






 到目前为止,我们只处理了具有一种边类型的图
到目前为止,我们只处理了具有一种边类型的图
如何处理具有多种节点或边类型的图(也称为异构图)?
目标:在异构图上学习
▪ 关系图卷积网络(Relational GCNs)
▪ 异构图变换器(Heterogeneous Graph Transformer)
▪ 异构图神经网络的设计空间
1. 异构图(Heterogeneous Graphs)
异构图被定义为
- 具有节点类型
- 节点 v 的节点类型为
- 具有边类型
- 边 的边类型为
- 边 的关系类型为一个元组:
还有其他异构图的定义方式 - 描述带有节点和边类型的图。
观察:我们也可以将节点和边的类型视为特征(注意是类型视为特征)
▪ 例如:为节点和边添加一个独热指示符
▪ 为每个“作者节点”附加特征 [1, 0];为每个“论文节点”附加特征 [0, 1](concat)
▪ 类似地,我们可以为具有不同类型的边分配边特征
▪ 然后,异构图会减少为标准图
什么时候需要异构图?
▪ 情况1:不同的节点/边类型具有不同形状的特征
▪ “作者节点”有4维特征,而“论文节点”有5维特征
▪ 情况2:我们知道不同的关系类型表示不同类型的互动
▪ (英语,翻译,法语) 和 (英语,翻译,中文) 需要不同的模型
最终,异构图是一种更具表现力的图表示
▪ 捕捉了实体之间不同类型的互动
但也伴随着成本
▪ 更昂贵(计算、存储)
▪ 更复杂的实现
有许多方法可以将异构图转换为标准图(即,同质图)。
2. Relational GCN
我们将扩展GCN以处理具有多种边缘/关系类型的异构图
我们从具有一个关系的有向图开始
▪ 在这个图上,我们如何运行GCN并更新目标节点A的表示?仅沿边的方向传递消息 C。
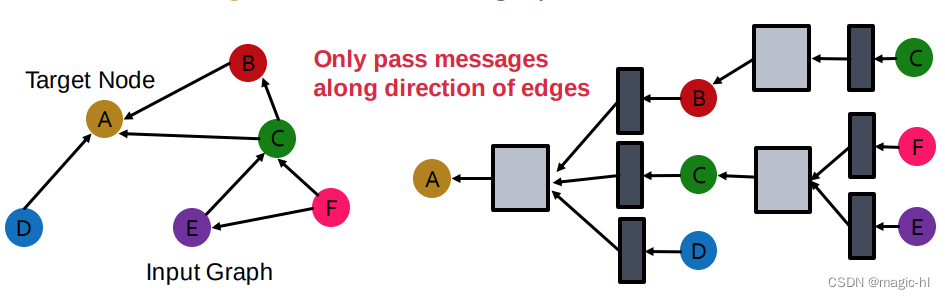
如果图具有多个关系类型,情况会怎样?
对不同的关系类型使用不同的神经网络权重。
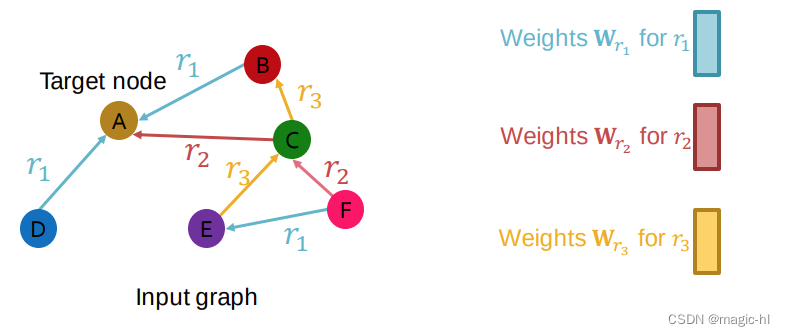
Relational GCN (RGCN):
如何将此表示为消息 + 聚合?
消息:
▪ 给定关系的每个邻居:
▪ 自环:
聚合:
▪ 对来自邻居和自环的消息进行求和,然后应用激活函数。
为每种关系类型引入一组神经网络! 每个关系具有 𝐿 个矩阵:𝐖𝑟₁,𝐖𝑟₂,⋯,𝐖𝑟𝐿
每个 𝐖𝑟ₗ 的尺寸为 𝑑(𝑙+1) × 𝑑(𝑙)
随着关系数量的快速增长,参数数量迅速增多!
▪ 过拟合成为一个问题
有两种方法来对权重 𝐖𝒓(𝒍) 进行正则化
(1) 使用分块对角矩阵
核心思想:使权重稀疏!
对 𝐖 运用分块对角矩阵。
局限性:只有相邻的神经元/维度能够通过连接相互作用。
如果使用 𝐵 个低维矩阵,则参数数量从减少到
。
(2) 基/字典学习
核心洞见:在不同关系之间共享权重!
将每个关系的矩阵表示为基变换的线性组合,其中 𝐕𝑏 在所有关系之间共享
▪ 𝐕𝑏 是基础矩阵
▪ 𝑎𝑟𝑏 是矩阵 𝐕𝑏 的重要性权重
现在每个关系只需要学习,这是 𝐵 个标量。
目标:预测给定节点的标签
RGCN 使用最终层的表示:
▪ 如果我们从 𝑘 个类别中预测节点 𝐴 的类别
▪ 取最终层(预测头):,
中的每个项目表示该类别的概率。
链接预测分割:
每条边还具有一个关系类型,这与这4个类别是独立的。在异构图中,由每个单独关系形成的同质图也具有这4种分割。
假设 是训练监督边,所有其他边都是训练消息边。
使用 RGCN 对 进行打分!
▪ 取 𝐸 和 𝐴 的最终层:和
∈
▪ 关系特定的分数函数 : ℝ^𝑑 × ℝ^𝑑 → ℝ
▪ 一个示例 𝑓ᵣ₁(𝐡𝐸, 𝐡𝐴) = 𝐡𝐸ᵀ𝑊ᵣ₁𝐡𝐴,其中 𝑊ᵣ₁ ∈ ℝ^(𝑑×𝑑)

训练:
1. 使用RGCN对训练监督边进行评分。
2. 通过扰动监督边来创建负边。
• 扰动尾部
• 例如,,
3. 使用GNN模型对负边进行评分。
4. 优化标准的交叉熵损失(如第6讲所讨论的)。
1. 最大化训练监督边的得分。
2. 最小化负边的得分。
训练监督边:
训练消息边:其余所有现有边(实线)
(1)使用训练消息边来预测训练监督边。
请注意,负边不应属于训练消息边或训练监督边!
例如,不是负边。
评估:

▪ 以验证时间为例,测试时间也相同
(2)在验证时:
使用训练消息边和训练监督边来预测验证边。
评估模型如何能够预测带有关系类型的验证边?
我们来预测验证边
直觉: 的得分应该高于所有不在训练消息边和训练监督边中的
,例如
验证边:
训练消息边和训练监督边:所有现有的边(实线)
1. 计算的得分
2. 计算所有负边的得分: 𝒗 ∈ 𝑩,𝑭,因为
,
属于训练消息边和训练监督边
3. 得到 的排名 𝑹𝑲
4. 计算指标
1. Hits@𝒌:𝟏 [𝑹𝑲 ≤ 𝒌]。值越高越好
2. Reciprocal Rank:。值越高越好
基准数据集
▪ 来自微软学术图(MAG)的 ogbn-mag 数据集
四种(4种)实体类型
▪ 论文:736k 个节点
▪ 作者:1.1m 个节点
▪ 机构:9k 个节点
▪ 研究领域:60k 个节点
四种(4种)有向关系
▪ 一个作者与一个机构 "隶属于" 关系
▪ 一个作者 "写作" 一篇论文
▪ 一篇论文 "引用" 一篇论文
▪ 一篇论文 "属于主题" 一个研究领域
预测任务
▪ 每篇论文都有一个128维的word2vec特征向量
▪ 鉴于来自ogbn-mag的内容、引用、作者和作者隶属关系,预测每篇论文的会议(venue)
▪ 由于考虑了349个会议,因此是一个349类分类问题
基于时间的数据集划分
▪ 训练集:2018年之前发布的论文
▪ 测试集:2018年之后发布的论文
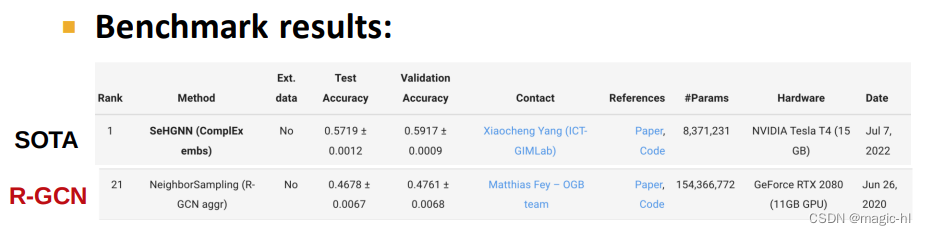
▪ SOTA 方法:SeHGNN
`▪ ComplEx(下一讲) + 简化的 GCN(第17讲)
总结:
关系图卷积网络(Relational GCN),用于异构图的图神经网络
可以执行实体分类以及链接预测任务。
这些思想也可以轻松扩展到关系图神经网络(RGNN,如 RGraphSAGE、RGAT 等)。
基准测试:使用来自 Microsoft 学术图谱的 ogbn-mag 数据集,预测论文的发表地点。
3. Heterogeneous Graph Transformer
图注意网络(Graph Attention Networks,简称GAT)
并非所有节点的邻居都同等重要!
▪ 注意力灵感来自认知注意力。
▪ 注意力 𝜶ᵥᵤ 关注输入数据的重要部分,并逐渐淡化其余部分。
▪ 思想:神经网络应该在数据的那个小但重要的部分投入更多计算资源。
我们能否将 GAT 适用于异构图?
动机:GAT 无法表示不同的节点和不同的边类型
为每种关系类型引入一组神经网络对于注意力来说太昂贵
▪ 回顾:关系描述为(起始节点,边,结束节点)
HGT 使用缩放点积注意力(在 Transformer 中提出)
查询(Query):𝑄,键(Key):𝐾,值(Value):𝑉
▪ 𝑄,𝐾,𝑉 的形状为(batch_size,dim)
我们如何获得 𝑄,𝐾,𝑉?
对输入应用线性层
▪ 𝑄 = 𝑄_𝐿𝑖𝑛𝑒𝑎𝑟(𝑋)
▪ 𝐾 = 𝐾_𝐿𝑖𝑛𝑒𝑎𝑟(𝑋)
▪𝑉 = 𝑉_𝐿𝑖𝑛𝑒𝑎𝑟(𝑋)
回顾:将 GAT 应用于同质图
▪ 表示第 𝑙 层的表示:
如何将关系类型(起始节点、边、结束节点)纳入注意力计算?
创新:将异构注意力分解为节点类型和边类型相关的注意力机制
▪ 3 个节点权重矩阵,2 个边权重矩阵
▪ 不进行分解:3*2*3=18 种关系类型 -> 18 个权重矩阵(假设存在所有关系类型)
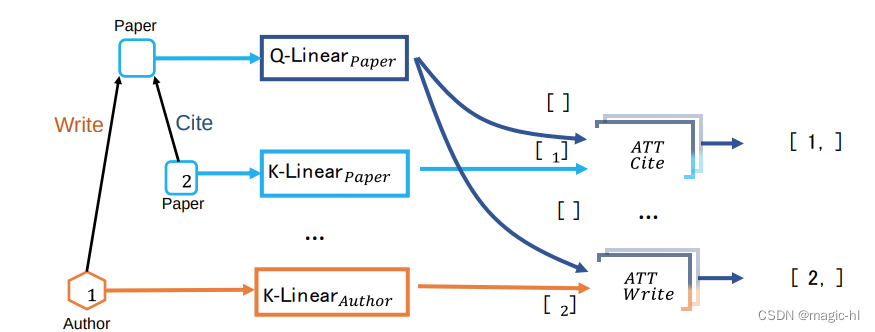
异质相互注意(Heterogeneous Mutual Attention):
每个关系(𝑇 𝑠,𝑅 𝑒,𝑇 𝑡)都有一组不同的投影权重。
▪ 𝑇 (𝑠):节点 𝑠 的类型,𝑅 𝑒:边 𝑒 的类型
▪ 𝑇(𝑠) 和 𝑇(𝑡) 对 𝐾_𝐿𝑖𝑛𝑒𝑎𝑟𝑇 𝑠 和 𝑄_𝐿𝑖𝑛𝑒𝑎𝑟𝑇 𝑡 进行参数化,其中进一步返回键(Key)和查询(Query)向量 𝐾(𝑠) 和 𝑄(𝑡)
▪ 边类型 𝑅(𝑒) 直接参数化 。
完整的 HGT 层
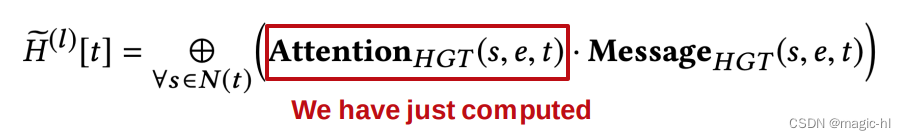
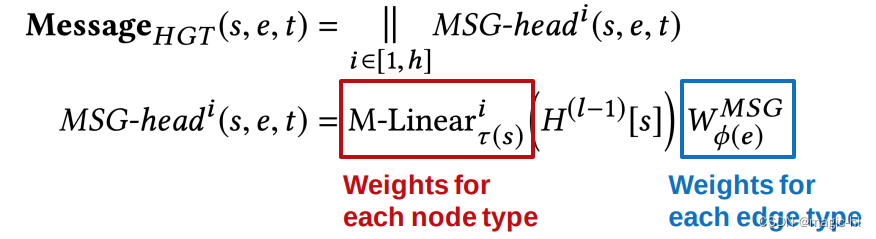
类似地,HGT 在消息计算中使用节点和边类型来分解权重。
基准:来自微软学术图的 ogbn-mag 数据集,用于预测论文的会议(venue)

HGT 使用的参数要少得多,尽管注意力计算很昂贵,但表现优于 R-GCN
▪ 这要归功于对节点和边类型进行的权重分解。
4. 异质图神经网络设计空间(Design Space of Heterogeneous GNNs)
图特征处理
▪ 两种常见选择:在每种关系类型内计算图统计量(例如节点度),或在整个图上计算(忽略关系类型)
图结构处理
▪ 对异构图,邻居和子图采样也很常见。
▪ 两种常见选择:在每种关系类型内进行采样(确保覆盖每种类型的邻居),或在整个图上进行采样。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









