






目录
- 摘要
- Abstract
- 一、文献阅读:面向代码搜索的自注意力网络
- 1.1研究背景
- 1.2面向代码搜索的自注意力网络
- 1.3实验结果与分析
- 总结
摘要
本研究提出了一种名为SAN-CS的自注意力联合表示学习模型,用于代码搜索。通过利用自注意力网络构建代码搜索模型,SAN-CS能够充分捕捉代码片段和描述的上下文信息,并建立它们之间的语义关系。实验结果表明,SAN-CS在性能和执行效率方面优于现有模型。
Abstract
This study proposes a self-attentive joint representation learning model called SAN-CS for code search. By utilizing a self-attentive network to construct a code search model, SAN-CS is able to adequately capture the contextual information of code fragments and descriptions and establish the semantic relationships among them. Experimental results show that SAN-CS outperforms existing models in terms of performance and execution efficiency.
一、文献阅读:面向代码搜索的自注意力网络
1.1研究背景
代码搜索是软件开发中的一项频繁活动,可以帮助开发人员在项目中找到合适的代码片段。它有助于提高开发人员的工作效率,缩短产品开发周期。因此,一个高性能的代码搜索工具对于开发人员来说是必不可少的。
然而,设计一个实用的代码搜索工具是非常具有挑战性的。在过去的几年中,许多基于信息检索( Information Retrieval,IR )的代码搜索方法被提出,这些方法主要集中于度量查询和代码片段之间的文本相似度。因此,它们忽略了自然语言所表达的高层描述与底层源代码之间的语义关系,这无疑会影响代码搜索的性能。
深度学习技术可以自动学习特征表示,并建立输入和输出之间的映射关系。换句话说,深度学习对于弥合代码片段与其描述之间的语义鸿沟是非常有帮助的。在这种考虑下,Gu等人完全使用深度学习技术构建了一个模型,命名为DeepCS1 (深度代码搜索)。具体来说,DeepCS利用两个单独的LSTM (长短时记忆)嵌入代码片段及其对应的描述,分别映射到两个不同的向量空间,然后通过学习到的联合嵌入模型对齐这两个向量空间。在完成这一步之后,整个模型返回最相似的代码片段。但是这个模型依然有缺陷,原因有二:( 1 ) LSTM由于其特殊的架构,执行效率较慢。( 2 )代码和自然语言是不同模态的数据。如果我们能够在执行嵌入操作之前建立这些不同模态数据之间的语义关系,那么将它们嵌入到同一向量空间是有益的。
基于上述考虑,本文提出了一种自注意力联合表示学习模型SAN - CS2(用于代码搜索的自注意力网络)。具体来说,我们直接使用自注意力网络来学习上下文表示,分别用于代码片段和它们的查询,由于自注意力网络可以捕获全局语义关系(上下文信息)并具有较高的执行效率的优势。此外,受Transformer利用编码器-解码器注意力网络构建源语言句子和目标语言句子之间语义关系的启发,我们进一步利用自注意力网络构建额外的联合表示网络,用于构建语义关系。
1.2面向代码搜索的自注意力网络
图1概述了我们提出的SAN - CS模型。SAN - CS的输入包含两部分,一部分是由方法名、API和令牌序列组成的代码片段,另一部分是查询序列。然后,将这4个序列分别嵌入到对应的代码向量和查询向量中,其中代码向量通过合并方法名向量、API向量和令牌向量得到。然后,SAN - CS学习编码向量和查询向量的联合表示。
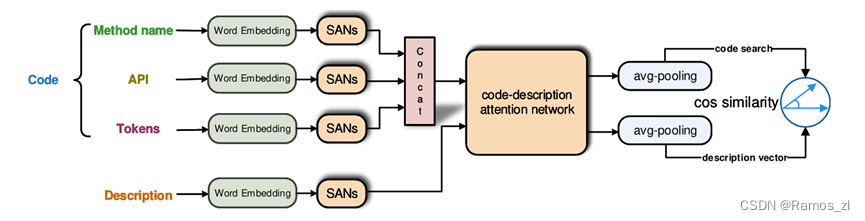
一、代码嵌入
每个代码片段由三个元素组成:方法名序列、API序列和令牌序列。我们通过以下四个步骤来获得最终的码向量。
- 方法名称的嵌入
对于给定的方法名称序列,如“openFile”,我们按照广泛采用的驼峰命名惯例将其拆分为词序列。与API和令牌序列不同,方法名称序列的长度很短(方法名序列的最大长度约为6 ),但它是对整个代码段的功能摘要,因此我们用来嵌入方法序列的模型应该具有较强的提取语义信息的能力。在LSTM中,我们使用最后一个时间步的输出来表示句子的全部信息。在我们的观点中,我们认为用一个固定长度的向量表示一个句子是不够的,表示维度为128,并且通过实验,我们还发现LSTM倾向于学习特征。虽然方法名较短,但它简明扼要地概括了代码片段的功能,从而捕获了方法的语义信息。与LSTM相比,自注意力网络能够关注句子中的所有单词,并且能够为每个单词建立上下文关系,因此能够熟练地提取语义信息,非常适合嵌入方法名称序列。在上述考虑下,我们使用基于自注意力机制的自注意力网络而不是LSTM。
具体地,给定一个长度为I的方法名序列Sn = { s1,…,si },我们假设序列中的每个词都被具有相同表示维数d的词嵌入层嵌入。首先将Sn转化为query向量Q_n\in R^{I\times d}、key向量K_n\in R^{I\times d}和value向量V_n\in R^{I\times d},并赋予3个个体权重度量W_Q\in R^{d\times d}、W_k\in R^{d\times d}、和W_v\in R^{d\times d}。
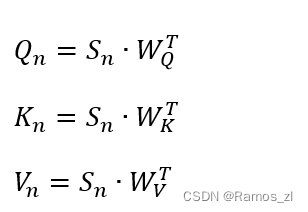
在完成上述步骤后,我们使用自注意力机制来捕获方法名序列的语义信息。具体来说,可以通过以下方式进行计算:
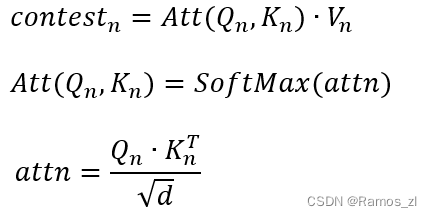
当完成这些步骤时,我们可以通过将Context向量应用到一个简单的位置全连接前馈网络中,得到最终的输出V_{name}\in R^{I\times d}。 - API的嵌入
与方法名序列不同的是,大多数API序列都比较长。因此,对于LSTM模型来说,很难很好地捕获长距离依赖,也就是说它不能充分捕获API序列的语义信息。因此,这将损害代码搜索模型的性能。而自注意力网络可以解决这个问题。此外,由于LSTM结构的限制,无法实现并行计算,因此需要更多的时间来训练LSTM模型。对于自注意力网络,它可以像CNN一样实现并行计算,因此可以充分利用GPU来训练我们的模型。
与方法名序列嵌入类似,给定一个长度为N的API序列Sa = { s1,…,sn },假设序列中的每个单词都被表示维度为d的词嵌入层嵌入。首先将Sa转化为query向量Q_a\in R^{I\times d}、key向量K_a\in R^{N\times d}和value向量V_a\in R^{N\times d},然后利用自注意力机制捕获API序列的语义信息。最后,将自注意力网络向量的输出应用到一个简单的位置全连接前馈网络中,得到最终的输出V_{api}\in R^{N\times d}。
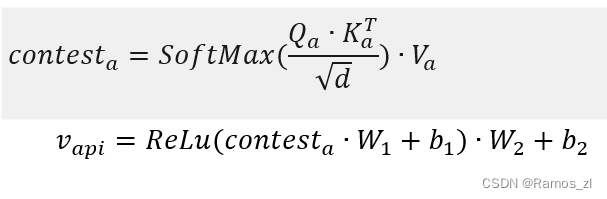
- token的嵌入
令牌序列是从方法体中提取出来的,由一系列的单词组成。通过数据预处理阶段,我们发现令牌序列中只包含了代码片段的信息关键字,这意味着令牌之间的位置关系不强。一个简单的例子表明,虽然我们交换了两个令牌(如变量名)的位置,但是代码片段的功能是不变的。这些标记虽然位置关系较弱,但却丰富了语义信息和关系。基于以上考虑,我们认为仅仅使用一个简单的多层感知器( MLP )是无法为每个单词建立语义关系的,因此我们选择自注意力网络来代替MLP来嵌入令牌序列。之所以这样选择,是因为自注意力网络通过加权平均操作可以关注句子中的所有单词而不考虑它们的位置,从而忽略了单词(对于其他序列嵌入,我们增加了额外的位置编码来获取位置信息)的相对关系
具体来说,给定一个长度为M的令牌序列St = { s1,…,sm },我们假设序列中的每个单词都被表示维度为d的词嵌入层所嵌入。首先将St转化为query向量Q_t\in R^{M\times d}、key向量K_t\in R^{M\times d}和value向量V_t\in R^{M\times d},然后利用自注意力机制捕获API序列的语义信息。最后,将自注意力网络向量的输出应用到一个简单的位置全连接前馈网络中,得到最终的输出V_{token}\in R^{M\times d}。
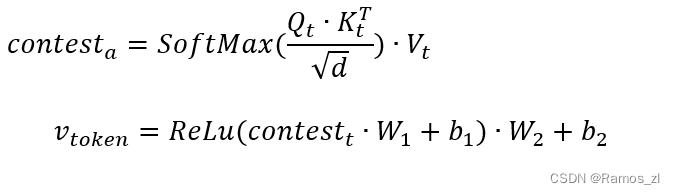
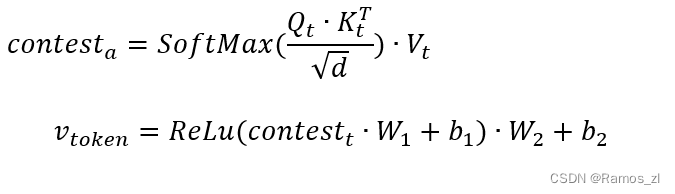
4 嵌入合并
在完成方法名序列、API序列和tokens序列的嵌入时,只需将v_{name}、v_{api}和v_{token}进行简单的拼接,即可得到代码嵌入V_{code}\in R^{(I+N+M)\times d}
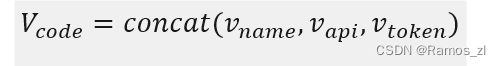
二、描述嵌入
代码描述包含了能够直接反映开发者查询目的的语义信息。因此,与代码嵌入类似,我们也采用自注意力网络来嵌入代码描述序列。给定一个长度为J的代码描述序列Sd = { s1,…,sj },我们假设序列中的每个词都被具有相同表示维数d的词嵌入层嵌入。首先将Sd转化为query向量Q_{d1}\in R^{J\times d}、key向量K_{d1}\in R^{J\times d}和value向量V_{d1}\in R^{J\times d},然后利用自注意力机制捕获API序列的语义信息。最后,我们将自注意力网络向量的输出应用到一个简单的基于位置的全连接前馈网络中,得到最终的输出V_{desc}\in R^{J\times d}。
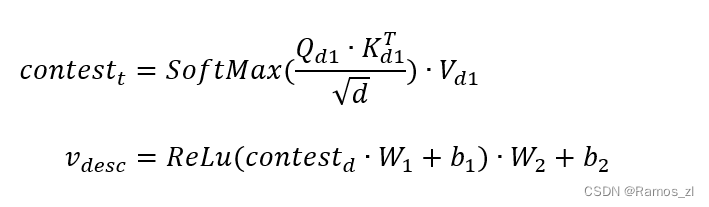
三、代码描述注意力
在完成代码嵌入及其配对的代码描述嵌入时,可以收集<V_{code},V_{desc}>对。这里H等于I + N + M。为了更好地将<V_{code},V_{desc}>对映射到同一个向量空间,我们在将它们映射到同一个向量空间之前,通过代码描述注意力网络(自注意力网络的一种变体)对它们进行了额外的联合嵌入。具体来说,我们首先将V_{code}转化为查询向量Q_c\in R^{H\times d}和值向量V_c\in R^{J\times d},然后将V_{desc}转化为密钥K_d\in R^{J\times d}和值V_d\in R^{J\times d},并定义了三个相应的权重度量。
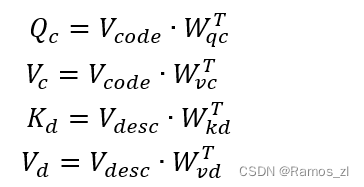
然后,我们计算代码描述注意力矩阵A\in R^{H\times d}。
- token的嵌入
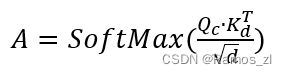
代码描述注意力矩阵允许V_{code}和V_{desc}在联合嵌入阶段相互关注。并且我们可以将代码描述注意力网络的输出表示如下。
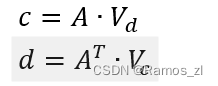
式中:c为Vc与Vd联合嵌入,d为Vd与Vc联合嵌入。
接下来,我们分别对c和d进行平均池化操作,得到语义向量C∈Rd和D∈Rd。此外,在实验中,我们还发现最大池化使得我们的模型失效。一种合理的解释是,自注意力网络为每个词向量构建一个上下文向量,而最大池化只捕获值最高的特征,这明显伤害了每个词之间的语义关系。具体定义如下:

4. 模型训练
下面给出SAN - CS模型的训练细节。为了使SAN-CS学习到代码片段和描述的联合表示,我们希望我们的模型能够使具有相似语义的代码和描述向量在向量空间中尽可能地接近。此外,对于一个随机码向量c,我们也希望我们的模型能够对其正描述给出一个较高的相似度,对其他负描述给出一个较低的相似度。基于以上考虑,我们通过最小化训练时间内的秩损失来达到我们的目的。
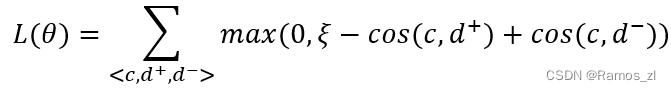
式中:θ为模型参数,T为训练SAN - CS模型的数据集,cos (⋅)用于计算相似度。从秩损失函数中,我们注意到对于每个码向量c,存在一个正描述向量d +和一个负描述向量d -,它促使c和d +具有高相似性,而c和d -具有低相似性。
在训练时,我们利用Adam优化器来优化我们的秩损失函数。SAN - CS模型得到代码片段和描述的基本表示,然后这两种表示通过代码描述注意力网络分别生成代码片段和描述的联合表示。在反向传播阶段,更新后的模型参数θ引导代码描述注意力网络生成能够最小化秩损失函数的代码片段和描述的联合表示。
1.3实验结果与分析
- 模型有效性
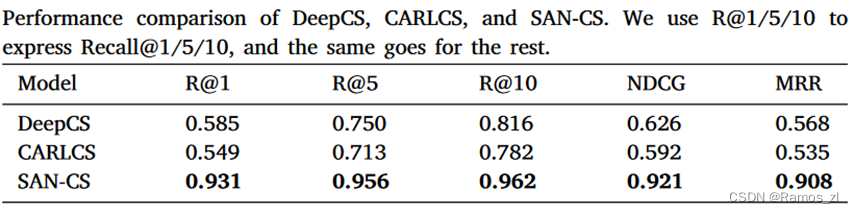
展示了最先进的模型DeepCS和我们提出的SAN - CS在不同度量下的性能。在Recall @ k指标上,SAN - CS比DeepCS和CARLCS分别平均提高了34.8 %和42.2 %。在NDCG指标上,SAN - CS模型比DeepCS和CARLCS分别提高了47.1 %和55.6 %。在MRR指标上,DeepCS和CARLCS的得分分别为0.568和0.535。SAN - CS在MRR指标上分别获得了59.9 %和69.7 %的提升。所有这些结果表明,我们提出的模型SAN - CS比DeepCS和CARLCS更有效。此外,我们还可以观察到,虽然CNN比LSTM具有更快的执行效率,但LSTM比CNN更适合对序列进行编码。
2. 模型效率
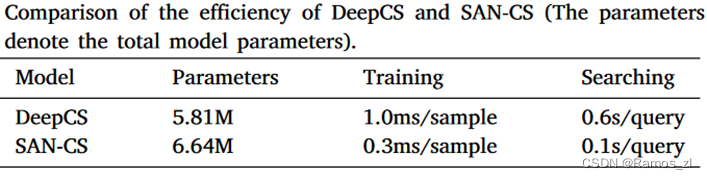
在表2中,我们比较了两个模型数据集上的总参数、训练时间和搜索时间。为了公平地比较模型效率,我们在一台服务器搭载一台Tesla V100-SXM2 GPU、32GB显存的相同实验环境下训练这两个模型。实验结果表明,在SAN - CS参数较多的情况下,Deep CS对每个样本的训练时间约为1.0 ms,对每个查询的搜索时间约为0.6 s,而SAN - CS对单个样本的训练时间约为0.3 ms,对每个代码查询的响应时间约为0.1 s。这表明,与DeepCS相比,SAN - CS在执行效率上有显著提升,也意味着SAN - CS在实际应用中比DeepCS更适用。
3. 自注意力网络的效果
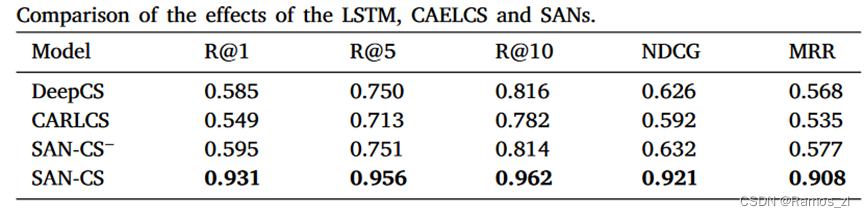
在SAN - CS中,自注意力网络和联合表示网络起着至关重要的作用,对于代码和描述嵌入,我们直接利用自注意力网络来表示代码片段及其查询。为了研究每个自注意力网络是否都能提高表示效果,我们设计了一种不使用联合表示网络的SAN - CS变体( SAN-CS - ),并将其与DeepCS、CARLCS和SAN - CS进行了比较。因此,如果自注意力网络具有更强的表征学习能力,那么SAN - CS和SAN - CS -应该比DeepCS和CARLCS表现更好。
表3的结果表明SAN - CS -获得了0.595 / 0.751 / 0.814的Recall @ 1 / 5 / 10分数,0.632的NDCG分数和0.577的MRR分数,从中我们观察到SAN - CS -与DeepCS和CAELCS相比仅有轻微的增加。这些实验结果不仅支持了我们的想法,即分别嵌入代码片段和描述可能会导致代码搜索模型的性能瓶颈,也说明了CNN不适合序列建模。当我们将联合表示网络补充到SAN - CS -上时,结果表明该网络在所有评价指标上对SAN - CS -都有极大的提升,这表明联合表示学习有利于建立代码向量和描述向量之间的语义联系。
4. 参数设置的影响
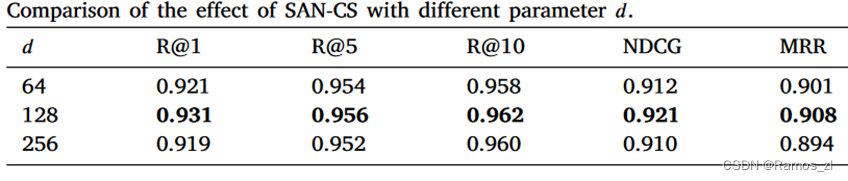
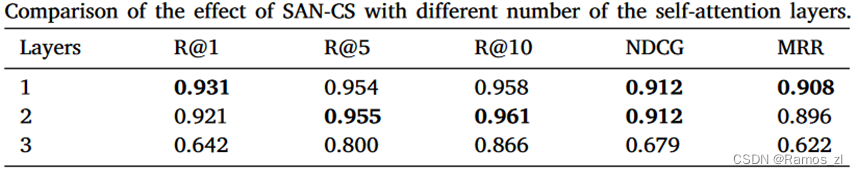
SAN - CS的效率受到表示维数d的大小和自注意力层的个数的影响。在表4中,我们进行了三组不同d的实验,实验结果表明,当我们将表示维数d设置为128时,SAN - CS可以得到最好的性能。至于表5,我们可以观察到,如果考虑到总的模型参数,单个自注意力层最适合SAN - CS,这与Transformer需要6个自注意力层才能达到最先进的结果不同。
总结
本文提出了一种基于自注意力网络的代码搜索模型SAN - CS。不同于使用LSTM或CNN,我们首先直接使用自注意力网络来表示代码片段及其查询,然后使用联合表示网络对代码和查询向量进行额外的联合表示。通过完成这些步骤,SAN - CS可以学习到代码片段及其查询的联合表示。实验结果表明,SAN - CS在MRR指标上优于DeepCS和CARLCS - CNN。此外,SAN - CS比DeepCS具有更快的执行效率。因此,自注意力网络和联合表示学习适用于基于深度学习的代码搜索方法。我们未来的工作主要集中在两个方面。一方面,同时将其与代码片段的语义信息相结合,进一步提高了我们提出的模型的性能。另一方面,我们计划将自注意力网络应用到代码摘要等其他软件工程任务中,这也可能得益于这种更有效的特征提取网络。















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









