






文章目录
前言
- 保险产品的多样性、客户特征的复杂性以及需求差异使得保险推荐存在相当大的不确定性,如何精准识别用户、降低销售风险、提升推荐成功率,成为当前一个非常热门的研究和应用话题。
- 通过对用户本身属性和过往保险购买记录分析客户特点,可以对广大用户进行个人信息的有效筛选,从购买保险的用户群体中提取共同的特征,进而针对这些特征规律提高投放精准性。
- 本案例是针对移动房车险的预测,其中保险公司提供了以家庭为单位的历史数据,包括家庭的各类特征属性和历史投保记录。通过对历史数据的分析,建立移动房车险的预测模型。
- 本案例需要你掌握python语法,并对一些库如
pandas、sklearn、numpy等有一定的了解
1.认识数据集
1.1碎碎语
在进行实际开发前期,我们需要观察数据集,了解哪些属于特征值(features)、哪些属于标签(label/target)、特征值的取值范围、数据类型、标签的取值范围、类型······对于某些类型的数据不便处理,可能需要进行编码数字化。
1.2数据概况
- 数据分为训练数据和测试数据两部分,其中训练数据5822条,测试数据4000条。
- 每一条数据有86个字段,1~43字段为用户基本属性,包括财产、宗教、家庭情况、教育程度、职
位、收入水平等;44~85字段为用户历史保险购买情况,第86个字段为目标预测字段,取值为0和
1,表示用户是否购买该房车险。 - 根据目标预测字段的取值范围,可得该问题是一个二分类问题
上述数据可以通过数据集的官方文档查看,也可以通过代码读取查看
1.3代码查看
因为数据存储在.xlsx文件中,所以可以使用pandas库中的read_excel()函数进行读取查看.
这里简单介绍一下pandas库。pandas 是 Python 中一个强大且广泛使用的开源数据分析和操作库,它提供了高效的数据结构和数据处理工具。主要有两种数据结构
Series和DataFrame。
Series用于存储一维带标签的数组;DataFrame用于存储二维表格型的数据结构
代码展示:
import pandas as pd
data=pd.read_excel("./data/data.xlsx")
data.shape,data.describe()
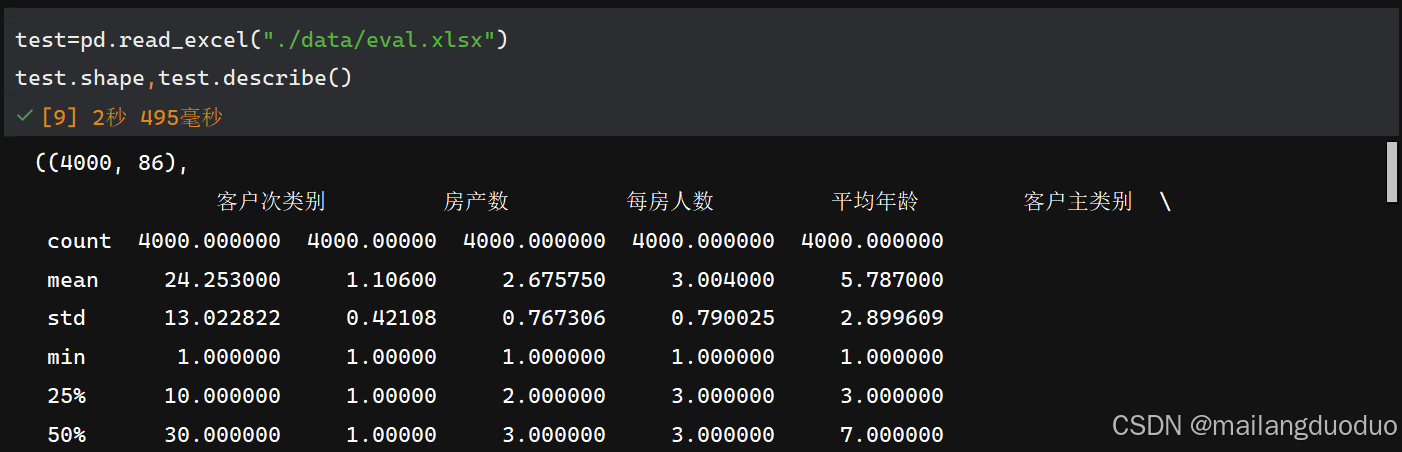
运行结果: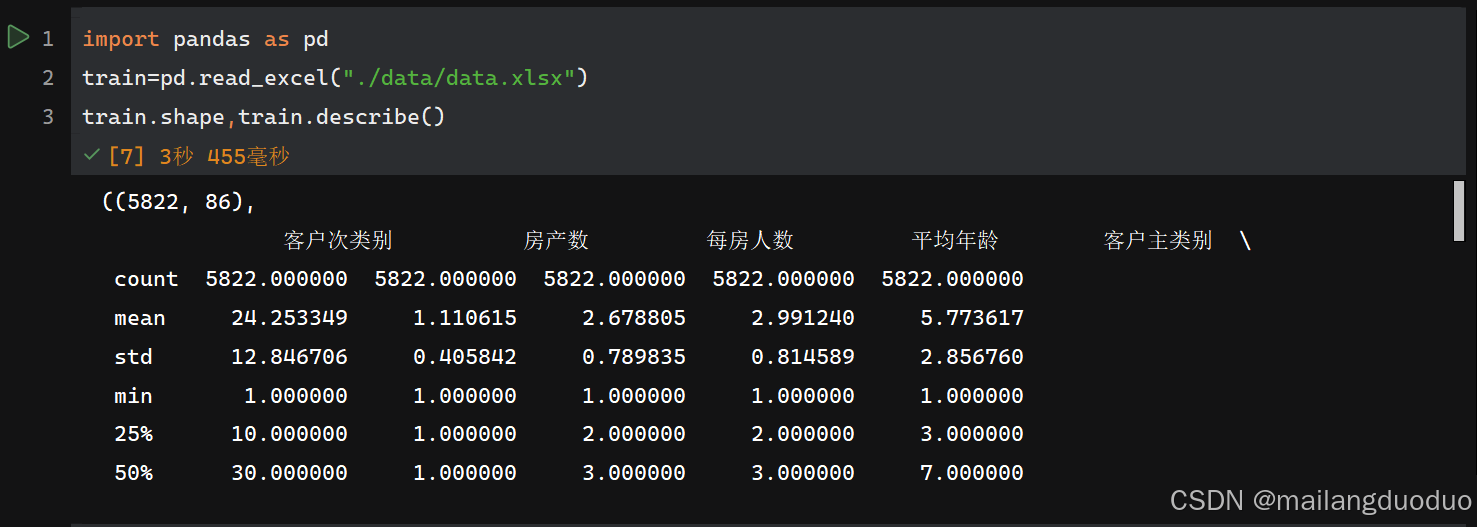 通过结果可以发现,训练集共计5822个样本,86个属性,其中移动房车险作为label,通过结果的count,min,max等结果可以看到每个属性的取值范围,以及是否含有缺失值。同理我们也可以对测试集做出同样的处理
通过结果可以发现,训练集共计5822个样本,86个属性,其中移动房车险作为label,通过结果的count,min,max等结果可以看到每个属性的取值范围,以及是否含有缺失值。同理我们也可以对测试集做出同样的处理
,得出类似的效果
2.数据预处理
在了解完数据集过后,我们一般需要对数据进行加工处理过后,才对建立的模型进行训练。此过程称为数据预处理,旨在提高数据质量,提高模型性能
2.1数据清洗
数据清洗的目的是处理数据中的缺失值、异常值和重复值,以提高数据的质量。
2.1.1缺失值处理
有时数据集由于统计不全等原因,可能出现空白值(缺失值),数据缺失将影响数据分析的特征处理,因此我们需要对缺失值进行统计。
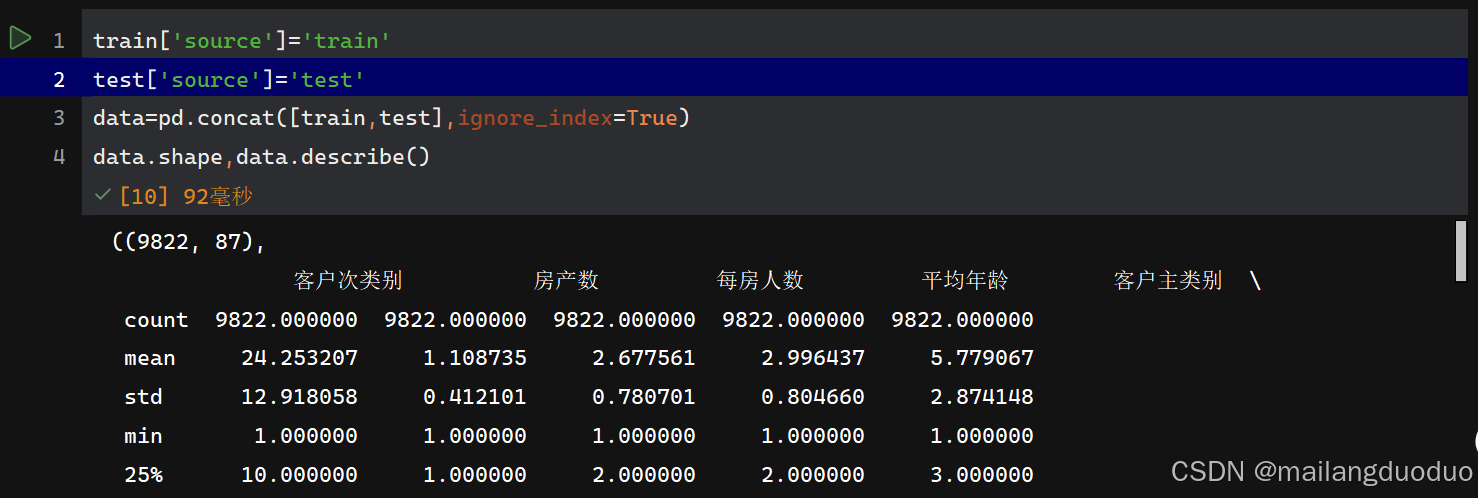
为了方便起见,我们把训练集和测试集暂时合并进行统一处理,增加一个新的属性source,用于区分训练集与测试集。具体代码如下:
train['source']='train'
test['source']='test'
data=pd.concat([train,test],ignore_index=True)
data.shape,data.describe()
执行结果:
合并完成后,我们对data统计缺失值,通过isnull()函数判断是否缺失,并除以数据长度,得出缺失率,并进行排序,显示较高的缺失率是哪些属性(特征)
代码展示:
nan_count=data.isnull().sum().sort_values(ascending=False)
nan_rate=nan_count/len(data)
nan_data=pd.concat([nan_count,nan_rate],axis=1,keys=['count','ratio'])
nan_data.head(10)
运行结果:
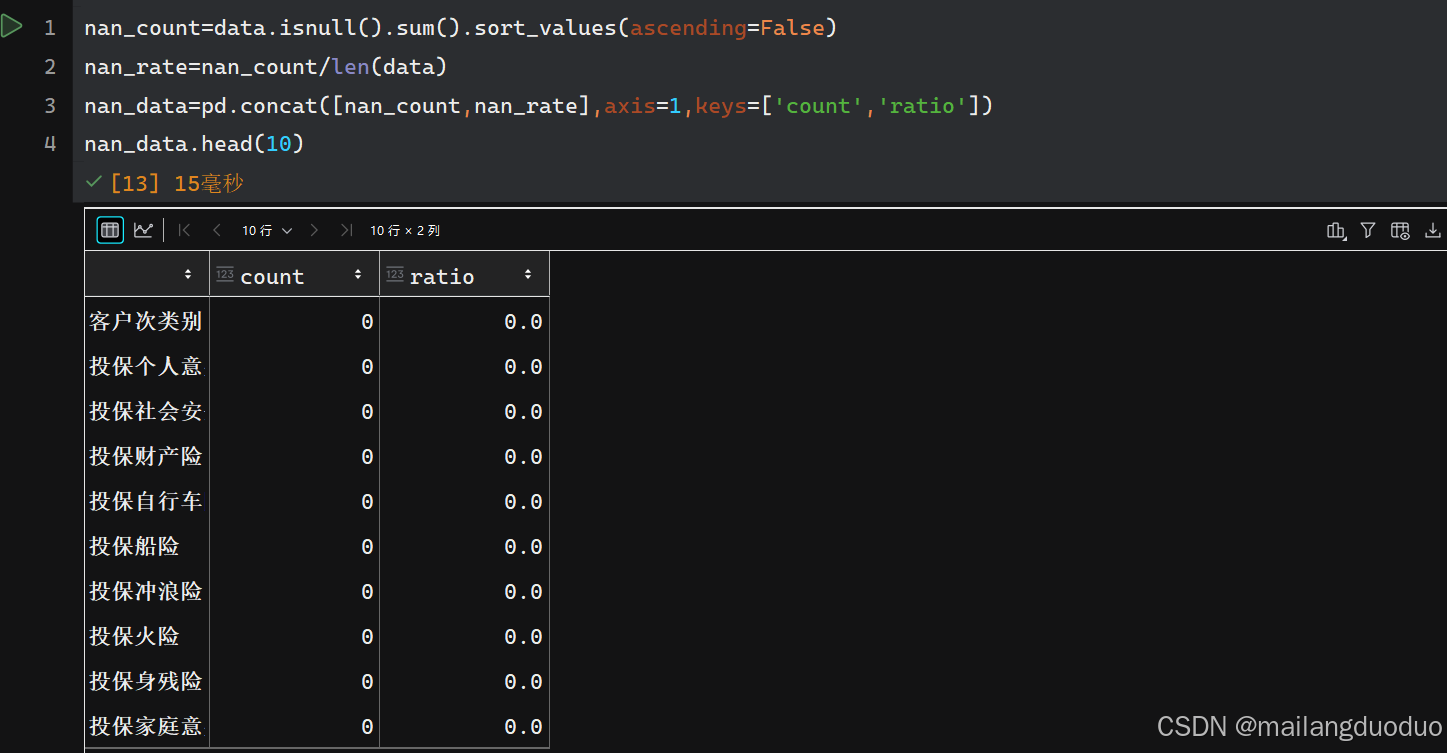
通过结果可以发现,当前数据集并无缺失值,如果有缺失值的话,你可能需要根据某种算法进行填充缺失值,或者舍弃部分样本。
2.1.2类别统计
此过程我们统计每个特征对应的类别数量,如果类别数量过多,我们需要对其进行分箱操作。
分箱操作:是数据预处理中的一项重要技术,它将连续型的数值特征转换为离散的区间或类别,进而减少类别数量
代码展示
count=data.apply(lambda x:len(x.unique()))
count.sort_values(ascending=False)
运行结果:
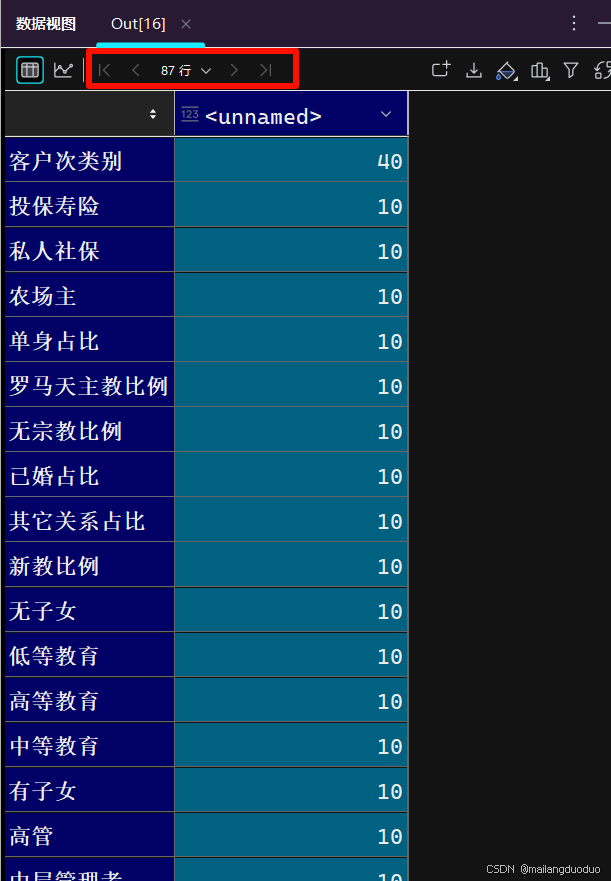
从结果来看,除客户次类别有40种取值,其他的特征取值都不高于10种,因此不需要对特征的取值进行分箱等操作。
2.1.3数据偏度
数据偏度是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字化特征,分为正偏(右偏)和负偏(左偏)。
在进行偏度计算时,我们一般基于训练集进行处理,因此需要将数据集划分为训练集和测试集,划分标准为之前新加的属性source,同时需要把添加的新属性删除,具体操作如下:
train=data.loc[data['source']=='train']
test=data.loc[data['source']=='test']
train=train.drop(['source'],axis=1)
test=test.drop(['source'],axis=1)
train.shape,test.shape

此时我们发现,source属性已经被删除了,属性数从87恢复到了86
关于计算数据偏度,可以直接调用skew()函数,具体操作如下:
skewness=train.iloc[:,:-1].apply(lambda x:x.skew())
skewness=skewness.sort_values(ascending=False)
skewness
执行结果:
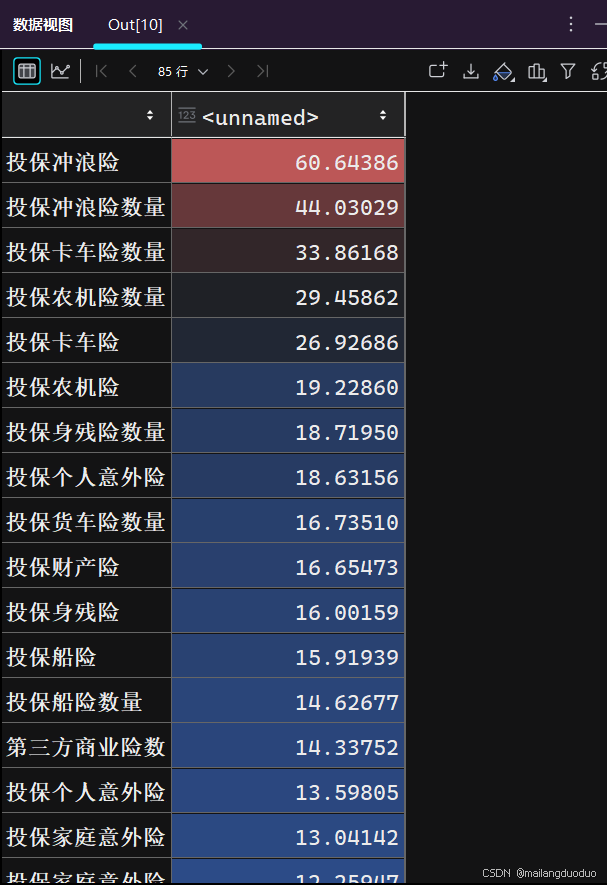
由此可见,大部分数据是偏态分布,但由于绝大多数的特征取值类型都不高于10种,因此数据分布并没有偏度显示的那么差
2.2箱图
箱图,又称箱线图,是一种用于展示数据分布的统计图表,通过四分位数、中位数和异常值等关键指标,直观反映数据的集中趋势、离散程度和对称性。
网上一位对箱图的解释(此图是借用):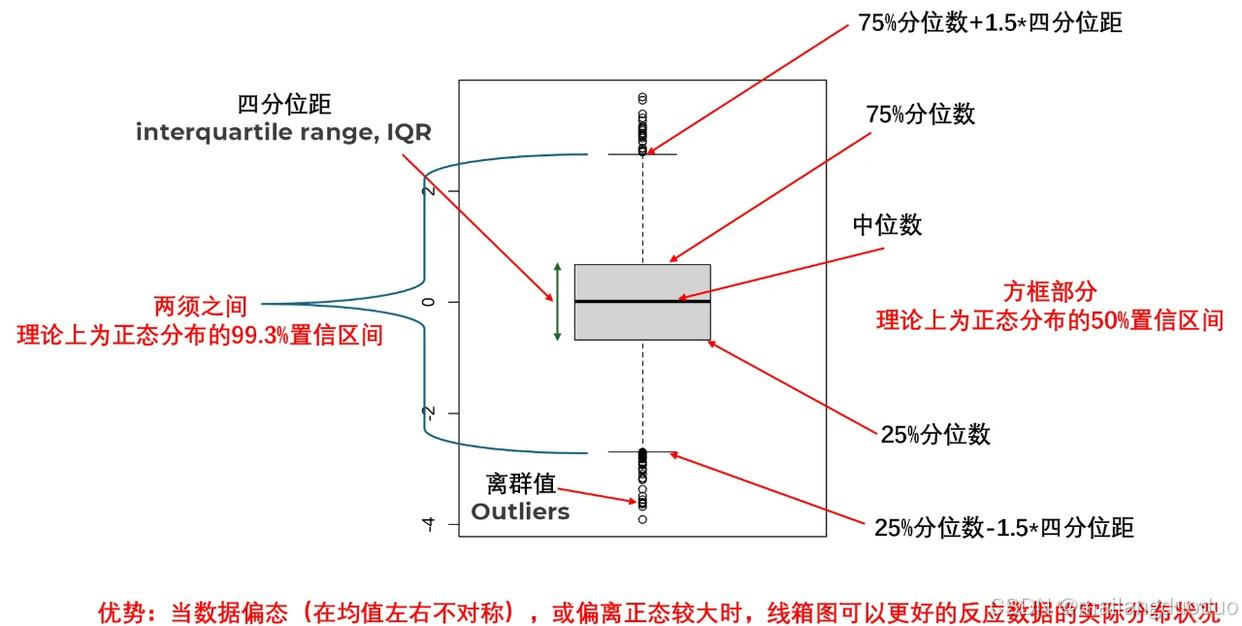
图片来源
通过箱图,我们可以观察到不同因变量对目标变量的区分度:
代码如下:
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
plot_data=train[['购买力水平','移动房车险数量']]
plot=plot_data.boxplot(column='购买力水平',by='移动房车险数量')
plot.set_ylabel('购买力水平')
plot.set_xlabel('移动房车险数量')
plt.show()
运行结果:
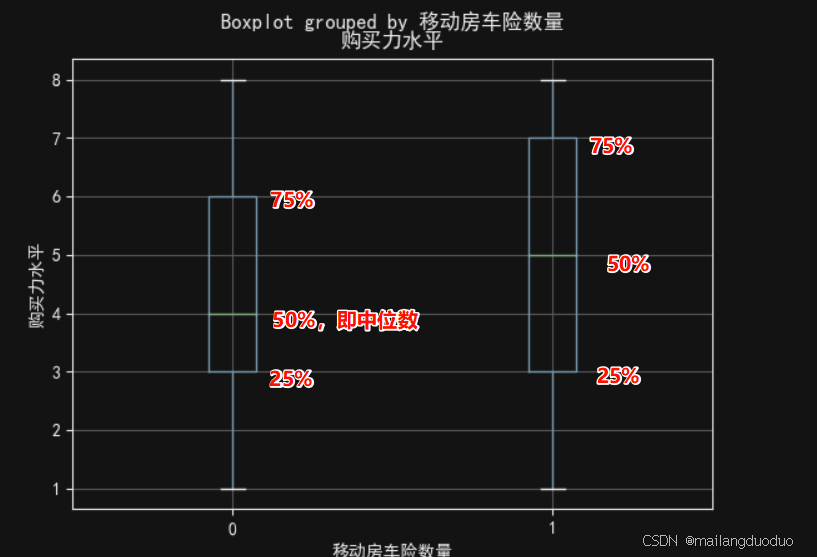
通过结果可以发现,未购买移动车房险的家庭(左边)相对于购买移动车房险的家庭(右边)购买力水平较低,数据离散程度同样低
当然你也可以画出全部的箱图,观察所有因变量对目标变量的区分度,加个循环即可,由于所画图像过多,可以进行保存在某个目录下即可,具体代码如下:
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
for i in train.columns[:-1]:
plot_data=train[[i,'移动房车险数量']]
plot=plot_data.boxplot(column=i,by='移动房车险数量')
plot.set_ylabel(i)
plot.set_xlabel('移动房车险数量')
save_path="./connections/"+i+".png"
plt.savefig(save_path)
plt.close()
执行结果:
2.3降维
通过前面的操作,我们可以发现,当前数据特征维度为85,因此需要降维,这里我们使用最简单的方式进行降维,剔除一部分特征,即特征选择。
通过计算每个特征与目标变量的相关系数,保留相关系数较大的
首先统计所有变量和目标变量(移动房车险数量)的相关系数
corr_target=train.corr()['移动房车险数量'].sort_values(ascending=False)
corr_target
结果如下:
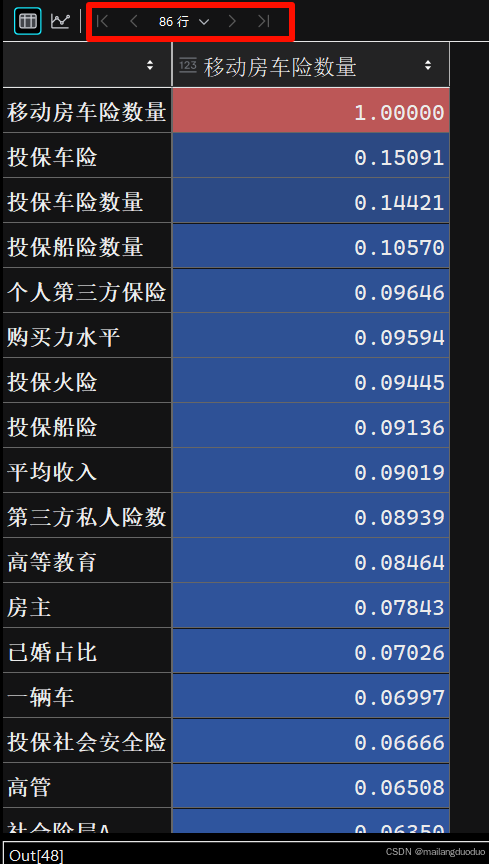
此时我们观察,选择一个合适的阈值作为特征选择的标准。
import numpy as np
corr_target=train.corr()['移动房车险数量'].sort_values(ascending=False)
important_feature=corr_target[np.abs(corr_target)>0.01].index.tolist()
len(important_feature)
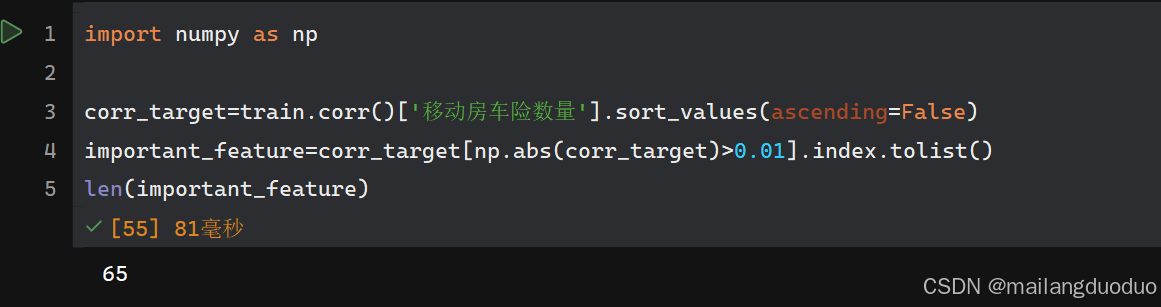
此时我们选择了65个属性,其中1个是目标变量即移动房车险数量,即选择了64个特征变量。
之后我们需要对训练集和测试集进行调整
print(train.shape,test.shape)
train=train[important_feature]
test=test[important_feature]
print(train.shape,test.shape)

同时,我们也可以将处理后的数据进行保存
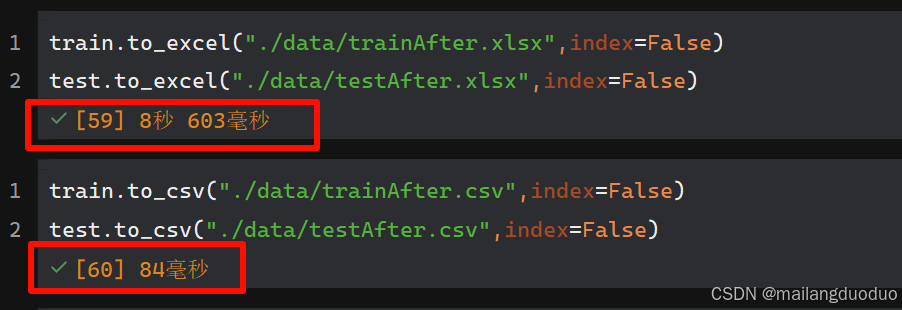
train.to_excel("./data/trainAfter.xlsx",index=False)
test.to_excel("./data/testAfter.xlsx",index=False)
执行结果如下:
-
那么问题来了:为什么很多情况下保存为
.csv格式文件呢? -
因为快,谁都不太想在文件读取和保存浪费时间是吧。
-
这也是为什么我选择使用jupyter,因为它不用每次都要重头开始运行(题外话)
2.4 小结
到此结束,我们对数据预处理部分就完成了,这里并未介绍数据预处理的全部内容,只是介绍了部分简单的,下面我们就开始选择合适的模型实现二分类问题了!!!如果你使用的是.py文件,可以新建一个了。
3.分类模型的构建
在进行模型构建前,我们需要对数据集进行加载,这里我们把该过程封装成函数来实现。
3.1数据集加载
具体代码:
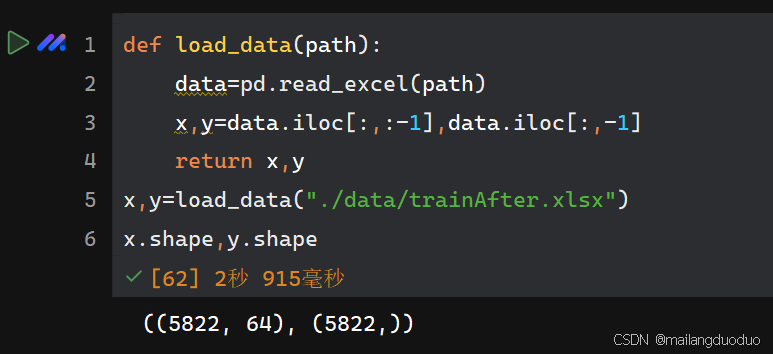
def load_data(path):
data=pd.read_excel(path)
x,y=data.iloc[:,:-1],data.iloc[:,-1]
return x,y
x,y=load_data("./data/trainAfter.xlsx")
x.shape,y.shape
运行结果:
3.2构建模型
在前面已经阐述,该问题是一个典型的二分类问题,因此可以使用多种算法如决策树、随机森林、神经网络、逻辑回归等。
3.2.1决策树
决策树是一种基于树结构进行决策的机器学习模型,模拟人类 “分而治之” 的逻辑,通过对数据特征的递归划分,最终在叶节点输出决策结果(分类或回归)。
根据划分时特征选择的方式不同,可以分为CART决策树(基于基尼指数)、ID3决策树(基于信息增益)
这些模型均在sklearn库中可以直接调用
3.2.1.1 CART决策树
由于在tree.DecisionTreeClassifier()中默认使用的是“gini”即CART决策树
代码如下:
from sklearn import tree
def build_model(x,y):
classifier=tree.DecisionTreeClassifier()
model=classifier.fit(x,y)
return model
3.2.1.2 ID3决策树
ID3决策树是基于信息增益进行划分的,因此需要修改参数criterion的值
from sklearn import tree
def build_model(x,y):
# CART决策树
# classifier=tree.DecisionTreeClassifier()
# ID3决策树
classifier=tree.DecisionTreeClassifier(criterion='entropy')
model=classifier.fit(x,y)
return model
3.2.2随机森林
随机森林(Random Forest)是一种基于集成学习(Ensemble Learning)的机器学习模型,通过构建多个决策树并结合它们的预测结果,提升模型的泛化能力和鲁棒性。
此函数被封装在RandomForestClassifier中也可以直接调用
3.2.3 多层感知机
多层感知机的核心思想是模拟人类大脑中神经元的工作方式。神经元接收来自其他神经元的输入信号,对这些信号进行加权求和,然后通过一个激活函数处理,决定是否产生输出信号。多层感知机由多个神经元组成不同的层,信息从输入层传入,依次经过隐藏层处理,最后在输出层输出结果。
此时我们的模型就算搭建完毕!!!
3.2.4 KNN算法
KNN算法:在特征空间中,相似的样本具有相似的输出。对于一个待预测的样本,该算法会在训练数据集中找到与它距离最近的 K 个样本(即 K 个近邻),然后根据这 K 个近邻的类别(分类任务)或值(回归任务)来确定待预测样本的类别或值。
为了避免来回注释麻烦,这里直接用多个函数封装模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
from sklearn.neural_network import MLPClassifier
def build_model_CART(x,y):
# CART决策树
classifier=tree.DecisionTreeClassifier()
model=classifier.fit(x,y)
return model
def build_model_ID3(x,y):
# ID3决策树
classifier=tree.DecisionTreeClassifier(criterion='entropy')
model=classifier.fit(x,y)
return model
def build_model_RF(x,y):
# 随机森林
classifier=RandomForestClassifier()
model=classifier.fit(x,y)
return model
def build_model_MLP(x,y):
# 多层感知机
classifier=MLPClassifier()
model=classifier.fit(x,y)
return model
def build_model_KNN(x,y):
# KNN
classifier=KNeighborsClassifier()
model=classifier.fit(x,y)
return model
3.3模型训练
模型构建完成,我们就开始训练即可
x,y=load_data("./data/trainAfter.xlsx")
model=build_model_CART(x,y)
model
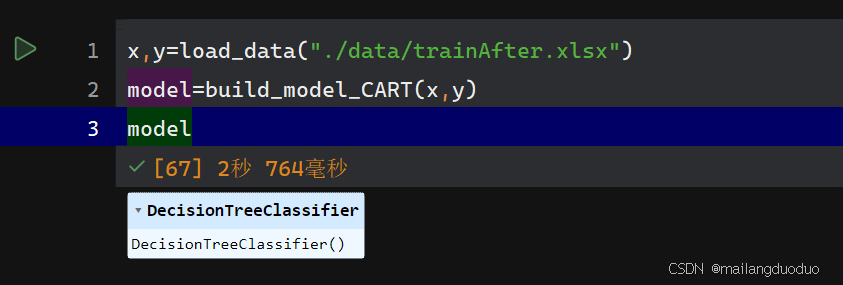
此时我们就得到一个分类器模型,此时我们需要对分类器模型进行检验,判断该模型是否能够正确分类
3.4模型验证
此处我们只验证了CART决策树的预测效果
此时我们将测试集加载进来,取一条数据来进行验证模型的预测效果。
代码如下:
test_x,test_y=load_data("./data/testAfter.xlsx")
sample=test_x.iloc[0:1,:]
label=model.predict(sample)
test_y.iloc[0],label[0]
运行结果:
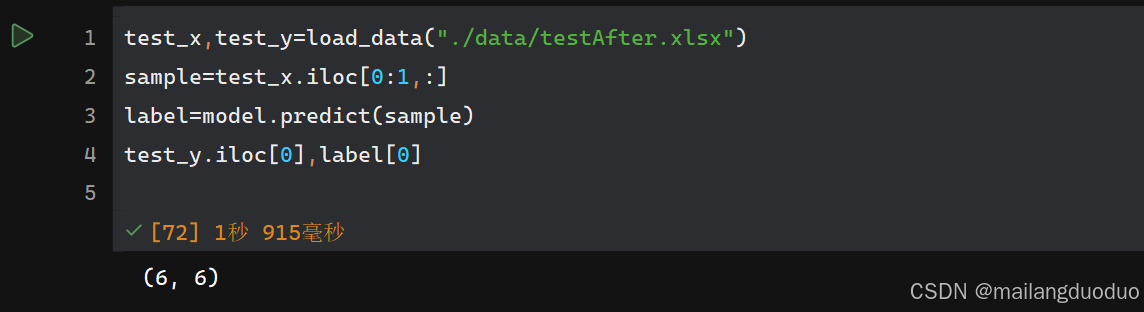
此时我们发现,当前模型预测标签和实际标签保持一致,因此可以判断,当前模型具有一定的效果。为了避免数据的偶然性,我们需要增加用于测试的样本数量。
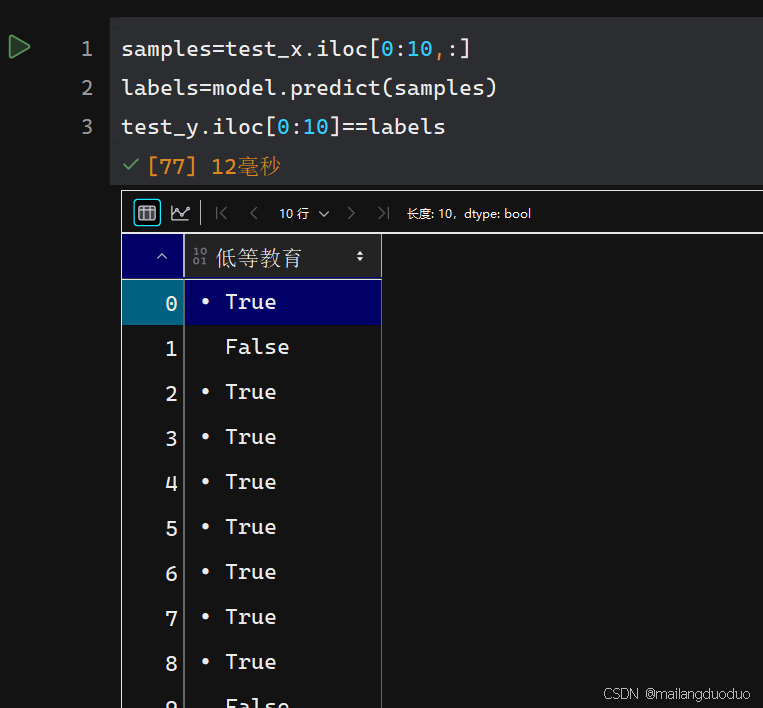
在观察结果的同时,发现列明竟然是低等教育,才发现之前在保存的时候列的顺序发生了改变,不过问题不大,直接将load_data函数修改一下即可:
def load_data(path):
data=pd.read_excel(path)
x,y=data.iloc[:,1:],data.iloc[:,0]
return x,y
因为第一列表示label
此时就可以得到如下结果:
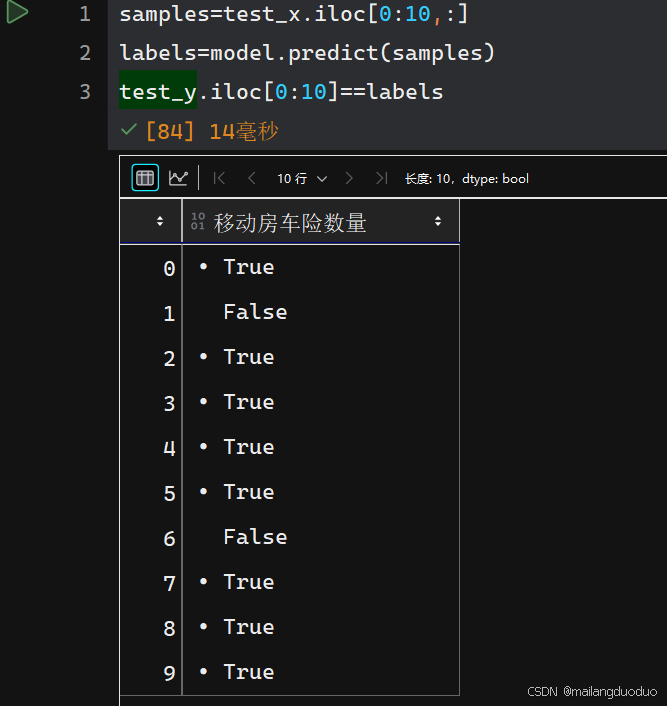
从结果上看,预测效果并不差,但为了避免偶然性,需要进一步增加测试范围
labels=model.predict(test_x)
np.sum(labels==test_y.values)/len(test_y)
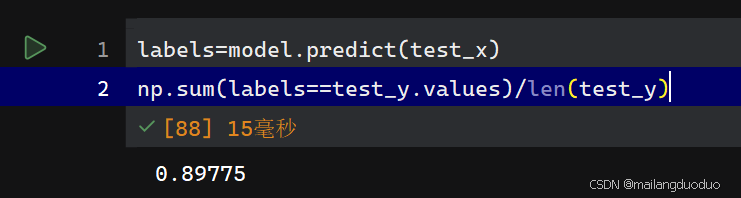
从结果上看正确率能够达到89.775%,当前模型效果不错
3.5评价指标
由于不同人任务的目的不同,所以单靠一个准确率来衡量一个模型的好坏是远远不够的。比如说某疾病的发病率为1%,现有一个预测模型来判断是否患有疾病,如果仅仅将样本判断成正例,准确率也有99%,显然准确率当前模型并不足以判断当前模型的优劣。
结语
不知不觉,写了近一万字了,这里就先撒个花啦!!!


















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}