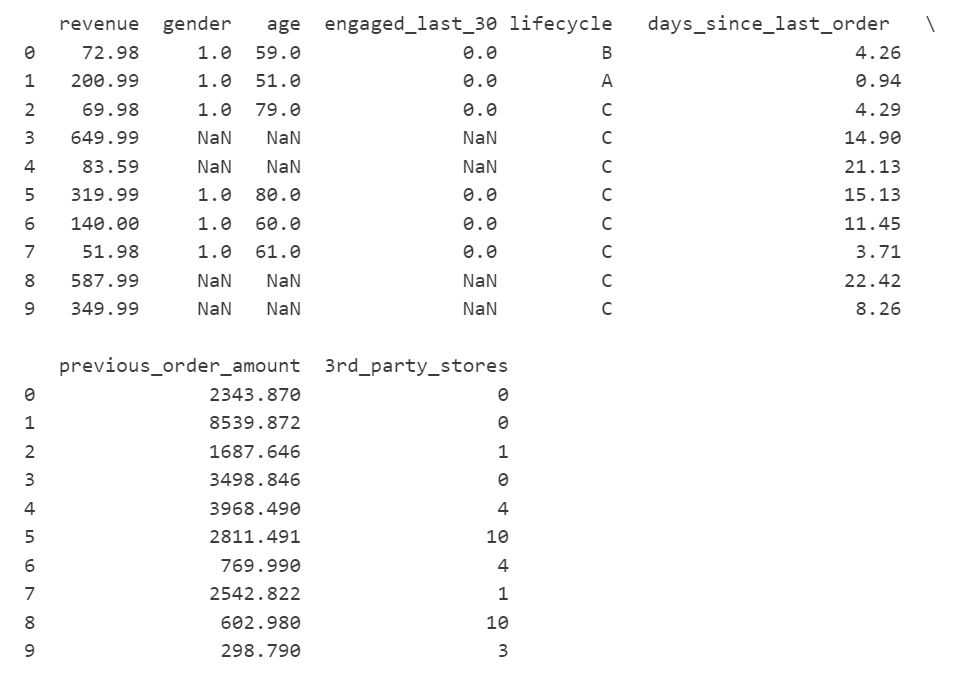
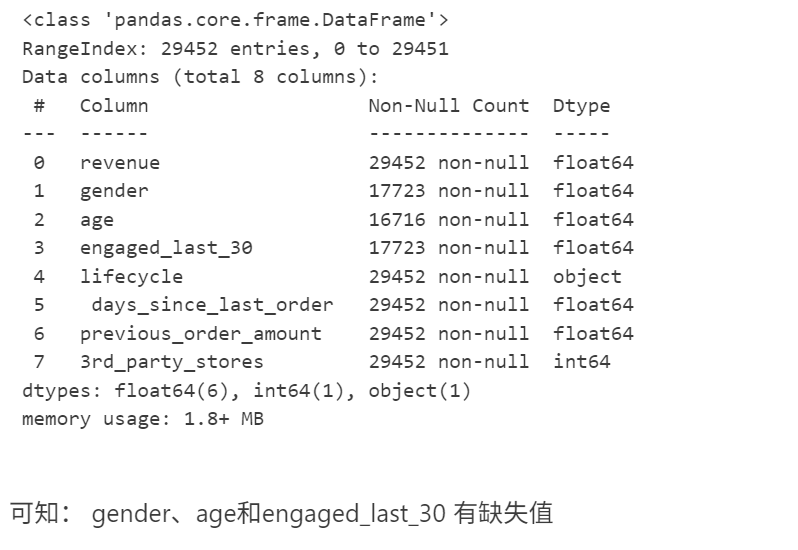
可知: gender、age和engaged_last_30 有缺失值
#删除days_since_last_order前后的空格
data.columns = data.columns.str.strip()
data.info()缺失值处理
#去重
data.drop_duplicates(inplace=True)
#查看缺失值的占比(如果占比少可直接删除)
data.isnull().sum()/data.count() 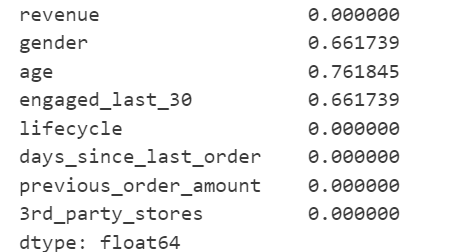
结论:占比较大,不能直接删除
#重置DataFrame索引
data.reset_index(drop=True,inplace=True)
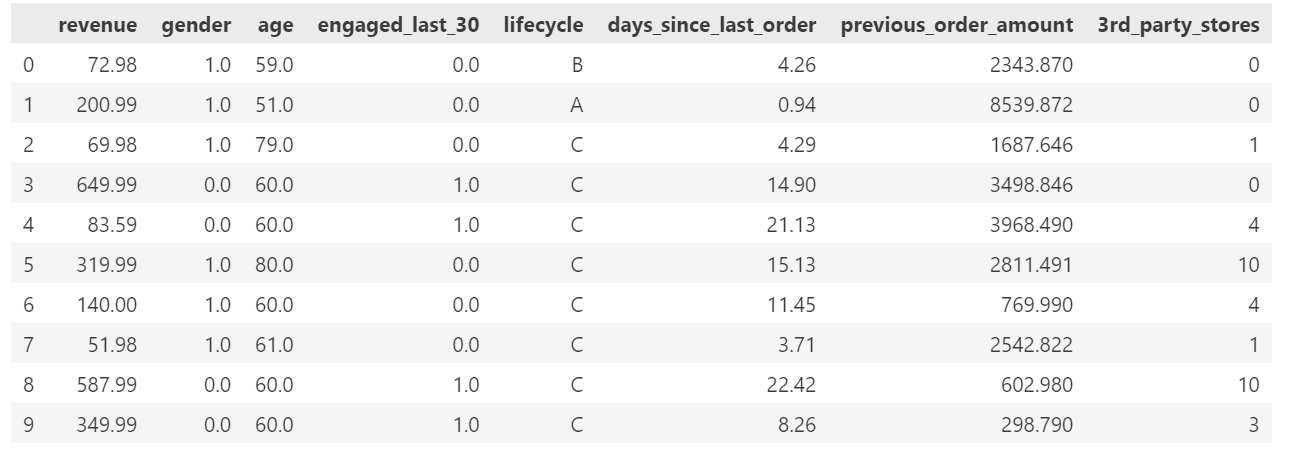
#缺失值标记
data.replace('nan',np.nan,inplace=True)
#缺失值替换(gender)随机选择
data['gender'].fillna(random.choice([1.0,0.0]),inplace=True);
#缺失值替换(age)
data['age'].fillna(round(data.age.mean(),0),inplace=True)
#缺失值替换(engaged_last_30)
data['engaged_last_30'].fillna(random.choice([1.0,0.0]),inplace=True)
数据分析
单变量分析
#revenue下单金额分析
sns.displot(data['revenue'], kind='hist',height=6,aspect=2)
plt.xlim(0,3000)
plt.xticks(range(0, 3001, 250));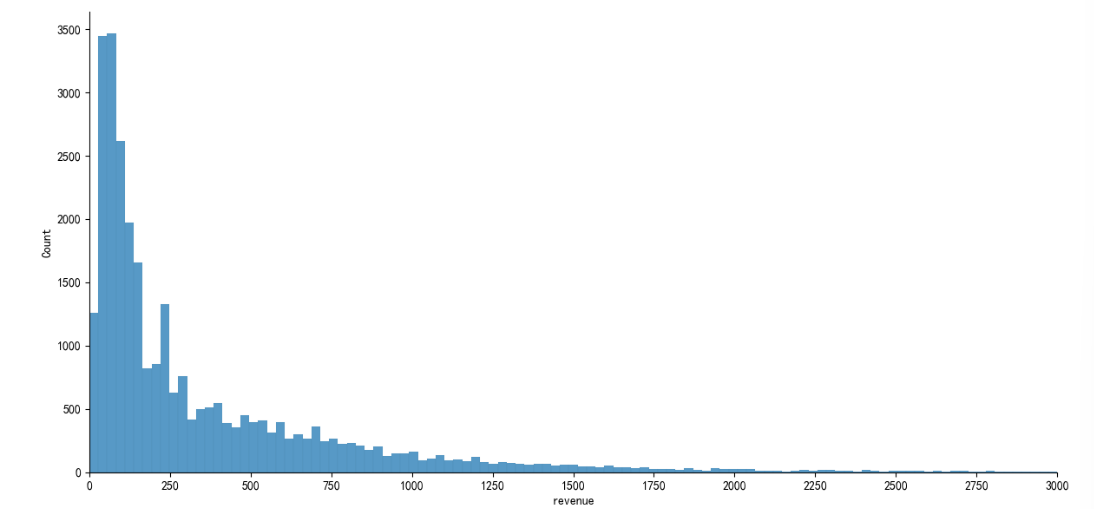
可知:revenue(下单金额)普遍集中在(0——500)这个区间里面
#previous_order_amount用户以往累计购买金额分布
sns.displot(data['previous_order_amount'],kind='kde',height=6,aspect=2)
plt.xticks(range(0,12000,1000));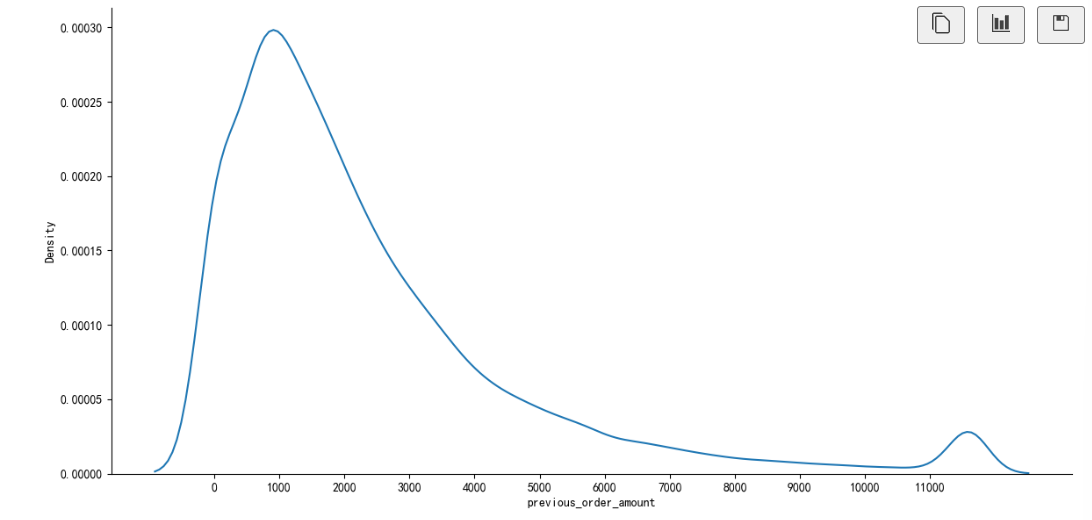
可知:用户累计销量在(0——2000)频数最高
#age年龄分布
sns.displot(data['age'],kind='hist',kde=True,height=6,aspect=2)
plt.xticks(range(20,100,5));
data['age'].describe()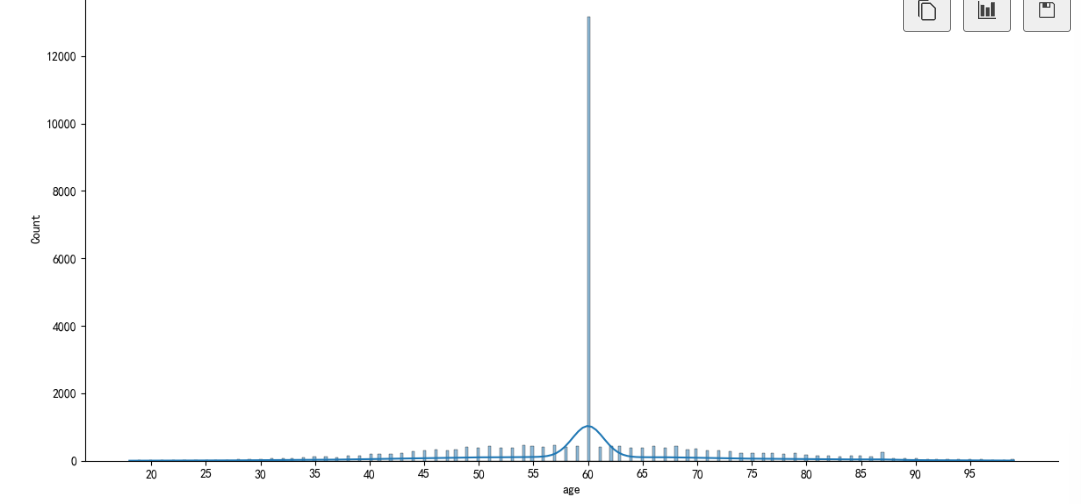
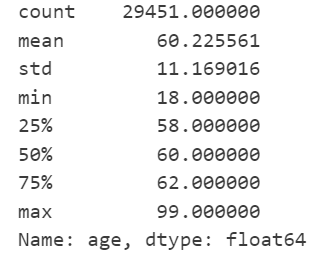
可知:用户年龄在平均值两侧呈对称分布,受众用户平均年龄为:60.23,大部分年龄主要集中在58——62岁
#性别gender
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
gender_count=data['gender'].value_counts()
gender_mapping = {0: '女', 1: '男'}
labels = [gender_mapping[label] for label in gender_count.index]
plt.pie(gender_count,labels=labels, autopct='%1.1f%%');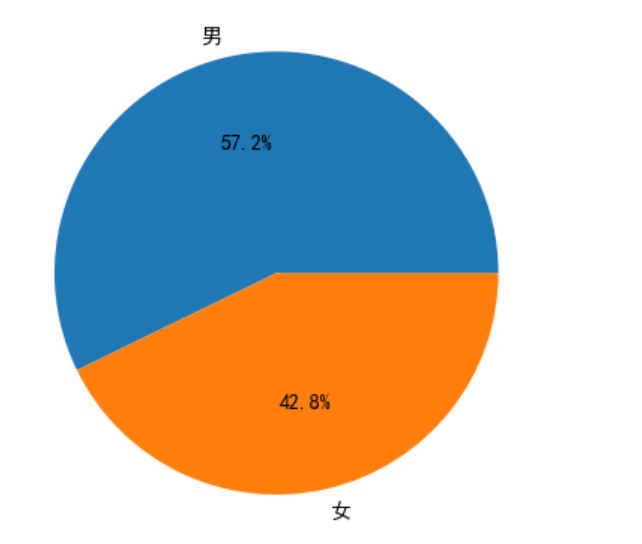
可知:男性用户占了97%
单一变量与购买金额的关系
#各变量与revenue的关系分析
#创建子图布局
fig, axs = plt.subplots(1, 7, figsize=(25, 10))
axs[0].scatter(data['gender'],data['revenue'])
axs[0].set_title('gender VS revenue')
axs[1].scatter(data['age'],data['revenue'])
axs[1].set_title('age VS revenue')
axs[2].scatter(data['engaged_last_30'],data['revenue'])
axs[2].set_title('engaged_last_30 VS revenue')
axs[3].scatter(data['lifecycle'],data['revenue'])
axs[3].set_title('lifecycle VS revenue')
axs[4].scatter(data['days_since_last_order'],data['revenue'])
axs[4].set_title('days_since_last_order VS revenue')
axs[5].scatter(data['previous_order_amount'],data['revenue'])
axs[5].set_title('previous_order_amount VS revenue')
axs[6].scatter(data['3rd_party_stores'],data['revenue'])
axs[6].set_title('3rd_party_stores VS revenue')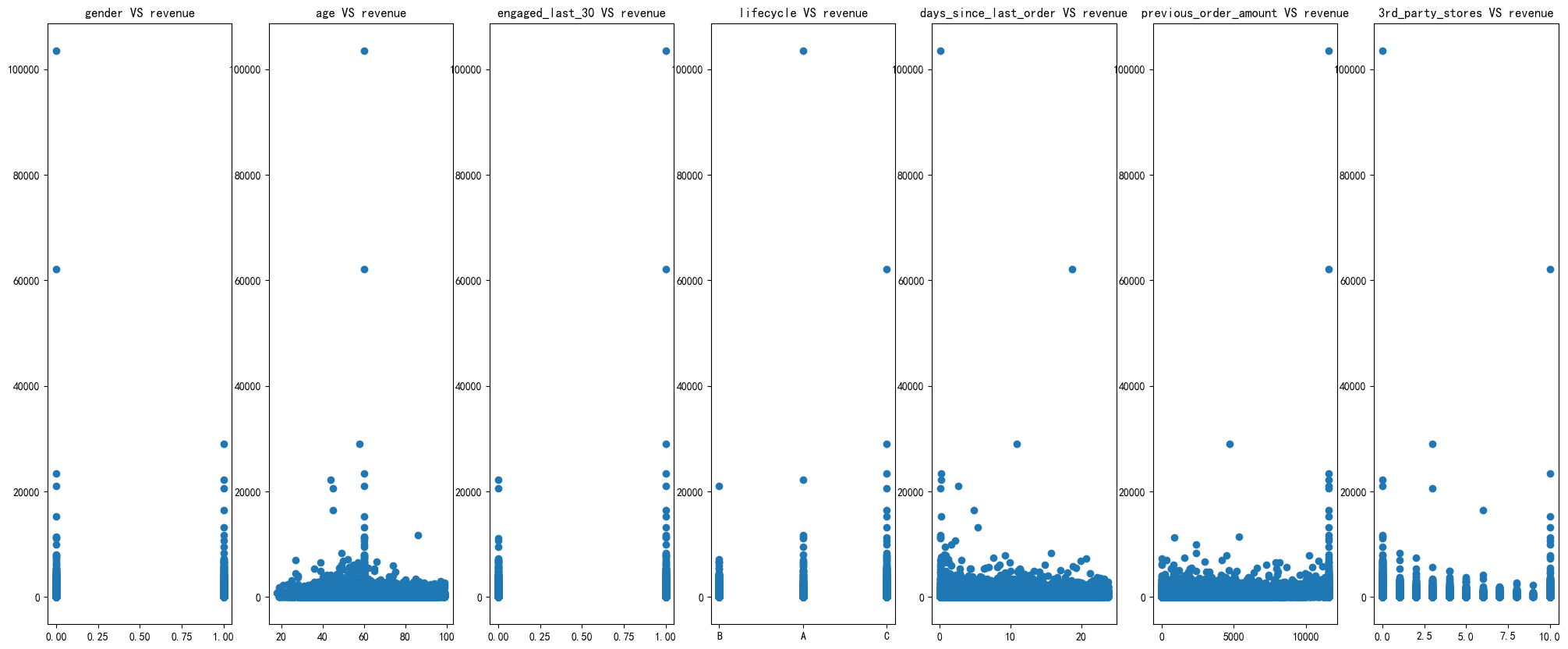
异常值:多个图表中都存在高收入的异常值,这些异常值可能对整体分析结果产生较大影响。 相关性:部分变量(days_since_last_order、3rd_party_stores、previous_order_amount)与收入显示出一定的正相关性,而其他变量(如age、 lifecycle)的关系则较为复杂。
# age和gender
data[data['gender'] == 1.0].age.plot(kind='hist', color='green', edgecolor='black', alpha=0.3, figsize=(10, 7))
data[data['gender'] == 0.0].age.plot(kind='hist', color='green', edgecolor='black', alpha=0.6, figsize=(10, 7))
plt.legend(labels=["男","女"])
plt.xlabel("年龄",size=14)
plt.ylabel("购买金额",size=14);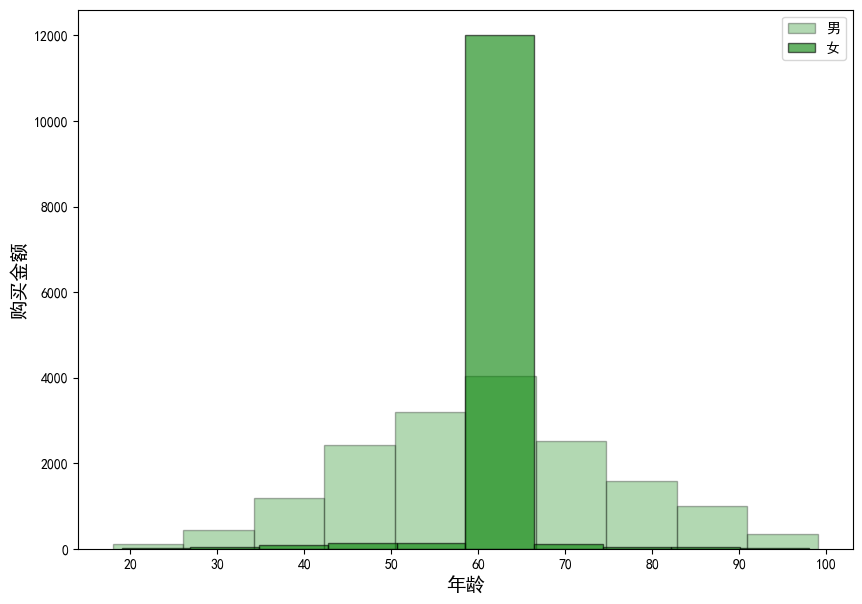
结论:在各个年龄段中,男性的购买金额普遍高于女性,总体来看年龄在45——65之间的用户占比比较大。
# days_since_last_order和3rd_party_stores
data[data['3rd_party_stores'] == 1.0].days_since_last_order.plot(kind='hist', color='green', edgecolor='black', alpha=0.6, figsize=(10, 7))
data[data['3rd_party_stores'] == 0.0].days_since_last_order.plot(kind='hist', color='green', edgecolor='black', alpha=0.3, figsize=(10, 7))
plt.legend(labels=["购买第三方","购买自营"])
plt.xlabel("上一次下单距今的天数",size=14)
plt.ylabel("购买金额",size=14);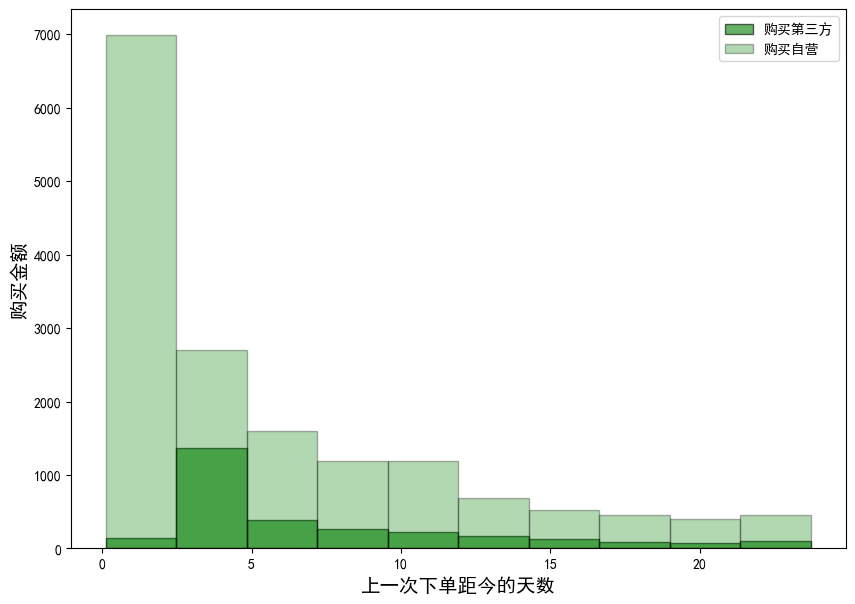
结论:用户的购买金额随着距离上次购买的时间变长而减少,总体来看购买自营的用户数量要大于购买第三方的。
# days_since_last_order和lifecycle
data[data['lifecycle'] == "A"].days_since_last_order.plot(kind='hist', color='green', edgecolor='black', alpha=0.8, figsize=(10, 7))
data[data['lifecycle'] == "B"].days_since_last_order.plot(kind='hist', color='green', edgecolor='black', alpha=0.5, figsize=(10, 7))
data[data['lifecycle'] == "C"].days_since_last_order.plot(kind='hist', color='green', edgecolor='black', alpha=0.3, figsize=(10, 7))
plt.legend(labels=["六个月以内","一年以内","两年以内"])
plt.xlabel("上一次下单距今的天数",size=14)
plt.ylabel("购买金额",size=14);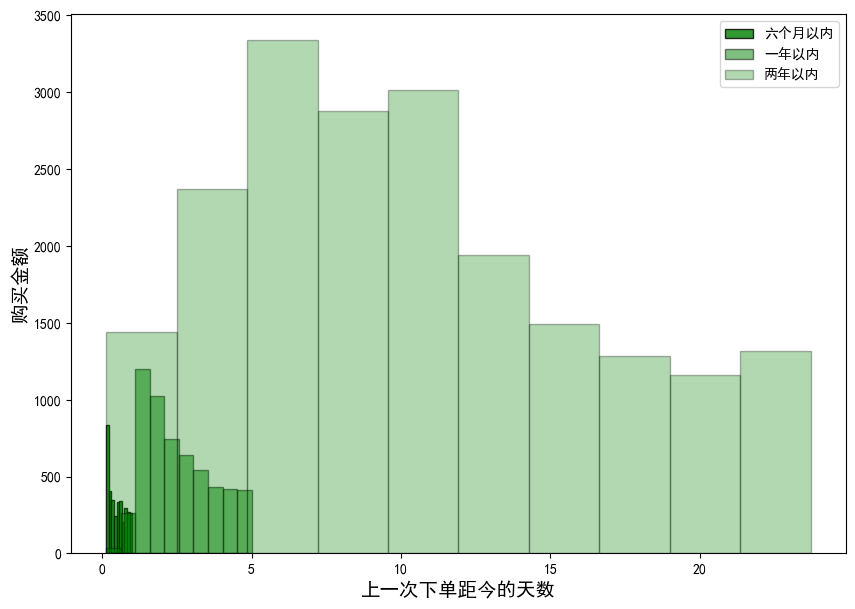
由图可知:近3天消费的用户中新用户(注册时间为六个月以内和一年以内)的占比比较大,大部分老客户(注册时间为两年以内)的用户超过5天未下单。
#求具体的占比
# 定义函数来计算特定天数内没有消费的用户比例
def calculate_inactive_users_percentage(data, lifecycle_group, days_threshold):
group_data = data[data['lifecycle'] == lifecycle_group]
inactive_users = group_data[group_data['days_since_last_order'] >= days_threshold]
percentage = (len(inactive_users) / len(group_data)) * 100
return percentage
# 计算各生命周期组在特定天数内没有消费的用户比例
lifecycle_groups = ["A", "B", "C"]
days_thresholds = [5, 10]
results = {}
for lifecycle in lifecycle_groups:
for days in days_thresholds:
key = f"{lifecycle} ({'注册时间为六个月内' if lifecycle == 'A' else '注册时间为一年以内' if lifecycle == 'B' else '注册时间为两年以内'})超过 {days}天未下单"
percentage = calculate_inactive_users_percentage(data, lifecycle, days)
results[key] = percentage
# 输出结果
for key, value in results.items():
print(f"{key}: {value:.2f}%")

结论:超过80.53%的老用户(注册时间两年以内)近5天都没有消费,超过48.09%的老用户(注册时间两年以内)近10天都没有消费。
#previous_order_amount和engaged_last_30
data[data['engaged_last_30'] == 1.0].previous_order_amount.plot(kind='hist', color='green', edgecolor='black', alpha=0.5, figsize=(10, 7))
data[data['engaged_last_30'] == 0.0].previous_order_amount.plot(kind='hist', color='green', edgecolor='black', alpha=0.3, figsize=(10, 7))
plt.legend(labels=["参与","没参与"])
plt.xlabel("用户累计购买金额",size=14)
plt.ylabel("购买金额",size=14);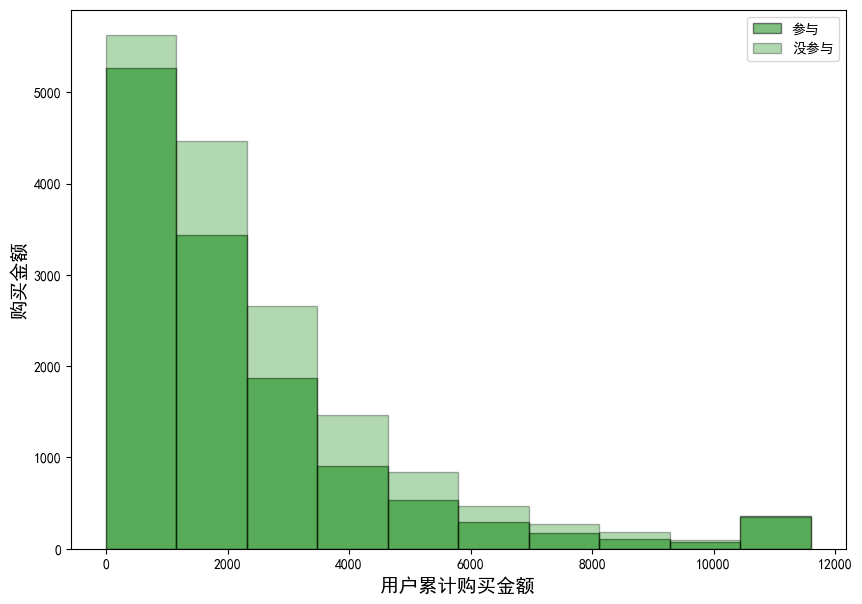
结论:用户的累计购买金额的增加逐渐减少,参与活动的用户普遍购买力高于没有参加活动的,且在支付购买金额的人群中参与了活动的人占比比较高,活动对用户购买行为有显著影响,低存款用户更易受活动影响,高存款用户需采取其他策略。
#lifecycle和previous_order_amount
data[data['lifecycle'] == "A"].previous_order_amount.plot(kind='hist', color='green', edgecolor='black', alpha=0.8, figsize=(10, 7))
data[data['lifecycle'] == "B"].previous_order_amount.plot(kind='hist', color='green', edgecolor='black', alpha=0.5, figsize=(10, 7))
data[data['lifecycle'] == "C"].previous_order_amount.plot(kind='hist', color='green', edgecolor='black', alpha=0.3, figsize=(10, 7))
plt.legend(labels=["六个月以内","一年以内","两年以内"])
plt.xlabel("用户累计购买金额",size=14)
plt.ylabel("购买金额",size=14);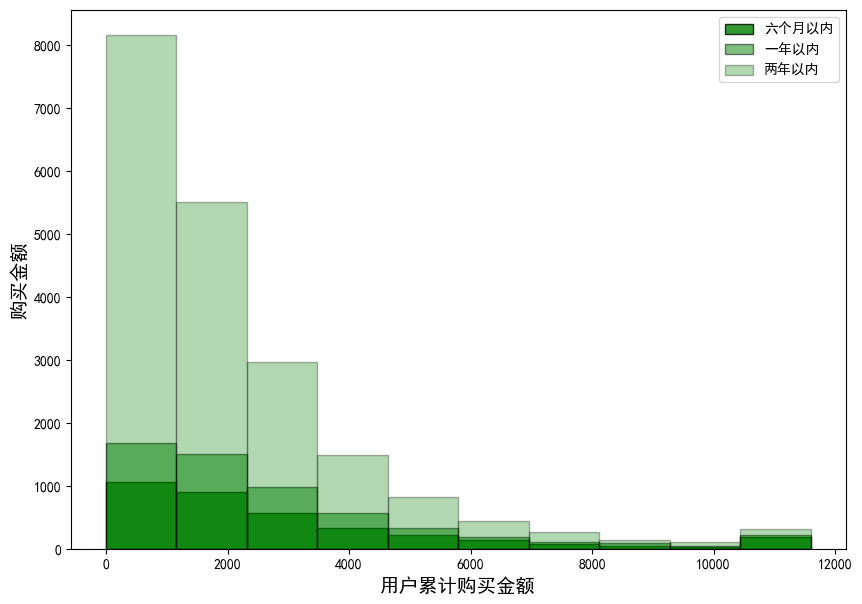
结论:用户的购买金额随着用户累计购买金额的增加而减少,同时两年以内的用户的购买占比比较大,新客的数量较少且购买能力有限。
模型构建
#将lifecycle列是数据转换成数值型
lifecycle_mapping = {"A": 1, "B": 2, "C": 3}
data["lifecycle"] = data["lifecycle"].map(lifecycle_mapping)#导入模块
from sklearn.linear_model import LinearRegression
#建立一个空回归模型
model = LinearRegression()
#设定自变量和因变量
y = data['revenue']
x = data[['previous_order_amount','engaged_last_30','days_since_last_order','lifecycle',]]
#拟合
model.fit(x,y)
#查看系数
model.coef_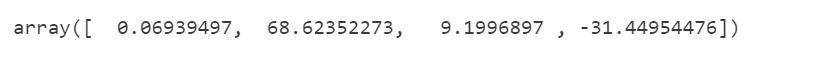
#查看截距
model.intercept_ ![]()
模型评估
#给x和y打分
score = model.score(x,y)
#通过x计算y的预测值
predictions = model.predict(x)
#计算误差
error = predictions - y
#计算rmse
rmse = (error**2).mean()**.5
#计算mae
mae = abs(error).mean()
print(rmse)
print(mae)
结论:MAS和RMSE数值比较高,说明预测结果与真实值之前的差距比较大
from statsmodels.formula.api import ols
model = ols('y~x', data).fit()
print(model.summary())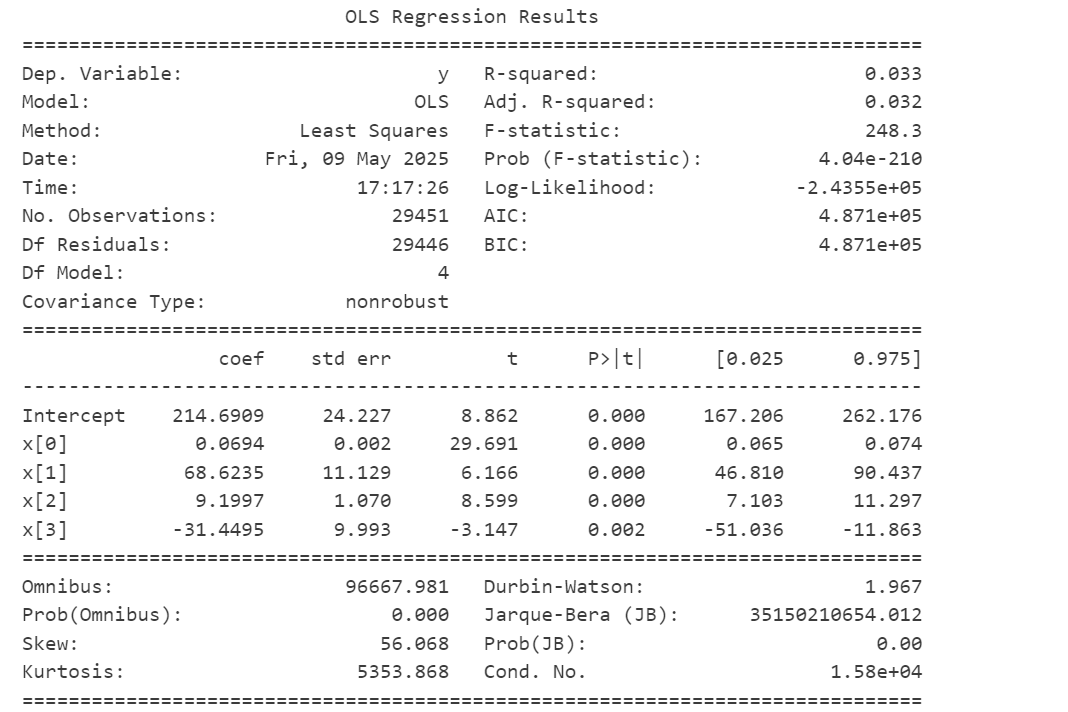
- R-squared为0.031,Prob为0,该回归基本无意义
业务建议
用户分析
- 用户年龄分布在18 - 99岁之间,用户年龄平均值为60.23岁,绝大部分用户年龄集中在58 = 62岁之间
- 用户年龄在平均值两侧呈对称分布
提高销售额变量分析 - 高价值用户
- C(注册后两年)的用户最多
- A(注册后6个月内的)用户销售额平均值最高,为433.8;其次是C(注册后两年)用户,销售额平均值为396.8;销售额平均值最低的是B(注册后一年内的)用户,销售额平均值为381.3
- C用户销售额总和最高,其次是B用户,销售额总和最低的是A用户
- 总销售额大部分由C的用户创造
- 从未在第三方APP购买过的顾客最多,其次是在第三方APP购买过10次的顾客
- 从未在第三方APP购买过的顾客的平均销售额最多;在第三方APP进行了1 - 5次购买的顾客的平均销售额差不多;在第三方APP进行了6 - 10次购买的顾客的平均销售额差不多,不过后者大于在第三方APP进行了1 - 5次购买的顾客的平均销售额
- 总销售额大部分由从未在第三方APP购买过的用户贡献,其次是在第三方APP购买过10次的用户,再次是在第三方APP进行了1 - 5次购买的顾客,贡献最少的是在第三方APP进行6 - 10次购买的顾客- lifecycle_C和days_since_last_order和3rd_party_stores两两正相关关系较强
- gender_1.0和engaged_last_30_0.0正相关关系较强
- revenue和其他任何变量之间的相关性都不明显
结论
- 重点留意注册后两年用户的留存情况
- 活动、广告、营销重点针对男性用户
- 鼓励用户在APP上参加活动,特别是男性用户
- 针对从未在第三方APP进行过购买活动的用户进行额外推送、广告、营销、优惠券推送等,其次是在第三方APP进行购买活动大于等于10次的用户
业务解读
- 每提升1元的用户以往累积购买金额,可以得到0.06元的销售额回报
- 用户用户在最近30天内参加过活动比起不参加活动,销售额提升了62.65元
- 用户最近一次下单距今的天数每提升1天,则可以实现8.98元的销售回报
- 用户在两年前注册比起不在两年前注册,销售额降低了31.02元
- 不断收集数据和添加新变量能提升对整体营销资源投入的把握
(注:该数据线性回归效果较差,仅为练习线性回归步骤用)
原始数据和代码:通过网盘分享的文件:小红书用户消费情况分析
链接: https://pan.baidu.com/s/1obtofXPxvJeOqpXp9d3UMg?pwd=gp9s 提取码: gp9s
--来自百度网盘超级会员v2的分享

















 1887
1887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









