







一.模型

SAN其实主要分为3个部分:LSTM/CNN(用来提取输入的问题特征)、CNN(提取图像特征)、Attention(注意力层)。其中CNN部分其实不是集成在SAN网络中的,原文的实现方式其实是用已经预训练好了的VGG16来提取图片feature,然后直接调用这些feature,而不会去更新VGG16网络的权重。所以最终实际程序需要实现的部分其实就是LSTM/CNN部分和Attention部分。
二.模型精读
2.1Image Model
首先image应当在输入VGG16网络前被rescale成448x448大小,然后,为了保证原始图像的空间信息,输入图像后应当直接从最后一层pooling层拿到feature。最终我们得到的feature的形状应当是512×14×14,即把原始图像划分为196个区域,每个区域是512维的feature vector,每个区域对应原图片32×32大小的区域。

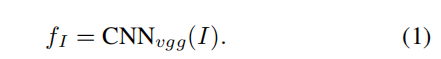

因为在后文attention部分中将会将这问题向量和图像向量加在一起,这里我们对feature进行处理:
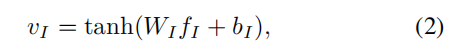
通过一个以tanh为激活函数的全连接层,最后得到的vector应当是与后面得到的问题的feature长度一致。
2.2Question Model
介绍两种方法来提取问题特征
2.2.1LSTM based on question model
先讨论使用lstm来提取问题特征
这里使用了Sequence to Sequence中的多对一形式,问题中每个单词按照时间顺序依次输入到lstm中,在最后时刻输出该问题的表达向量,如下图所示:

在每一步中,lstm单元接受一个输入的单词xt,并且更新记忆单元ct,然后输出隐藏层状态ht,更新过程使用了门机制,分别有输入门,遗忘门,输出门和记忆单元,简单来说就是选择性遗忘,选择性输入,选择性输出。详细的更新过程如下所示:

question q = [q1, ...qT ] ,qt 是t时刻输入单词的one hot vector表示,但是one-hot vector表示存在两个问题,(1)生成的向量维度往往很大,容易造成维数灾难;(2)难以刻画词与词之间的关系(如语义相似性,也就是无法很好地表达语义),所以通过一个嵌入矩阵将单词嵌入到向量空间。然后将词向量输入到lstm中。最后我们取最后一个隐藏层输出的ht 作为问题的feature。
意思就是将每一个词(用qt 表示)转换成对应的embedding向量,实现方法是使用嵌入矩阵乘以单词的one hot向量得到该词的词向量。
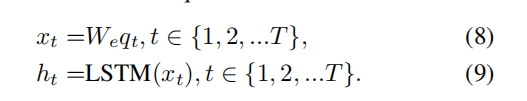
2.2.1CNN based on question model

将经过最大池化得到的向量连接起来得到的向量,即为问题向量。
3.Stacked Attention Networks
将图片和问题的feature线性变换下,然后再矩阵与向量求和(要用到框架内置的broadcasting机制),以此将文字信息和图片信息融合。最后通过对线性变换之后的图像-文本信息进行softmax来计算出图片与文字的相关性(或者说与问题相关的信息在图像的分布)。
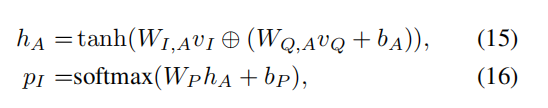
然后将pi和图像每个区域的feature相乘,就可以只保留与问题相关的信息。然后将信息叠加在一起(加权求和),最后和问题的feature相加,形成一个更加精化的查询向量,再经过一个softmax函数得到预测结果。
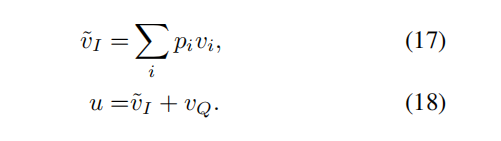
对于一些复杂的问题,一个注意力层是不够的,这时我们需要使用多个注意层迭代上述过程,每一次迭代都可以形成一个更加精确的视觉注意信息。
k代表第k个注意力层。u0被初始化为vQ
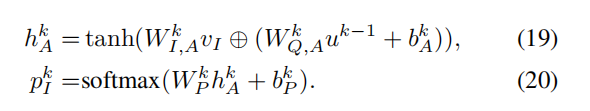
经过一个softmax函数得到预测结果:
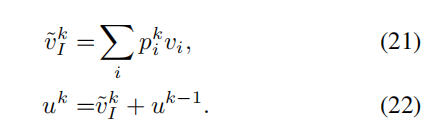
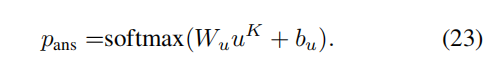
4.实验


代码分析
train.py
import os
import numpy as np
import shutil
import time
import json
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torchvision as tv
import nntools as nt
import torch
import torch.utils.data as data
from .models import *
from .preprocess import *
#三个路径
images_dir = '/datasets/ee285f-public/VQA2017/'
q_dir = '/datasets/ee285f-public/VQA2017/v2_OpenEnded_mscoco_'
ans_dir = '/datasets/ee285f-public/VQA2017/v2_mscoco_'
train_set = MSCOCODataset(images_dir, q_dir,
ans_dir, mode='train',
image_size=(224, 224))
def collate_fn(batch):
# function to sort each batch from largest question sequence to smallest (needed for LSTM)
batch.sort(key=lambda x : x[2], reverse=True)
return data.dataloader.default_collate(batch)
class SANExperiment():
def __init__(self, train_set, output_dir, batch_size=200, num_epochs=10, early_stopping=False):
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.train_set = train_set
self.early_stopping = early_stopping
torch.backends.cudnn.benchmark = False
self.indices = np.random.permutation(len(self.train_set))
self.indices = self.indices[:int(len(self.indices)*0.5)]
# train and validation splits 分训练集验证集
train_ind = self.indices[:int(len(self.indices)*0.8)]
val_ind = self.indices[int(len(self.indices)*0.8):]
train_sampler = torch.utils.data.sampler.SubsetRandomSampler(train_ind)
val_sam 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1713
1713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









