






深度学习技术
一、前馈全连接神经网络
1.导入常用工具包
1.1Numpy
Numpy是Python中用于科学计算的一个核心库。它提供了高性能的多维数组对象以及用于处理这些数组的函数。NumPy数组可以存储相同类型的数据,并且支持各种数学运算,非常适合于处理数值型数据。
1.2Pandas
Pandas是一个强大的数据分析库,它提供了用于数据操作和分析的数据结构和函数。它主要用于数据清洗、数据转换、数据分析等任务。Pandas最核心的数据结构是DataFrame,它类似于电子表格或SQL表,可以方便地处理结构化数据。
1.3Matplotlib
可以用于生成各种类型的图表,包括折线图、散点图、直方图等。Matplotlib可以与Pandas和NumPy一起使用,方便地将数据可视化展示出来,帮助你更好地理解数据和分析结果。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
2.数据导入与数据观察
2.1存储路径
定义一个变量,用于存储csv文件的路径
# 定义文件路径
path = r'E:\工坊\深度学习'
2.2读取文件
使用pandas的read_csv函数来读取位于path路径下的文件。os.path.join用于拼接文件路径,以确保跨平台兼容性。(header=None参数意味着CSV文件中没有标题行,因此pandas不会将第一行作为列名。)
# 读取CSV文件
train_Data = pd.read_csv(os.path.join(path, 'train.csv'), header=None)
test_Data = pd.read_csv(os.path.join(path, 'test.csv'), header=None)
2.3打印信息
使用info()方法打印出简要概述,包括每列的数据类型和缺失值情况。
# 打印训练集和测试集的信息
print("训练集信息:")
print(train_Data.info())
print("\n测试集信息:")
print(test_Data.info())
运行结果:

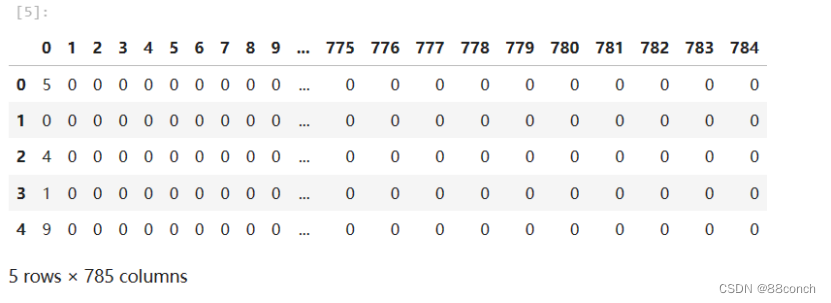
2.4返回前五行
train_Data.head(5)
运行结果:
2.5取出元素
2.5.1 取第一行数据
使用iloc属性从train_Data DataFrame中取出第一行数据,并将其存储在变量x中。iloc是基于行的索引,所以iloc[0]表示取第一行。
x = train_Data.iloc[0] # 取第一行数据
2.5.2 取第一个元素
从第一行数据x中取出第一个元素,这个元素通常是图像的标签(即图像代表的数字),并将其存储在变量y中。
y = x[0] # 标签信息
2.5.3 取从第二个元素到最后的所有元素
这行代码从第一行数据x中取出从第二个元素到最后的所有元素(即除去标签的所有像素值),使用values属性将其转换为一个NumPy数组,然后使用reshape方法将其从1x784的数组转换为28x28的数组,以匹配图像的原始尺寸。
img = x[1:].values.reshape(28,28) # 将1*784转换成28*28
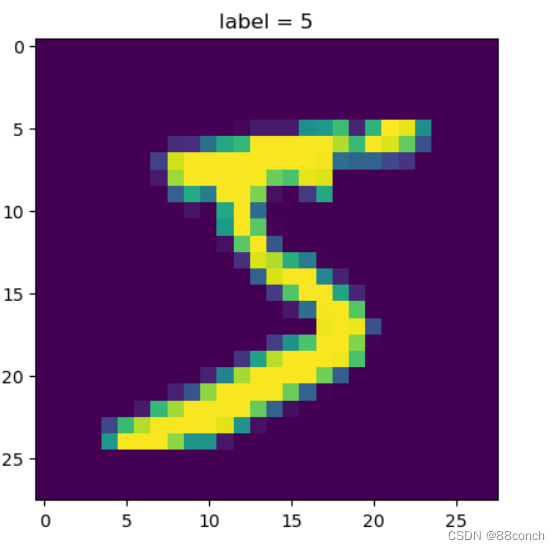
2.6显示图像
使用matplotlib.pyplot库中的imshow函数来显示图像。img是一个28x28的数组,imshow将其解释为灰度图像并显示出来。设置图像标题,并调用show函数确保显示图像。
plt.imshow(img) # 画图
plt.title('label = ' +str(y))
plt.show()
运行结果:
2.7观察数据
从sklearn.datasets模块中导入fetch_openml函数,并使用该函数来下载并加载MNIST数据集的一个变体。
# 从sklearn中导入数据
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784',version=1)
mnist.keys()
运行结果:

2.8打印维度
从mnist字典中提取了data和target键对应的值,并将它们分别赋值给变量data和label。然后,打印出这些数据的维度。
data, label = mnist["data"], mnist["target"]
print("数据维度: ", data.shape)
print("标签维度: ", label.shape)
运行结果:

2.9归一化
对数据集X进行了归一化处理,然后将归一化后的数据的最大值和最小值打印出来。
将数据集X中的每个值都除以255,是因为MNIST数据集中的像素值范围是从0到255(0代表黑色,255代表白色),这个操作将每个像素值缩放到0到1的范围内,从而实现了归一化。
由于归一化操作将所有值都缩放到0到1之间,因此预期输出的最大值应该是接近1的数(由于浮点数计算的精度问题,可能不会是精确的1),最小值应该是0。
# 归一化
X = X/255
# 此时将数值大小缩小在[0, 1]范围内,重新观察数据中的最大值、最小值
print("数据X中最大值: ", X.max())
print("数据X中最小值: ", X.min())
运行结果:

3.数据预处理
3.1分割数据集和标签集
分割数据集X和标签集y为训练集和验证集。
X_train和y_train:用于训练模型;
X_valid和y_valid:用于验证模型性能。
X_valid, X_train = X[:5000], X[5000:]
y_valid, y_train = y[:5000], y[5000:]
3.2读取测试数据集
3.2.1导入os、pandas库
os模块提供了与操作系统交互的功能,比如操作文件和目录。pandas是一个数据分析和操作库,用于处理结构化数据(类似于Excel表格)。
import os
import pandas as pd
3.2.2 存储文件路径
path = r'E:\工坊\深度学习'
3.2.3 读取文件
使用pandas的read_csv函数来读取位于path路径下的test.csv文件。os.path.join用于拼接文件路径,以确保跨平台兼容性。header=None参数意味着CSV文件中没有标题行,因此pandas不会将第一行作为列名。
# 读取CSV文件
test_Data = pd.read_csv(os.path.join(path, 'test.csv'), header=None)
3.2.4 分割特征数据和标签数据
分割test_Data DataFrame为特征数据X_test和标签数据y_test。iloc属性用于基于行列的位置索引。
X_test,y_test = test_Data.iloc[:,1:].values/255, test_Data.iloc[:,0].values
4.前馈全连接神经网络(Sequential模型)
4.1导入tensorflow、keras库
import tensorflow as tf
from tensorflow import keras
4.2构建一个神经网络模型
4.2.1创建了一个Keras的顺序模型(Sequential model)
顺序模型是Keras中最常见的模型类型,它允许我们一层一层地构建神经网络。
model = keras.models.Sequential([
4.2.2添加一个展平层(Flatten layer)
添加了一个展平层(Flatten layer)作为模型的第一层。展平层的作用是将输入的数据(例如,形状为[28, 28]的图像)展平成一个一维的向量,这里指定了输入形状为784,因为MNIST数据集中的图像是28x28像素的,展平后就是784个像素值。
keras.layers.Flatten(input_shape=[784]),
4.2.3添加一个全连接层(Dense layer)
添加了一个全连接层(Dense layer),它有300个神经元,并使用ReLU(Rectified Linear Unit)作为激活函数。全连接层意味着前一层中的每个神经元都连接到这一层的每个神经元。
keras.layers.Dense(300, activation="relu"),
4.2.4添加另一个全连接层
添加了另一个全连接层,它有100个神经元,同样使用ReLU激活函数。
keras.layers.Dense(100, activation="relu"),
4.2.5添加模型的最后一层
添加了模型的最后一层,也是一个全连接层,它有10个神经元,对应于10个类别的数字(0到9)。这一层使用softmax激活函数,它将输出转换为概率分布,每个神经元代表一个类别的概率。
keras.layers.Dense(10, activation="softmax")
])
4.2.6访问Keras模型中的第二层
model.layers[1]
运行结果:

4.2.7 获取其权重(weights)和偏置(bias)
从构建的Keras模型中的第二个层(第一个全连接层)获取其权重(weights)和偏置(bias)。
weights_1, bias_1 = model.layers[1].get_weights()
4.2.8打印从模型中获取的权重和偏置的形状
权重(weights)和偏置(biases)的形状取决于层的配置。对于全连接层(Dense layer),权重是一个二维数组,其中行数等于前一层的神经元数量,列数等于当前层的神经元数量。偏置是一个一维数组,长度等于当前层的神经元数量。
print(weights_1.shape)
print(bias_1.shape)
运行结果:
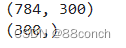
4.2.9打印出模型的摘要信息
model.summary()
运行结果:

4.3配置模型的训练过程
# 编译网络
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
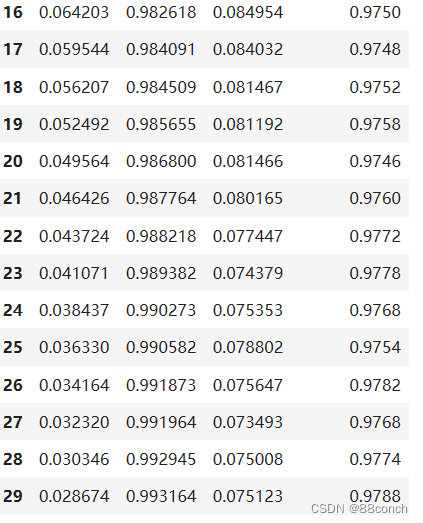
4.4训练网络
模型将开始训练过程,并使用验证数据来评估模型的性能。训练完成后,fit方法将返回一个包含训练历史信息的对象h,其中包含了训练过程中的重要信息,如损失值、准确率等。
# 定义文件路径
path = r'E:\工坊\深度学习'
# 读取CSV文件
train_Data = pd.read_csv(os.path.join(path, 'train.csv'), header=None)
X = train_Data.iloc[:, 1:].values
y = train_Data.iloc[:, 0].values
# 训练网络
h = model.fit(X_train, y_train, batch_size=32, epochs=30, validation_data=(X_valid, y_valid))
运行结果:


4.5输出一个表格
输出一个表格,其中包含了训练过程中的所有评估指标的值。
pd.DataFrame(h.history)
运行结果:
!](https://img-blog.csdnimg.cn/direct/b3a6444f8f9345d89babd6555cc5a442.png)

4.6绘制数据框(DataFrame)
4.6.1绘制图表
创建一个pandas DataFrame,调用DataFrame的plot方法来绘制图表。
pd.DataFrame(h.history).plot(figsize=(8, 5))
4.6.2添加网格线
使用matplotlib的plt接口来添加网格线到图表上,True参数表示启用网格线。
plt.grid(True)
4.6.3绘制坐标轴
获取当前坐标轴,设置y轴(垂直轴)的范围从0到1。
plt.gca().set_ylim(0, 1)
4.6.4显示图表
调用plt.show()之前,所有的绘图命令都是对图表的修改,但图表本身不会显示出来。plt.show()会触发图表的显示。
plt.show()
运行结果:
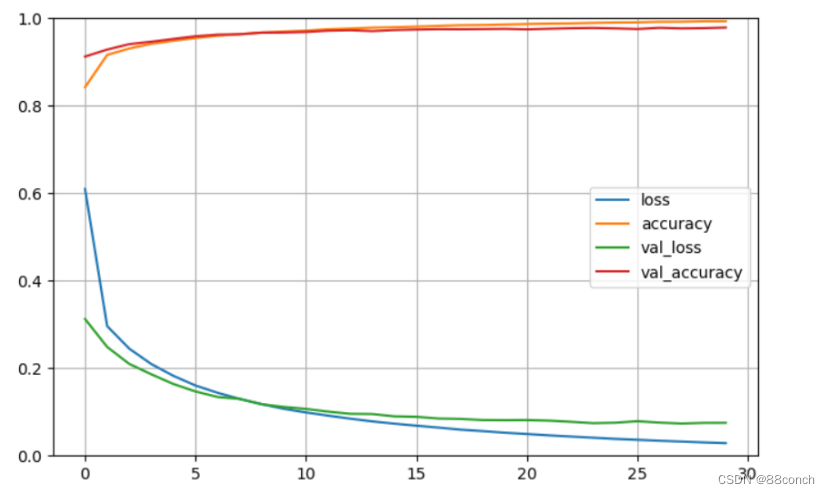
4.7评估模型性能
当调用evaluate方法时,模型会在测试数据集上运行,并计算损失和指标(如准确性)。
# 对测试集验证训练模型手写识别准确率
model.evaluate(X_test, y_test, batch_size=1)
运行结果:

4.8预测概率
从测试集中选择一个样本,使用训练好的模型来预测这个样本的类别概率,并将预测的概率四舍五入到小数点后两位。
x_sample, y_sample = X_test[11:12],y_test[11]
y_prob = model.predict(x_sample).round(2)
y_prob
运行结果:
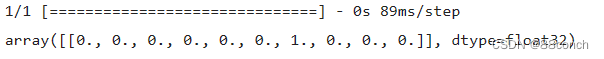
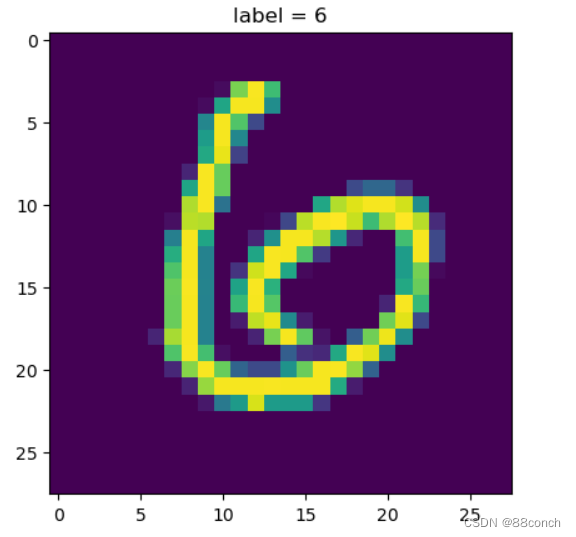
4.9显示模型预测的标签
4.9.1重塑二维数组
将x_sample的特征数据重塑为一个28x28的二维数组。这种形状通常与手写数字图像的像素尺寸相对应(例如,MNIST数据集中的图像)。
img = x_sample.reshape(28,28)
4.9.2显示图像
使用matplotlib的imshow函数来显示图像。img是一个28x28的数组,imshow将其解释为一个灰度图像并显示出来。
plt.imshow(img)# 画图
4.9.3设置图像标题
设置图像的标题,显示模型的预测标签。
plt.title('label = '+ str(np.argmax(y_prob)))
4.9.4显示图像和标题
plt.show()
运行结果:















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









