






目前保险产品市场快速发展,保险产品的多样性、客户特征的复杂性以及需求差异使得保险产品推荐成为一个热门话题。保险产品推荐需要考虑保险产品本身的分类特点和用户多维度的特征,根据有限的行为数据挖掘用户偏好,进而预测用户购买的可能性,并把这个商品推荐给相应的用户。
1.业务理解
目前我国保险产品多达上万种,每一个保险产品的保障范围和免责条款都相对较为复杂,用户在选择保险产品时往往存在很多困难,保险公司也很难识别精准的用户,从而降低自身风险提高营收,因此非常需要推荐模型来对用户进行产品推荐。
保险公司和用户存在双向信任问题,一方面,由于互联网环境或是第三方机构的销售方式存在夸大宣传的问题,用户对保险产品存在信任危机,对保险条件和过程存在很多疑问,需要详细了解可信的过程才愿意达成保险产品购买。另一方面,保险公司或是第三方机构对用户可能对用户的具体情况不够了解,特别是保险关键因素如健康状况、家庭背景等等,难以提供精准的保险产品推荐,同时,用户是否购买存在着较大的不确定性,购买意愿较难推测,因此需要应用数据挖掘技术,通过对用户本身属性和过往保险购买记录分析客户特点,对广大用户进行个人信息的有效筛选,从购买保险的用户群体中提取共同的特征,从而针对这些特征规律提高投放精准性,促进保险公司的业务发展。
2.实验目标
本实验主要根据用户的历史投保记录,以及用户家庭和成员的各种属性统计结果,来向用户推荐一款房车险。通过对投保记录和用户自身属性信息进行分析,来找到可能购买的该保险的用户特征,从而依据这些特征有针对性的对用户进行推荐,提高销量。
实验所用数据共5822条记录,每条记录有86个字段,1~43字段为用户基本属性,包括财产、宗教、家庭情况、教育程度、职位、收入水平等;44~85字段为用户历史保险购买情况,第86个字段为目标预测字段,取值为0和1,表示用户是否购买该房车险。
根据以上数据,可将用户分为购买移动房车险和不购买移动房车险两个类别,看作一个 分类问题,前85个字段作为用户特征, 使用决策树分类算法来分析购买该保险的用户特征,决策树主要通过一个数据的熵值来表示数据的稳定或复杂程度,熵值越大说明数据越复杂,纯度越低;反之说明数据纯度越高,熵值的变化为信息增益。如果将一个数据集划分之后相对于原数据集的熵是减少的,说明数据的不确定性降低。通过信息增益来进行属性的选择,选择信息增益最大的属性来划分数据,划分后的子数据集就具有最小的熵,最高的纯度。本实验中依照某一属性划分之后的信息增益最大,说明划分后的每个子集用户的购买倾向更相似。反复迭代,以此作为检验用户是否会购买保险的模型,从而根据这些特征对特定群体进行精准营销,降低运营成本,提高用户准化率。
3.数据探索
对数据进行初步探索,以发现其主要特点,理解数据结构和各变量的意义。首先对数据进行描述性统计分析,包括最大值、最小值、均值、中位数、标准差等,来查看数据的分布情况与特征,从而验证数据质量,对数据有一个初步的了解,可作为结果的验证,数据描述性统计代码如下,首先设置数据输出宽度,再用describe方法输出数据的统计型特征。
import pandas as pd
pd.set_option('display.max_columns',1000)
pd.set_option('display.width',1000)
pd.set_option('display.max_colwidth',1000)
dataSet = pd.read_excel('data.xlsx')
print(dataSet.describe())
结果输出如图1所示。
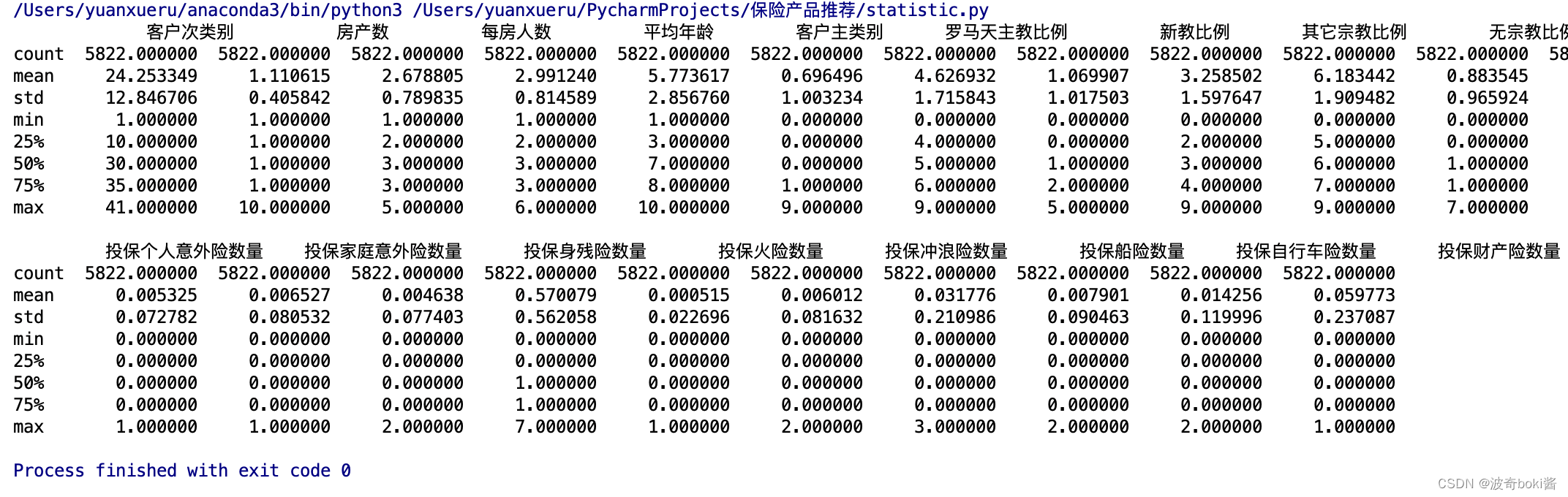
图 1 描述性统计数据特征
为了查看投保移动房车险的用户特征分布,可采用箱型图可视化数据,来查看不同的变量对因变量的区分度,分别分析有无购买移动房车险用户在购买力水平、是否有车、教育水平、是否已婚、是否高管、农场主几个方面的分布。箱型图结果如图2-12。
plotx= dataSet['购买力水平']
ploty= dataSet['移动房车险数量']
d = {'购买力水平': plotx,'移动房车险数量': ploty}
df = pd.DataFrame(data=d)
plot=df.boxplot(column='购买力水平',by='移动房车险数量')
plot.set_xlabel('移动房车险数量')
plot.set_ylabel('购买力水平')
plt.show()
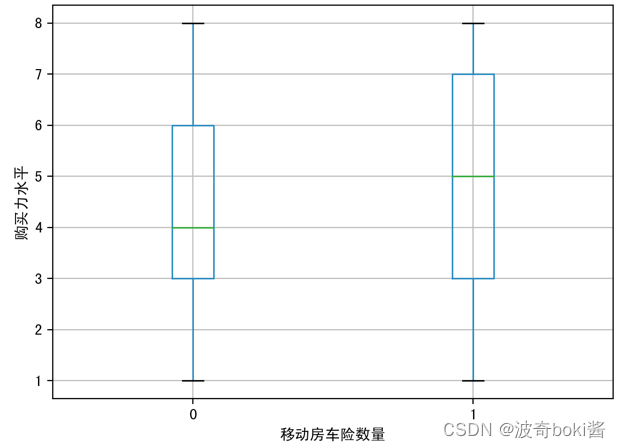
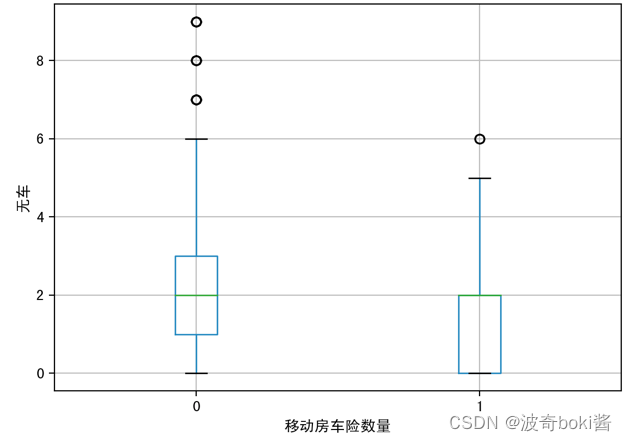
图 2 购买力水平对移动房车险数量影响 图 3 无车对移动房车险数量影响
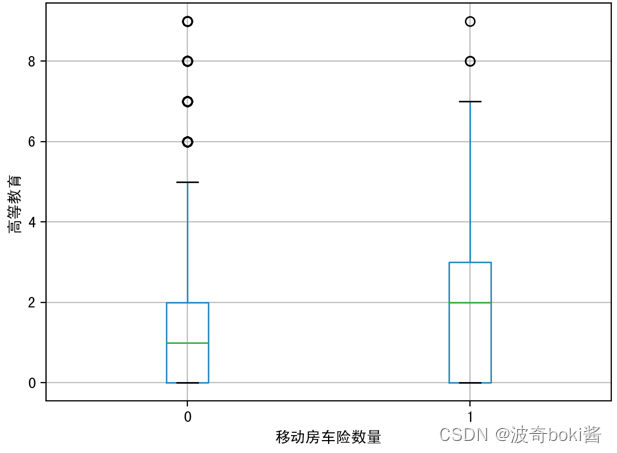
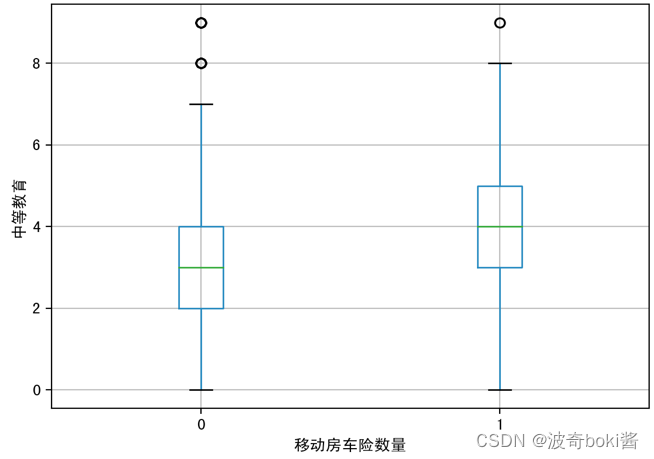
图 4 高等教育对移动房车险数量影响 图 5 中等教育对移动房车险数量影响
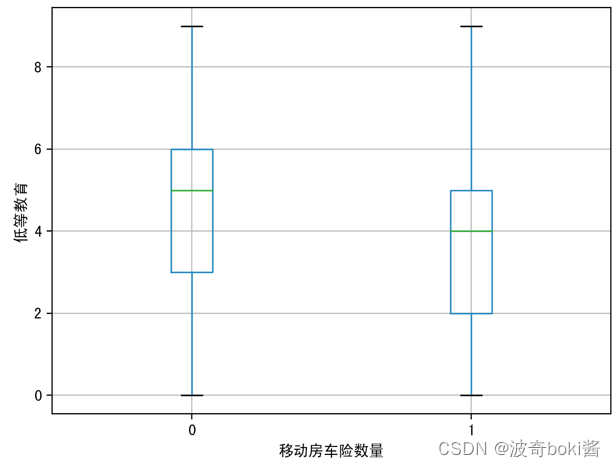
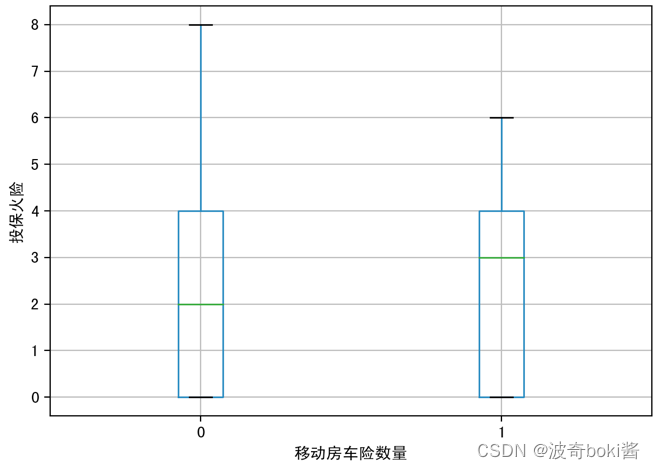
图 6 低等教育对移动房车险数量影响 图 7 投保火险对移动房车险数量影响
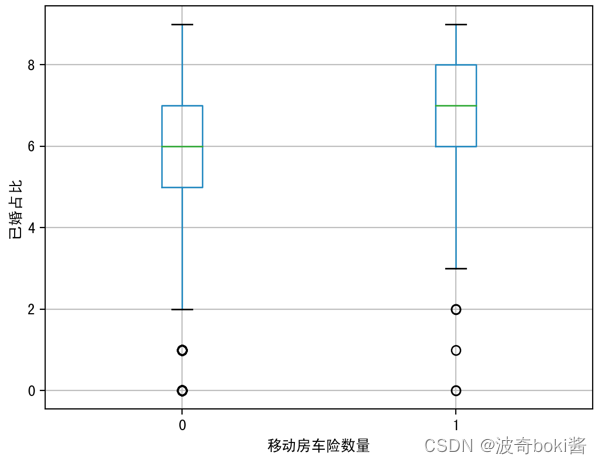
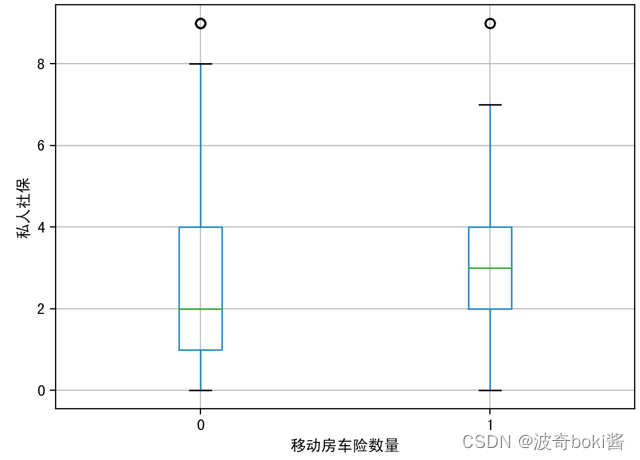
图 8 已婚占比对移动房车险数量影响 图 9 私人社保对移动房车险数量影响
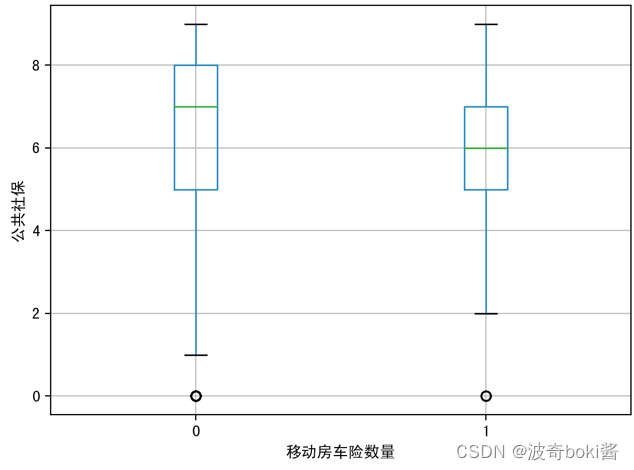
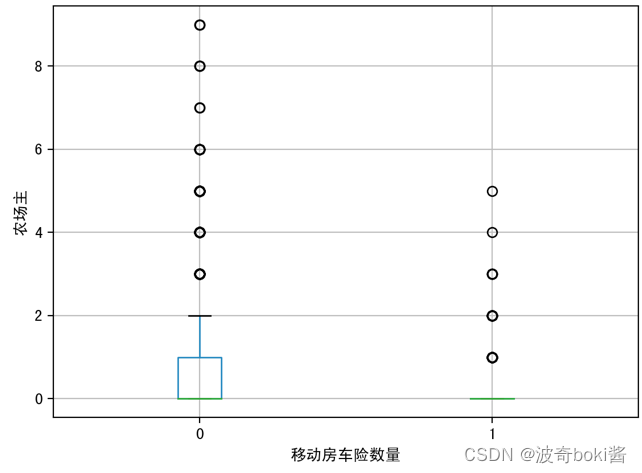
图 10 公共社保对移动房车险数量影响 图 11 农场主对移动房车险数量影响
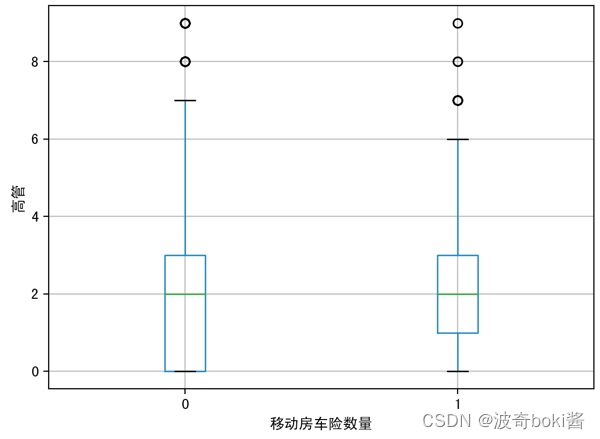
图 12高管对移动房车险数量影响
通过箱型图的比较,可基本得出购买力水平较高的群体、有车群体、教育水平较高群体、已婚群体等更倾向购买该移动房车险,农场主和较低收入群体购买该保险的概率较低。说明投保该移动房车险的用户的经济实力较强,教育程度更高,保险意识相对较强,并且集中于城市生活群体,可对该移动房车险的人群进行初步定位。
4.数据降维
在初步结论的基础上可应用决策树模型对用户进行分类,从而确定购买该保险的用户特征细分。首先由于本实验数据的字段较多,过高维度会影响模型的准确性,先进行数据预处理,将对模型结果影响不大的字段剔除或进行变换。数据中可能存在一些冗余字段,与模型结果不相关,可将这部分字段剔除以达到降维的目的。首先对缺失值大于20%的字段、方差小于0.1的字段进行剔除,之后采用pearson指数来预测字段的重要性,分界值设为95%,最终筛选出43个特征,代码如下。
import pandas as pd
from scipy.stats import pearsonr
train=pd.read_excel('data.xlsx')
a=train.isnull().sum()/len(train)
variables = train.columns
df=train
for i in range(0,86):
if a[i]>=0.2: #大于 20%
df = train.drop(variables[i], 1)
var = df.var()
numeric = df.columns
for i in range(0,len(var)-1):
if var[i]<=0.1: # 方差大于10%
df=df.drop(numeric[i], 1)
variables = df.columns
for i in range(0,len(variables)):
x=df[variables[i]]
y=df[variables[-1]]
if pearsonr(x, y)[1]> 0.05:
df=df.drop(variables[i],1)
variables = df.columns
print(variables)
print(len(variables))
#剩余43个属性
df.to_excel('outputdata.xlsx')
剩余字段如图13所示。

图13 降维后剩余字段
根据训练集保留的特征,对测试集进行选择。代码如下,运行后测试集保留同样的43个字段。
variables =df.columns
testSet=pd.read_excel('eval.xlsx')
testcolumn=testSet.columns
for i in range(0,len(testcolumn)):
if testcolumn[i] not in variables:
testSet=testSet.drop(testcolumn[i],1)
testSet.to_excel('outputeval.xlsx')
5.算法实现
对降维后的数据应用决策树分类算法,首先导入数据集并储存数据条数,导入sklearn中的tree模块来实现决策树算法,其主要原理是计算该数据集的信息熵,同时统计购买移动房车险和未购买两类用户的人数。在此基础上计算按某个特征分类后的熵和原始数据熵的增量,若按某特征划分后,熵值减少的最大,则该特征为当前的最优分类特征,并以此特征作为新的分类,重复这个过程直到当前类别中数据的移动房车险数量字段值为统一值。最终用构造出决策树。代码如下:
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn import metrics
def createDataSet(path):
dataSet = pd.read_excel(path)
labels = list(dataSet.columns.values)
dataSet = dataSet.values
return dataSet, labels
if __name__ == '__main__':
train_dataset,train_labels = createDataSet('balancedata.xlsx')
train_row_count,train_labels_count = train_dataset.shape
train_y = train_dataset[:,train_labels_count-1]
train_x=np.delete(train_dataset,train_labels_count-1,axis=1)
clf = tree.DecisionTreeClassifier()
clf.fit(train_x,train_y)
test_dataset, test_labels = createDataSet('finaleval.xlsx')
test_row_count, test_labels_count = test_dataset.shape
test_y = test_dataset[:, test_labels_count - 1]
test_x = np.delete(test_dataset, test_labels_count - 1, axis=1)
result=clf.predict(test_x)
采用决策树训练后的分支结果如图14所示。

图 14 训练集决策树分类结果
对降维前的数据也应用决策树分类算法,来比较降维前后预测结果的准确性差异。将测试数据应用到训练好的模型中,计算并查看分类的准确性,检验该实验中的降维是否有提高模型准确性。输出结果如图15-16所示。

图 15 降维前决策树分类准确率

图 16 降维后决策树分类准确率
算法优化
比较降维前后决策树分类准确率,发现降维后的准确率为88.97%,降维前准确率为89.27%,说明降维对分类结果的影响不大,对模型分类结果进行分析,发现移动房车险数量预测均为0,由于训练集中移动房车险数量字段值为1的数据仅348条,占总体的5.98%,数据集不平衡使得模型分类不具有代表性,因此需要根据样本数据特点平衡数据,调整正负样本的权重值,将未购买移动房车险的记录下采样降为原来的20%,购买移动房车险的记录数量上采样增加为原来的2倍。代码如下。
import pandas as pd
from sklearn.utils import resample
dataSet = pd.read_excel('data.xlsx')
labels = list(dataSet.columns.values)
df_majority=dataSet[dataSet['移动房车险数量']==0]
df_minority=dataSet[dataSet['移动房车险数量']==1]
df_majority_downsampled=resample(df_majority,
replace=False,n_samples=1095,random_state=123)
df_minority_upsampled=resample(df_minority,
replace=True,n_samples=696,random_state=123)
df_all=pd.concat([df_minority_upsampled,df_majority_downsampled])
df_all.to_excel('outputbalance.xlsx')
平衡后的样本移动房车险数量字段分布如图17所示。

图 17 平衡后样本数据分布
对平衡后的样本进行预处理,剔除相关性不显著的特征,并依据保留的特征对测试集进行选择。最后保留45个特征如图18所示。

图 18 保留特征项
对处理后的样本数据采用逻辑回归和决策树分类算法,并输出预测召回率,f1值。可d导入sklearn.metrics库中的accuracy_score和roc_auc_score包评估分类结果。代码如下:
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
def createDataSet(path):
dataSet = pd.read_excel(path)
labels = list(dataSet.columns.values)
dataSet = dataSet.values
return dataSet, labels
if __name__ == '__main__':
train_dataset,train_labels = createDataSet('balancedata.xlsx')
train_row_count,train_labels_count = train_dataset.shape
train_y = train_dataset[:,train_labels_count-1]
train_x=np.delete(train_dataset,train_labels_count-1,axis=1)
#决策树
clf = tree.DecisionTreeClassifier()
clf.fit(train_x,train_y)
test_dataset, test_labels = createDataSet('finaleval.xlsx')
test_row_count, test_labels_count = test_dataset.shape
test_y = test_dataset[:, test_labels_count - 1]
test_x = np.delete(test_dataset, test_labels_count - 1, axis=1)
#逻辑回归
model = LogisticRegression(C=1e9)
model.fit(train_x, train_y)
test_y = test_dataset[:, test_labels_count - 1]
test_x = np.delete(test_dataset, test_labels_count - 1, axis=1)
result=model.predict(test_x)
result=clf.predict(test_x)
recall=metrics.recall_score(test_y,result,average='micro')
f1=metrics.f1_score(test_y,result,average='weighted')
accuracy=accuracy_score(test_y,result,normalize='False')
auc= roc_auc_score(test_y,result)
print('accuracy:' + str(accuracy))
print('recall:' + str(recall))
print('f1:' +str(f1))
print('auc:' + str(auc))
输出结果如图19所示。
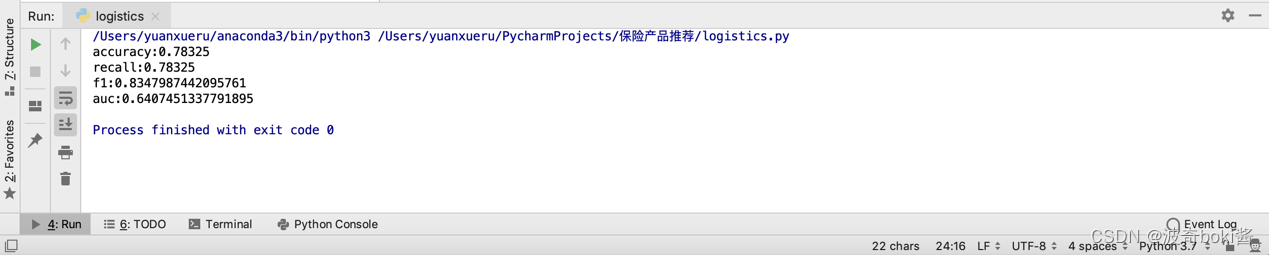
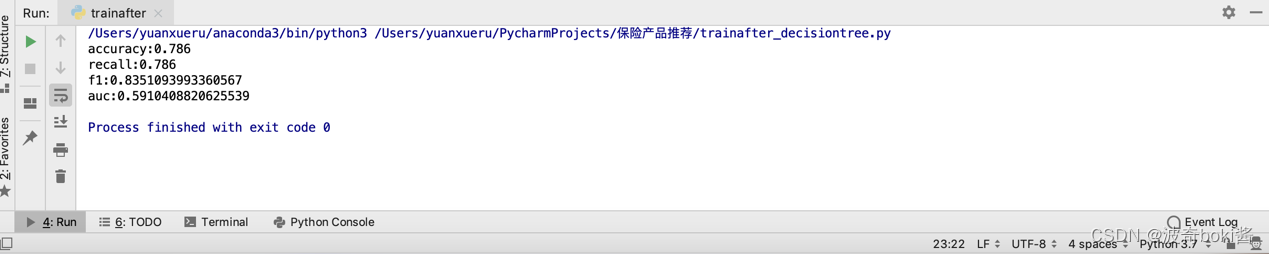
图 19 结果输出
平衡后的数据逻辑回归准确率为78.32%,f1值为0.834,采用决策树分类所得的准确率为78.6%,f1值为0.835,相较于逻辑回归有一定提高。
6.小结
本实验主要根据用户基本特征信息,以及用户历史保险购买情况,来预测用户是否会购买一款移动房车险。通过对数据进行初步的统计性分析,得到购买该移动房车用户的一些集中型特征。在此基础上,采用决策树算法建立模型,对数据进行质量处理和降维,并对样本数据的不平衡进行上采样和下采样处理。平衡后的数据分类准确率为78.6%,对投保用户特征的预测更为准确。根据逻辑回归模型的相关性系数,用户特征社会阶层D、租房子特征对购买移动房车险的负向影响较显著,公共社保、私人保险、投保人寿险数量、投保火险数量对购买移动房车险的正向影响显著。
7.思考
思考题1 :如何判断分类算法的好坏?
答:对于分类问题,我们可以使用混淆矩阵、精确度、召回率、F1得分或AUC-ROC等来判断算法的好坏。
真正:被模型预测为正的正样本。
假正:被模型预测为正的负样本。
假负:被模型预测为负的正样本。
真负:被模型预测为负的负样本。
准确率是最常用的分类性能指标。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
即正确预测的正反例数 /总数
召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall = TP/(TP+FN),即正确预测的正例数 /实际正例总数
F值是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时,F值最大。很多推荐系统的评测指标就是用F值的。
2/F1 = 1/Precision + 1/Recall
根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR假正率),纵坐标为True Positive Rate(TPR真正率)。
AUC被定义为ROC曲线下的面积(ROC的积分),通常大于0.5小于1。随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。AUC值(面积)越大的分类器,性能越好。
思考题2 :分类问题中校验集的作用是什么?
答:调参、选择特征以及调整其他和学习算法相关的选项。用于模型的选择,更具体地来说,校验集并不参与学习参数的确定(不确定参数?)也就是校验集并没有参与梯度下降的过程。校验集只是为了选择超参数,比如网络层数、网络节点数、迭代次数、学习率这些都叫超参数。
8.数据集
链接:https://pan.baidu.com/s/1veDuERIwzgQtaxNv9uLmLw
提取码:gdyg

















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









