







本周工作:我们项目的漫画生成功能需要Stable Diffusion模型连续生成多个图像来组成完整的故事情节,其中比较棘手的一个问题就是角色一致性。本周我的工作是对主流的角色一致性训练方法进行了广泛尝试,并总结出了自己的经验和方法。
一、提要:何为LoRA训练?为何选择它?
啥是LoRA?
LoRA即Low Rank Adaptation(低秩适配),其中的秩和线性代数中的矩阵的秩的概念是一致的。LoRA模型的假设:预训练模型拥有极小的内在维度(instrisic dimension),即存在一个极低维度的参数,微调它和在全参数空间中微调能起到相同的效果,同时越大的模型有越小的内在维度。基于此,Edward Hu等人提出了著名的LoRA训练方法:
对于预训练权重矩阵,LoRa限制了其更新方式,即将全参微调的增量参数矩阵
表示为两个参数量更小的矩阵
和和
的低秩近似:
其中,和
为LoRA低秩适应的权重矩阵,此时,微调的参数量从原来的
,变成了
。所以LoRA训练方法的参数量远小于原始方法,效率非常高。
在训练时,原始参数被冻结,意味着
虽然会参与前向传播和反向传播,但是不会计算其对应梯度
,更不会更新其参数。
在推理时,直接按上式将合并到
中,相比原始方法不存在推理延时。
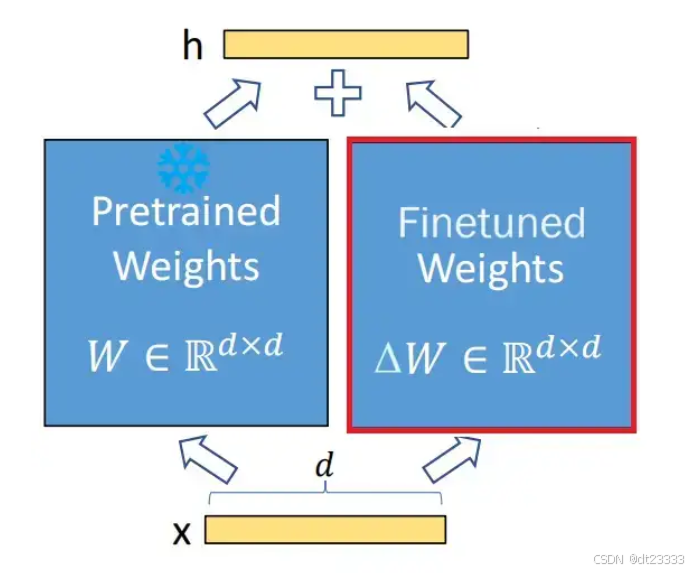
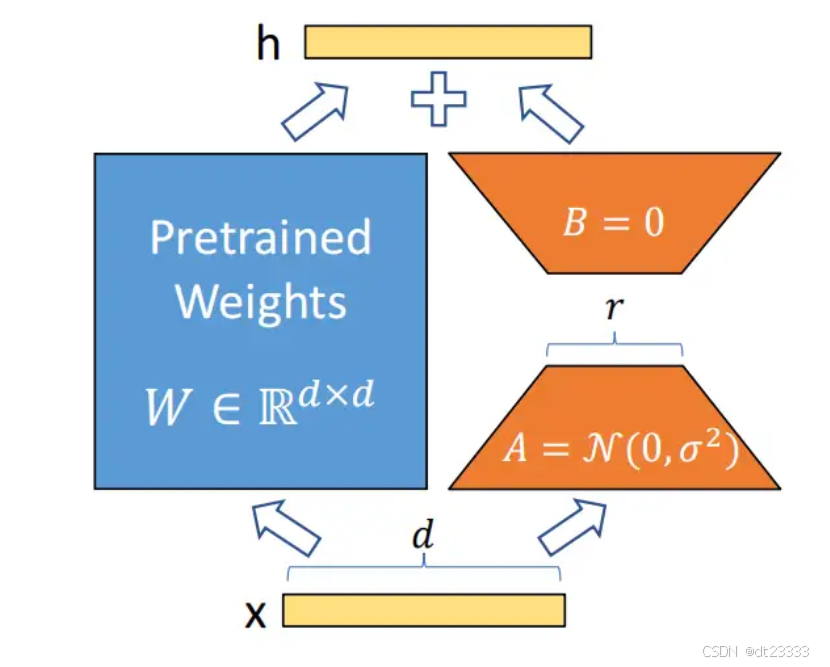
人话版:寻找两个较窄的矩阵相乘来拟合权重矩阵W,使微调效果尽可能相同。
参考文章:2106.09685,论文精读:LoRa: Low-Rank Adaptation of Large Language Models - 知乎
为啥选LoRA?
一是效率优势。我们团队使用的都是消费级显卡,最好的也不过30系列,如果使用全参数微调,对显存的要求太高,完全承担不起。使用LoRA方法训练模型,显存占用大幅降低(r=8时需要显存约6G),可在30系列GPU上训练。
二是表现优势。LoRA方法虽然是对原始方法的拟合,但在某些场景,如角色一致性上反而表现的更好、更灵活。LoRA训练时可以通过低秩更新专注于角色相关的语义空间(体态、服饰、性格等),能更精准地约束生成内容,减少角色特征漂移。并且不同角色的LoRA适配器可独立训练并动态加载,方便随时切换,无需重新加载整个模型。
人话:省时还效果好,为啥不用。
二、训练集预处理
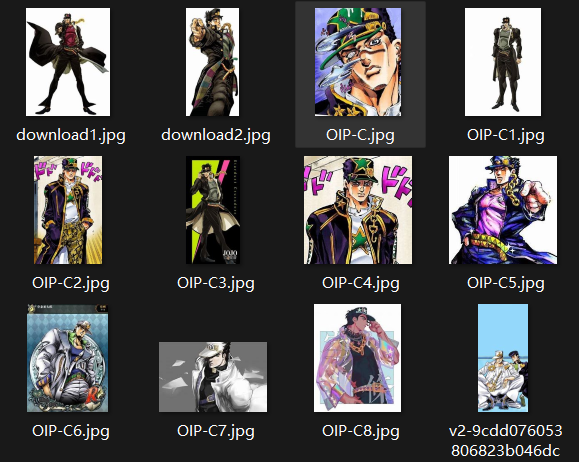
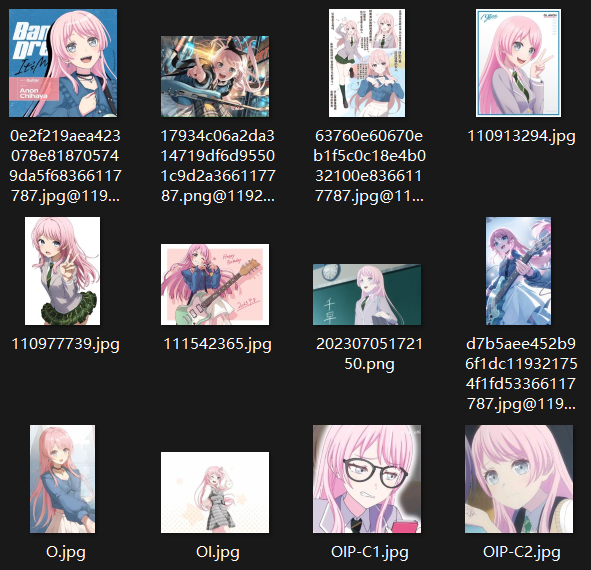
1. 收集角色图片
收集想要训练的人物的图片集,最好是白底,不要有多个人和主体不完整的图片。
角色<Jotaro Kujo>:
角色<Anon Chihaya>:
2. 裁剪统一尺寸
虽然可以通过设置不同的分辨率筒来兼容多种不同分辨率的图片,但是经过测试发现,这样会显著拖慢训练时间,筒太多还可能导致训练效果变差。所以我只设置了512*512,512*768和768*512三种分辨率筒,所有训练图片都要裁剪为符合其中的一个分辨率筒的分辨率。
裁剪工具:BIRME - Bulk Image Resizing Made Easy 2.0 (Online & Free)
此外,所有图片都应该为jpg或png格式,图片名称为0001依次往后的四位数字。
3. 为图片打标签
每个图片都需要一个对应的标签,标签内容为:触发词+画面特征描述
这里我设置模型的触发词就为角色的名字本身,画面特征描述使用反演模型工作流实现,详情见我的文章:山东大学创新项目实训(2)本地部署StableDiffusion模型与基础工作流搭建_stablediffusion本地模型-CSDN博客
打完标后效果如下:

三、训练
模型搭建:详情见我的另一篇文章:山东大学创新项目实训(4)AIGC架构设计、LoRA训练模型搭建与可视化故事板层构想-CSDN博客
训练:设置好训练集路径、桶分辨率、触发词、迭代次数等参数后点击运行,等待即可。
效果:
角色<Jotaro Kujo>:


角色<Anon Chihaya>:


同框:


角色同框下依旧保持了良好的角色一致性,但偶尔会导致图像质量下降,还会出现角色特征混淆,但概率不高。


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











