







前馈神经网络(Feedforward Neural Network, FNN)
◼ 第0层为输入层,最后一层为输出层,其他中间层称为隐藏层
◼ 信号从输入层向输出层单向传播,整个网络中无反馈,可用一个有向无环图表示

一、线性回归 Linear Regression
(一)《动手学深度学习》实例
线性回归的从零实现[源码]
# 线性回归的从零实现
import torch
import torch.nn as nn
import numpy as np
import random
from matplotlib import pyplot as plt
from IPython import display
# 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2,-3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype = torch.float32)
# 读取数据
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples)) # 创建一个整数列表
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
# 初始化模型参数
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
# 定义模型
def linearreg(X,w,b):
return torch.mm(X,w)+b # 矩阵乘法
# 定义损失函数 - 平方损失
def squared_loss(y_hat,y):
return (y_hat - y.view(y_hat.size()))**2/2 # 注意这里返回的是向量, 且pytorch里的MSELoss并没有除以 2
# 定义优化算法 - 小批量随机梯度下降算法
def SGD(params,lr,batch_size):
for param in params:
param.data -= lr*param.grad/batch_size # 注意这里更改param时用的param.data
# 训练模型
batch_size = 10
num_epochs = 50
lr = 0.003
net = linearreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X,w,b),y).sum()
l.backward()
SGD([w,b],lr,batch_size)
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch+1,train_l.mean().item()))
# 输出结果
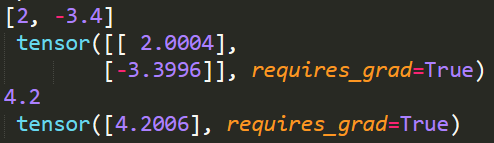
print(true_w, '\n', w)
print(true_b, '\n', b)
线性回归的从零实现[补充]
1. yield的使用
(yield相当于return一个值,并且记住这个返回的位置,下次迭代从这个位置后开始继续向下执行。)
参考:yield使用详解【非常容易理解!】
线性回归的简洁实现[源码]
# 线性回归的简洁实现
import torch
import torch.nn as nn
import numpy as np
import random
from matplotlib import pyplot as plt
from IPython import display
# 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2,-3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype = torch.float32)
# 读取数据
import torch.utils.data as Data
batch_size = 10
dataset = Data.TensorDataset(features,labels) # 将训练数据的特征和标签组合
data_iter = Data.DataLoader(dataset,batch_size,shuffle=True) # 随机读取小批量
# 定义模型(用class搭建模型)
class LinearNet(nn.Module):
def __init__(self,n_feature):
super(LinearNet,self).__init__()
self.linear = nn.Linear(n_feature,1)
def forward(self,x):
y = self.linear(x)
return y
net = LinearNet(num_inputs)
# 初始化模型参数
from torch.nn import init
init.normal_(net.linear.weight, mean=0, std=0.01)
init.constant_(net.linear.bias,val=0)
# 定义损失函数
loss = nn.MSELoss()
# 定义优化算法
import torch.optim as optim
optimizer = optim.SGD(net.parameters(),lr=0.003)
# 训练模型
num_epochs = 50
for epoch in range(1,num_epochs+1):
for X,y in data_iter:
output = net(X)
l = loss(output,y.view(-1,1))
optimizer.zero_grad()
l.backward()
optimizer.step()
print('epoch %d,loss: %f' % (epoch,l.item()))
# 结果输出
print(true_w, net.linear.weight)
print(true_b, net.linear.bias)

# 线性回归的简洁实现
import torch
import torch.nn as nn
import numpy as np
import random
from matplotlib import pyplot as plt
from IPython import display
# 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2,-3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype = torch.float32)
# 读取数据
import torch.utils.data as Data
batch_size = 10
dataset = Data.TensorDataset(features,labels) # 将训练数据的特征和标签组合
data_iter = Data.DataLoader(dataset,batch_size,shuffle=True) # 随机读取小批量
# 定义模型(用nn.Sequential搭建模型)
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# 此处还可以传入其他层
)
# 初始化模型参数
from torch.nn import init
init.normal_(net[0].weight, mean=0, std=0.01)
init.constant_(net[0].bias,val=0)
# 定义损失函数
loss = nn.MSELoss()
# 定义优化算法
import torch.optim as optim
optimizer = optim.SGD(net.parameters(),lr=0.003)
# 训练模型
num_epochs = 50
for epoch in range(1,num_epochs+1):
for X,y in data_iter:
output = net(X)
l = loss(output,y.view(-1,1))
optimizer.zero_grad()
l.backward()
optimizer.step()
print('epoch %d,loss: %f' % (epoch,l.item()))
# 结果输出
print(true_w, net[0].weight)
print(true_b, net[0].bias)
线性回归的简洁实现[补充]
1. 网络搭建的多种写法
1)继承nn.Module搭建模型:
# 继承nn.Module搭建模型
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__()
self.linear = nn.Linear(n_feature, 1)
# forward 定义前向传播
def forward(self, x):
y = self.linear(x)
return y
print(net)
print(net.linear.weight)
print(net.linear.bias)
注意:net.linear.weight和net.linear.bias
2)用nn.Sequential搭建模型:
# 用nn.Sequential搭建模型
# 写法一
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# 此处还可以传入其他层
)
# 写法二
net = nn.Sequential()
net.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module ......
# 写法三
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
('linear', nn.Linear(num_inputs, 1))
# ......
]))
print(net)
print(net[0])
只有当net是个ModuleList或者Sequential实例时才可以用根据下标访问子模块的写法net[0]
2. 关于学习率的设置
1)为不同子网络设置不同的学习率(在finetune时经常用到)
# 为不同的层设置不同的学习率
optimizer =optim.SGD([
# 如果对某个参数不指定学习率,就使用最外层的默认学习率
{'params': net.subnet1.parameters()}, # lr=0.03
{'params': net.subnet2.parameters(), 'lr': 0.01}
], lr=0.03)
2)不固定学习率
① 修改optimizer.param_groups中对应的学习率:
# 调整学习率
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1 # 学习率为之前的0.1倍
②新建优化器:
由于optimizer十分轻量级,构建开销很小,故而可以构建新的optimizer。但是对于使用动量的优化器(如Adam),会丢失动量等状态信息,可能会造成损失函数的收敛出现震荡等情况。
(二)《PyTorch深度学习实践》实例
用PyTorch实现线性回归[源码]
import torch
# Prepare dataset
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
# Design Model
class LinearModel(torch.nn.Module):
def __init__(self):#构造函数
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# Construct Loss & Optimizer
criterion = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
# Training Cycle
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Test Model
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
用PyTorch实现线性回归[补充]
1. 梯度下降
2. 反向传播
3. 线性回归
二、逻辑回归 Logistic Regression
《PyTorch深度学习实践》逻辑回归实例
三、softmax回归
(一)《动手学深度学习》实例
softmax的实现[源码]
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
from IPython import display
import sys
from torch import nn
from torch.nn import init
# 调用数据集
mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=False, download=True, transform=transforms.ToTensor())
# 将数值标签转成相应的文本标签
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','ankle root']
return [text_labels[int(i)] for i in labels]
# 在一行里可以画出多张图像和对应标签
def show_fashion_mnist(images,labels):
display.set_matplotlib_formats('svg') # 用矢量图显示use_svg_display
_,figs = plt.subplots(1,len(images),figsize=(12,12)) # _表示我们忽略(不使用的变量)
for f,img,lbl in zip(figs,images,labels):
f.imshow(img.view((28,28)).numpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
# 读取小批量数据
batch_size = 256
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4 # 设置4个进程读取数据
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) # DataLoader允许使用多进程来加速数据读取
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
# 定义和初始化模型
num_inputs = 784
num_outputs = 10
class LinearNet(nn.Module):
def __init__(self,num_inputs,num_outputs):
super(LinearNet,self).__init__()
self.linear = nn.Linear(num_inputs,num_outputs)
def forward(self,x):
y = self.linear(x.view(x.shape[0],-1))
return y
net = LinearNet(num_inputs,num_outputs)
init.normal_(net.linear.weight, mean=0, std=0.01)
init.constant_(net.linear.bias, val=0)
# 定义损失函数
loss = nn.CrossEntropyLoss()
# 定义优化算法
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
# 定义准确率
def evaluate_accuracy(data_iter,net):
acc_sum,n = 0.0,0
for X,y in data_iter:
acc_sum += (net(X).argmax(dim=1)==y).float().sum().item()
# net(X).argmax(dim=1)返回矩阵net(X)即y_hat每行中最大元素的索引,且返回结果与变量y形状相同。相等条件判断式net(X).argmax(dim=1) == y)是一个类型为ByteTensor的Tensor,我们用float()将其转换为值为0(相等为假)或1(相等为真)的浮点型Tensor。
n+=y.shape[0]
return acc_sum/n
# 训练模型
num_epochs = 5
lr = 0.1
def train(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):
for epoch in range(num_epochs):
train_l_sum,train_acc_sum,n = 0.0,0.0,0
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat,y).sum()
# 梯度清零、反向传播、参数更新
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1)==y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter,net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f' % (epoch+1,train_l_sum/n,train_acc_sum/n,test_acc))
train(net,train_iter,test_iter,loss,num_epochs,batch_size,None,None,optimizer)
# 预测
X, y = iter(test_iter).next()
true_labels = get_fashion_mnist_labels(y.numpy())
pred_labels = get_fashion_mnist_labels(net(X).argmax(dim=1).numpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)]
show_fashion_mnist(X[0:9], titles[0:9])
。
softmax的实现[补充]
1. torchvision包
torchvision包是服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。torchvision主要由以下几部分构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
2. Fashion-MNIST数据集的使用
Fashion-MNIST中一共包括了10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
from IPython import display
import sys
# 调用数据集
mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=False, download=True, transform=transforms.ToTensor())
print(type(mnist_train)) # 获取数据集的类型
print(len(mnist_train),len(mnist_test)) # 获取数据集的大小
feature,label = mnist_train[0]
print(feature.shape,label) # 通过下标访问任意样本
# 将数值标签转成相应的文本标签
def get_fashion_mnist_labels(labels):
text_labels = ['t-shirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','ankle root']
return [text_labels[int(i)] for i in labels]
# 在一行里可以画出多张图像和对应标签
def show_fashion_mnist(images,labels):
display.set_matplotlib_formats('svg') # 用矢量图显示use_svg_display
_,figs = plt.subplots(1,len(images),figsize=(12,12)) # _表示我们忽略(不使用的变量)
for f,img,lbl in zip(figs,images,labels):
f.imshow(img.view((28,28)).numpy())
f.set_title(lbl)
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
plt.show()
# 查看训练数据集前十个样本的图像内容和文本标签
X,y = [],[]
for i in range(10):
X.append(mnist_train[i][0])
y.append(mnist_train[i][1])
show_fashion_mnist(X,get_fashion_mnist_labels(y))
# 读取小批量数据
batch_size = 256
if sys.platform.startswith('win'):
num_workers = 0 # 0表示不用额外的进程来加速读取数据
else:
num_workers = 4 # 设置4个进程读取数据
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) # DataLoader允许使用多进程来加速数据读取
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
# 查看读取一遍训练数据需要的时间
start = time.time()
for X,y in train_iter:
continue
print('%.2f sec' % (time.time() - start))


3. transform = transforms.ToTensor()
指定参数transform = transforms.ToTensor()使所有数据转换为Tensor,如果不进行转换则返回的是PIL图片。transforms.ToTensor()将尺寸为 (H x W x C) 且数据位于[0, 255]的PIL图片或者数据类型为np.uint8的NumPy数组转换为尺寸为(C x H x W)且数据类型为torch.float32且位于[0.0, 1.0]的Tensor。
如果用像素值(0-255整数)表示图片数据,那么一律将其类型设置成uint8,避免不必要的bug。
4. 多层感知机
多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。多层感知机的层数和各隐藏层中隐藏单元个数都是超参数。
《PyTorch深度学习实践》中已经涉及到给神经网络加隐藏层了,这里只举个《动手学深度学习》中的例子,和上面的例子唯一的区别就是加了隐藏层,此外也没有其他要点了。
附一个代码片段:
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
# 用view()将x的形状转换成(batch_size,784)在送入全连接层
net = nn.Sequential(
FlattenLayer(),
nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.Linear(num_hiddens, num_outputs),
)
for params in net.parameters():
init.normal_(params, mean=0, std=0.01)
(二)《PyTorch深度学习实践》实例
softmax回归[源码]
# Import Package
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# Prepare Dataset
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), # Convert the PIL Image to Tensor
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='./dataset/mnist/',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/',train=False,download=True,transform=transform)
test_loader = DataLoader(train_dataset,shuffle=False,batch_size=batch_size)
# Design Model
class Net(torch.nn.Module):
"""docstring for Net"""
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784,512)
self.l2 = torch.nn.Linear(512,256)
self.l3 = torch.nn.Linear(256,128)
self.l4 = torch.nn.Linear(128,64)
self.l5 = torch.nn.Linear(64,10)
# 全连接神经网络
def forward(self,x):
x = x.view(-1,784) # 需要将图像展平处理
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不需要激活
model = Net()
# Construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
# Train and Test
def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' % (epoch+1,batch_idx+1,running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images,labels = data
outputs = model(images)
_,predicted = torch.max(outputs.data,dim=1)
total += labels.size(0)
correct += (predicted==labels).sum().item()
print('Accuracy on test set: %d %%' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()















 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









