






一、准备工作
1.1 安装必要的 Python 库
在开始之前,确保你已经安装了以下 Python 库:
- requests:用于发送 HTTP 请求,获取网页数据。
- BeautifulSoup:用于解析 HTML 和 XML 文档,方便提取数据。
- pandas:用于数据处理和分析,提供了高效的数据结构和数据操作工具。
- jieba:中文分词库,用于对文本进行分词处理。
- snownlp:用于进行情感分析,它基于自然语言处理算法,能够快速判断文本的情感倾向。
- matplotlib:用于数据可视化,绘制各种图表。
- wordcloud:用于生成词云图,直观展示文本中词语的出现频率。
可以使用pip命令进行安装,例如:
pip install requests beautifulsoup4 pandas jieba snownlp matplotlib wordcloud1.2 获取 B 站视频的相关信息
要爬取 B 站的弹幕和评论,需要知道视频的BV号或AV号。在 B 站视频页面的 URL 中可以找到对应的编号,例如:男子骑电动车被查,当场吊销C1驾照?男子:为啥不能骑?_哔哩哔哩_bilibili中的BV1ut421V75q 就是该视频的BV号 。
二、爬取 B 站弹幕
2.1 分析弹幕数据接口
B 站的弹幕数据存储在 XML 文件中,其 URL 格式通常为:哔哩哔哩 (゜-゜)つロ 干杯~-bilibili{弹幕ID}.xml,而弹幕 ID 可以通过视频的BV号或AV号获取。可以通过requests库发送请求获取弹幕 XML 文件内容。
2.2 编写 Python 代码爬取弹幕
import requests
from bs4 import BeautifulSoup
def get_danmu(bvid):
api_url = f'https://api.bilibili.com/x/v1/dm/list.so?oid={get_oid(bvid)}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(api_url, headers=headers)if response.status_code == 200:
soup = BeautifulSoup(response.content, 'xml')
danmu_list = [d.text for d in soup.find_all('d')]
return danmu_list
return []
def get_oid(bvid):
api_url = f'https://api.bilibili.com/x/player/pagelist?bvid={bvid}&jsonp=jsonp'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(api_url, headers=headers)
if response.status_code == 200:
data = response.json()
return data['data'][0]['cid']
return None2.3 测试代码
bvid = 'BV1xxxxxxxxx' # 替换为实际的BV号
danmu = get_danmu(bvid)
print(danmu)三、爬取 B 站评论
3.1 分析评论数据接口
B 站的评论数据通过 API 接口返回 JSON 格式的数据,接口 URL 的格式与视频的BV号或AV号相关。评论数据分为主评论和子评论,需要多次请求来获取完整数据。
3.2 编写 Python 代码爬取评论
import requests
def get_comments(bvid):
oid = get_oid(bvid)
comments = []
page = 1
while True:
api_url = f'https://api.bilibili.com/x/v2/reply/main?csrf=&jsonp=jsonp&next={page}&oid={oid}&type=1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(api_url, headers=headers)
if response.status_code == 200:
data = response.json()
if data['data']['replies']:
for reply in data['data']['replies']:
comments.append(reply['content']['message'])
for r in reply['replies']:
comments.append(r['content']['message'])
page += 1
else:
break
else:
break
return comments3.3 测试代码
bvid = 'BV1xxxxxxxxx' # 替换为实际的BV号
comments = get_comments(bvid)
print(comments)
四、数据预处理
4.1 合并弹幕和评论数据
将爬取到的弹幕和评论数据合并到一个列表中:
bvid = 'BV1xxxxxxxxx' # 替换为实际的BV号
danmu = get_danmu(bvid)
comments = get_comments(bvid)
all_text = danmu + comments4.2 文本清洗和分词
使用jieba库对文本进行分词,并去除一些无关的字符和停用词:
import jieba
import string五、情感分析
使用snownlp库对合并后的文本进行情感分析,snownlp会返回一个介于 0 到 1 之间的情感得分,得分越接近 1 表示情感越积极,越接近 0 表示情感越消极:
from snownlp import SnowNLP
sentiments = []
for t in all_text:
s = SnowNLP(t)
sentiments.append(s.sentiments)六、数据可视化
6.1 绘制情感得分分布图
使用matplotlib库绘制情感得分的分布图,直观展示情感倾向的分布情况:
import matplotlib.pyplot as pltplt.hist(sentiments, bins=20, edgecolor='black')
plt.xlabel('Sentiment Score')
plt.ylabel('Frequency')
plt.title('Sentiment Distribution of Bilibili Danmu and Comments')
plt.show()6.2 生成词云图
使用wordcloud库生成词云图,展示出现频率较高的词语:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from collections import Counter
word_counts = Counter(tokenized_text)
wordcloud = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(word_counts)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.title("Word Cloud of Bilibili Danmu and Comments")
plt.show()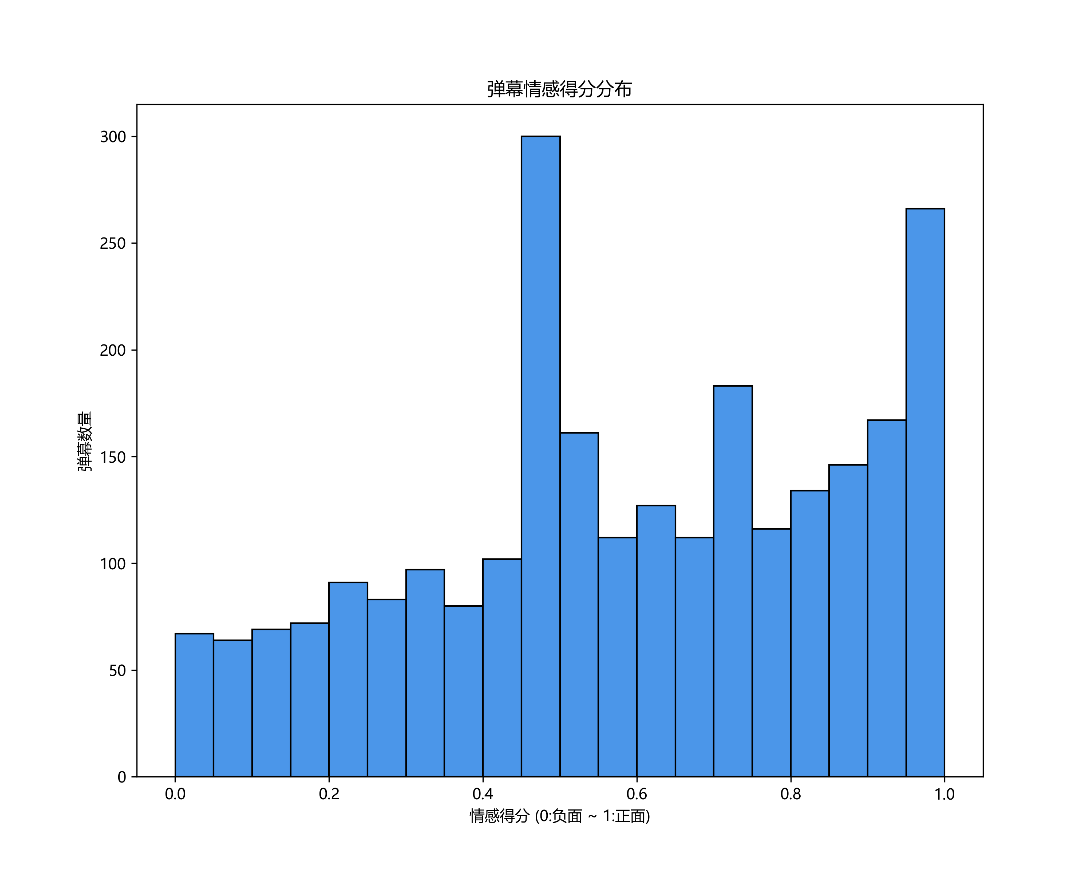
七、注意事项
- 遵守 B 站的使用条款和爬虫规则:在爬取数据时,要注意不要过度频繁地发送请求,避免对 B 站服务器造成压力。
- 处理反爬虫机制:B 站可能会有反爬虫措施,如验证码、IP 限制等。在实际应用中,可能需要使用代理 IP、设置合适的请求头信息等方式来应对反爬虫机制。


















 82
82

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









