






写在前面
本节将要介绍一种新的特征融合方式,这篇论文的方法叫做堆叠注意力网络。那么从本节开始,所有的模型我会把原理讲清楚,然后用一个维度较低的例子带各位同学走一遍模型的前向传播。
堆叠注意力网络(SANs)其思想是用编码后的文本向量去扫描编码后的图像的每个区域,然后得到每个区域的注意力分数,将注意力分数乘到每个区域上,然后求和,得到一个图像表示向量,然后将图像表示向量与编码后的文本向量求和得到融合后的向量。可能这样说有点抽象,没关系,相信你看完下面的内容再回过头来看这句话就会醍醐灌顶!
论文地址
https://arxiv.org/pdf/1511.02274.pdf
模型讲解
0.模型总示意图
(1)论文给的模型图
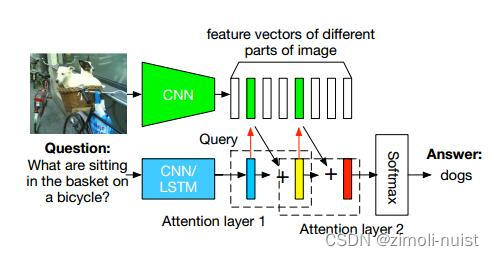
Fig1:Stacked Attention Network for Image QA
这个图现在你看肯定是难以理解,那么可以暂时先看我给画的图,然后学完本篇博客再回过头看一下这张论文原图。
(3)博主的模型图
参考:下面这个博主画的图。
《Stacked Attention Networks for Image Question Answering》论文解读与实验_堆叠注意力网络-CSDN博客
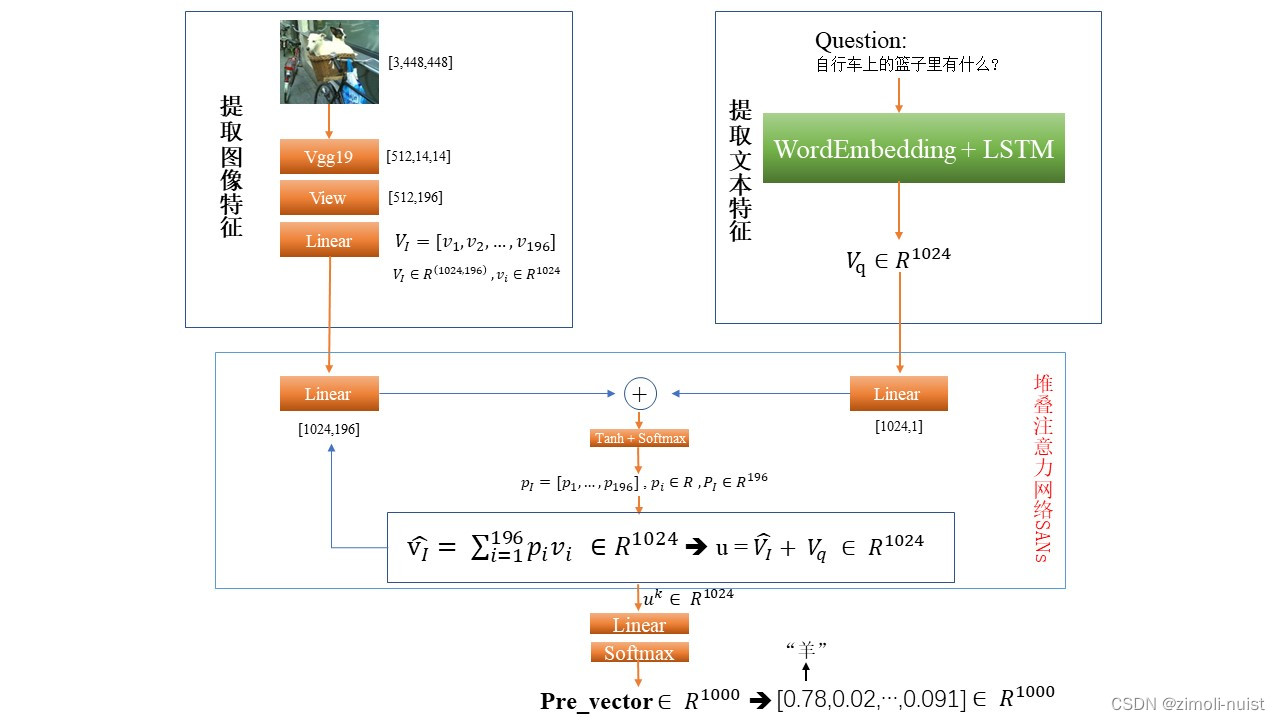
Fig2:My Stacked Attention Network
下面让我们逐步来讲解这张图,总共分为四个部分:提取图像特征、提取文本特征、SANs做特征的融合、线性层做分类输出。
1.提取图像特征
图像这里我们依然使用一个预训练好的VGG19,不过与之前不同的是,现在我们的输入图像是[3,448,448],因此经过VGG19提取出来特征的大小应该是[512,14,14],然后我们将第二个维度和第三个维度进行View,变成[512,196],也就是这样图现在有196个区域,每个区域现在用512维的向量表示。
然后原论文说为了和文本向量的特征维度相匹配,这里多加了一个线性层,将[512,196]变成[1024,196]。经过线性层后的矩阵我们记为:,其中
代表每个区域的特征向量,共196个区域。

Fig3:提取图像特征
2.提取文本特征
文本这里我们首先会按照词表进行一次独热编码,然后将独热编码送入Embedding层,进行词嵌入编码,将原来的文字编码为向量,然后送入LSTM层,取LSTM层最后一个隐藏单元的输出作为文本的特征表示。具体计算如下:
(1):独热编码
假设我们有一个问题已经用独热编码编好了,记为:代表第i个词的独热编码。
(2):Embedding
Embedding层会有一个词嵌入矩阵,使得:就是编码后的词向量表示。编码后的句子用
表示。
(3)LSTM
将,t=1,2,...,T 依次送入LSTM:
。将LSTM最后一个隐层状态作为输入问题的特征向量。即:
。
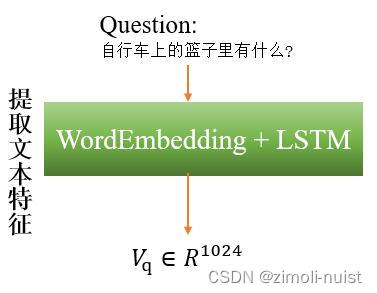
Fig4:提取文本特征
3.SANs
经过上面两步,我们已经拿到了图像的特征:和文本的特征:
。现在我们依次将
和
送入到两个线性层做一次映射然后再相加。公式如下:
Step1:
⊕
, 其中:
, ⊕是逐元素加法而不是普通矩阵加法。那么
。
Step2:
然后我们再经过一个线性映射和Softmax将映射为一个注意力特征分布。公式为:
。其中
是图像第i个区域
的注意力分数。
Step3:
然后将196个区域的与它们对应的注意力分数
相乘求和。得到一个特征:
。
然后将与
相加得到融合后的特征:
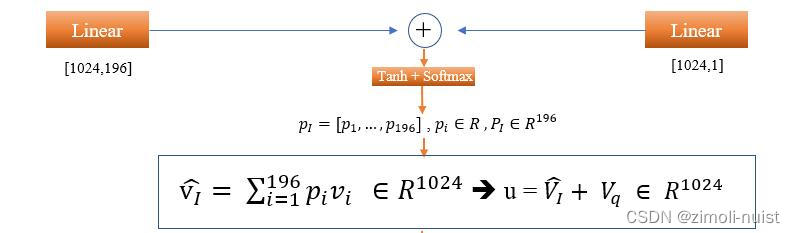
Fig5:SANs过程
这只是一层的注意力,然后可以堆叠k层,也非常简单,我们上面不是已经拿到了u嘛,这个u我们就记为,代表是第一次拿到的融合特征。然后让
和
重复Setp1-Step3即可。具体迭代公式如下:
⊕
其中
4.分类输出
假设上面已经拿到了迭代k次后的融合特征,然后我们的任务是做1000分类。令:
,其中:
。这个p就是作为最后的概率输出啦~~
代码
1.提取图像特征
#提取图像特征
class ImageEncoder(nn.Module):
def __init__(self,embed_size):#embed_size = 本文的1024
super(ImageEncoder, self).__init__()
vgg19 = models.vgg19(pretrained=True).features #加载预训练模型的features部分
self.cnn = vgg19
self.fc = nn.Linear(512,embed_size)
def forward(self,image): #image_size = [batch_size , 3 , 448 , 448]
with torch.no_grad(): #冻结cnn部分的参数
features = self.cnn(image) #[batch_szie,512,14,14]
features = features.view(features.size(0),512,-1) #[batch_size,512,196]
V_I = self.fc(features) #[batch_size,1024,196]
return V_I
2.提取文本特征
#提取文本特征代码
class QuestionEncoder(nn.Module):
def __init__(self,qst_vocab_size, word_embed_size, embed_size, num_layers, hidden_size):
super(QuestionEncoder, self).__init__()
"""
参数解释:
qst_vocab_size : 问题词汇表的大小
word_embed_size : 问题经过Embedding层,嵌入词的维度。
embed_size : 和ImageEncoder里面的embed_size一样
num_layers : LSTM有多少层
hidden_size : 每个隐藏层有多少个隐藏单元
"""
self.embedding = nn.Embedding(qst_vocab_size,word_embed_size)
self.tanh = nn.Tanh()
self.lstm = nn.LSTM(word_embed_size, hidden_size, num_layers,batch_first=True)
self.fc = nn.Linear(2*num_layers*hidden_size, embed_size)
def forward(self,question):
qst_vec = self.embedding(question) ## [batch_size, max_qst_length, word_embed_size]
_,(hn,cn) = self.lstm(qst_vec)
"""
lstm有三个输出:
out输出:nn.LSTM 的 forward 方法返回的第一个值 out 是 LSTM 在所有时间步的输出
out 的形状为 (batch_size,seq_length, num_directions * hidden_size),其中 seq_len 是序列长度,
batch 是批量大小,num_directions 是方向数量(单向为 1,双向为 2),hidden_size 是隐藏状态的大小。
hn输出:lstm的最后一个时刻的隐层状态其形状为 (batch_size, num_layers * num_directions, hidden_size)
cn输出:最后一个时间步的记忆细胞 cn (batch_size, num_layers * num_directions, hidden_size)。
"""
qst_feature = torch.cat((hidden, cell), 2) # [batch_size, num_layers=2, 2*hidden_size=1024]
qst_feature = qst_feature.reshape(qst_feature.size()[0], -1) # [batch_size, 2*num_layers*hidden_size=2048]
V_Q = self.tanh(self.fc(qst_feature)) # [batch_size, embed_size]
return V_Q3.SANs块
class SANsBlock(nn.Module):
def __init__(self, num_channels, embed_size, dropout=True):
"""Stacked attention Module
"""
super(SANsBlock, self).__init__()
self.ff_image = nn.Linear(embed_size, num_channels) #在我们原理部分写的是embed_size = num_channels = 1024
self.ff_questions = nn.Linear(embed_size, num_channels)
self.dropout = nn.Dropout(p=0.5)
self.ff_attention = nn.Linear(num_channels, 1)
def forward(self, vi, vq):
"""Extract feature vector from image vector.
"""
V_I = self.ff_image(vi) #[batch_size , 196 , num_channels]
V_Q = self.ff_questions(vq).unsqueeze(dim=1)#[batch_size , 1 , num_channels] 为了能做按元素加法,我们在V_Q的第二个维度上增加了一个维度
ha = torch.tanhV_I + V_Q)#[batch_size , 196 , num_channels]
if self.dropout:
ha = self.dropout(ha)
ha = self.ff_attention(ha)#[batch_size , 196 , 1]
# self.ha = ha
pi = torch.softmax(ha, dim=1)#[batch_size , 196 , 1]
vi_attended = (pi * vi).sum(dim=1)
u = vi_attended + vq #[batch_size , 196 , 1]
return u4.模型汇总
class SANModel(nn.Module):
# num_attention_layer and num_mlp_layer not implemented yet
def __init__(self, embed_size, qst_vocab_size, ans_vocab_size, word_embed_size, num_layers, hidden_size):
super(SANModel, self).__init__()
self.num_attention_layer = 2
self.num_mlp_layer = 1
self.img_encoder = ImgAttentionEncoder(embed_size) # [batch_size, 196, embed_size]
self.qst_encoder = QstEncoder(qst_vocab_size, word_embed_size, embed_size, num_layers, hidden_size)
"""
下面这行代码将Attention这个模块重复num_attention_layer次
"""
self.san = nn.ModuleList([SANsBlock(512, embed_size)]*self.num_attention_layer)
self.tanh = nn.Tanh()
self.mlp = nn.Linear(embed_size, ans_vocab_size)
self.dropout = nn.Dropout(0.5)
self.attn_features = [] ## attention features
def forward(self, img, qst):
img_feature = self.img_encoder(img) # [batch_size, 196 , embed_size]
qst_feature = self.qst_encoder(qst) # [batch_size, embed_size]
vi = img_feature
qi = qst_feature
for attn_layer in self.san:
u = attn_layer(vi, qi)
# self.attn_features.append(attn_layer.pi)
combined_feature = self.mlp(self.dropout(u))
return combined_feature例子
好了看完了原理部分和代码部分,相信你已经对堆叠注意力网络有了一定的了解。为了加深你的印象,下面我将会用一个简单的小例子带你走一遍前向传播(反向传播可以自己私下试试,无非就是梯度下降去更新那些参数)。
假设我们现在有一张图像是[1,2,2],代表1通道,长和宽均为2。然后假设有一个文本“自行车上的篮子里有什么”。我们下面依次对图像和文本做嵌入:
对于图像:
一个[1,2,2]的图像,假设经过VGG19变成了[2,3,3](这里我们用的维度较低方便计算),即两个通道,长和宽均为3。假设这个[2,3,3]的张量如下:
然后我们经过View操作把上面这个张量变成[2,9],即共9个区域,每个区域用一个2维的向量表示。然后再经过一个线性层变为[2,9](这里为了计算方便我们就不去增加每个区域的维度了)。
, 比如
是图像第1个区域的特征向量。
对于文本:
首先我们对文本进行分词,假设分词后的文本为:“自行车/上/的/篮子/里/有/什么/”,共7个词,然后经过独热编码的映射,记为 。然后我们将Q送入Embedding层,获得词嵌入的向量,然后送入LSTM。假设从LSTM最后一个隐藏层获取到的特征为:
,它就代表了文本的特征。
对于SANs块:
这里为了方便计算我们只计算一层的注意力,且偏置b都不要了,然后先省略一个线性层,让⊕
假设初始化的
则 =
= =
然后计算 , 再计算
即可。最后再将u经过线性层映射到分类的维度即可(这里给各位同学一些施展空间,后面的几步具体计算可以自己私下算一算~)。
写在后面
本文到此也就结束了,不知道看完的同学有没有收获呢?如果这篇文章帮助到了你,请你点个赞再走吧~~~~
后续会更新的内容有:双线性池化(Bilinear Pooling)、紧凑双线性池化(Compact Bilinear Pooling)、双线性池化与双线性模型、低秩双线性池化(Low-rank Bilinear Pooling)(这个要敲重点,因为MLBP这篇论文我觉得和SANs很像)。

















 2988
2988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









