






NVIDIA GeForce RTX 5090显卡性能评测
随着游戏和专业应用对显卡性能需求的不断提高,NVIDIA推出了其最新的GeForce RTX 5090显卡。这款显卡不仅在硬件规格上达到了新的高度,还在AI计算、光线追踪和游戏表现等多个方面展现了出色的性能。
一、核心规格
RTX 5090采用了最新的架构,搭载了更高数量的CUDA核心和更大的显存。以下是其主要参数:
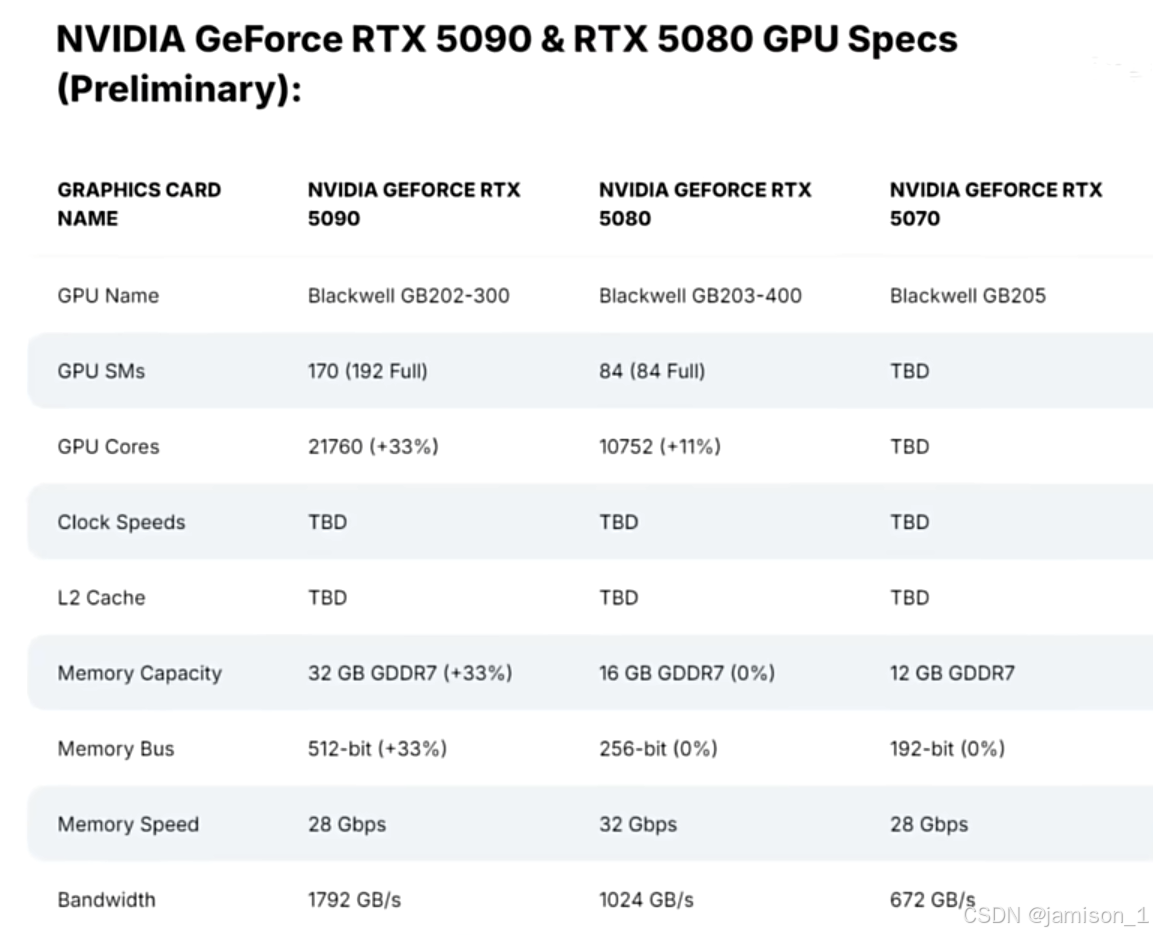
核心规格对比
1. CUDA核心数量
- RTX 5090:21760
- RTX 4090:16384
- RTX 5090的CUDA核心数量显著高于RTX 4090,这意味着在并行计算和图形处理任务中,5090将能够提供更强的性能,特别是在复杂场景渲染和实时光线追踪方面。
- RTX 5090:32 GB GDDR7
- RTX 4090:24 GB GDDR6X
- RTX 5090不仅显存容量增加,而且采用了更新的GDDR7技术,能够提供更高的数据传输速率。这对于高分辨率游戏和大型数据集处理至关重要。
- RTX 5090:1792 GB/s
- RTX 4090:1018 GB/s
- RTX 5090在内存带宽方面的提升使得数据传输更加迅速,进一步提升了在高性能计算和高分辨率游戏时的表现。
这些参数使得RTX 5090在计算性能上具备了更强的优势,尤其在处理高分辨率和复杂场景时,能够提供流畅的体验。
二、光线追踪与DLSS
RTX 5090支持最新的光线追踪技术,能够在游戏中实现更加真实的光影效果。同时,搭载了改进版的DLSS(深度学习超级采样)技术,使得在开启光线追踪时,依然能够保持高帧率。这一技术的结合使得玩家在享受精美画面的同时,不必担心性能下降。
三、游戏表现
在实际游戏测试中,RTX 5090在各大热门游戏中的表现都非常出色。无论是在4K分辨率下的高设置,还是在1440p下的超高设置,RTX 5090都能够轻松达到60帧以上的表现。这对于追求极致画质的玩家而言,无疑是一个极大的福音。
四、专业应用
除了游戏性能,RTX 5090在专业应用中的表现同样值得关注。对于视频编辑、3D建模和深度学习等领域,RTX 5090都能够提供显著的加速效果。这使得它不仅适合游戏玩家,也成为了创作者的得力助手。
五、总结
总体而言,NVIDIA GeForce RTX 5090凭借其强大的硬件规格和出色的技术支持,成为了新一代显卡中的佼佼者。无论是游戏玩家还是专业创作者,都能在这款显卡中找到满足其需求的性能表现。虽然价格尚未公布,但其带来的性能提升无疑会为用户的投资带来回报。

















 5083
5083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









