






每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

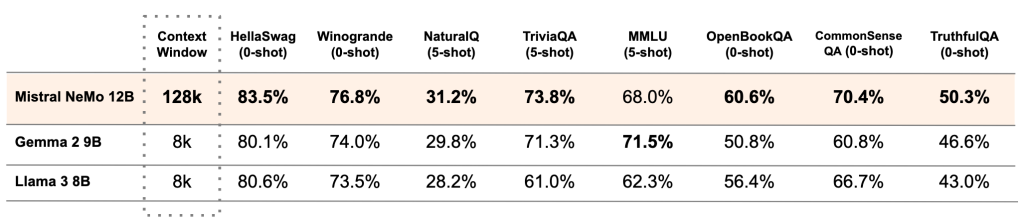
今天,Mistral NeMo正式发布,这是一个与NVIDIA合作打造的12B模型。Mistral NeMo拥有高达128k标记的大型上下文窗口,其推理能力、世界知识和编程准确性在同类规模中达到了最先进的水平。由于采用标准架构,Mistral NeMo使用起来非常方便,可以无缝替换任何使用Mistral 7B的系统。为了促进研究人员和企业的采用,预训练的基础模型和指令调优检查点都在Apache 2.0许可证下发布。Mistral NeMo通过量化感知训练,实现了在FP8推理下无性能损失。下表比较了Mistral NeMo基础模型与最近两个开源预训练模型Gemma 2 9B和Llama 3 8B的准确性
多语言模型的普及
Mistral NeMo专为全球多语言应用而设计。它经过功能调用训练,具有大上下文窗口,在英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语等语言上表现特别强劲。这是让前沿AI模型普及到每个人手中的重要一步,涵盖了人类文化的各种语言。
Mistral NeMo在多语言基准上的表现
图1:Mistral NeMo在多语言基准上的表现。

更高效的分词器——Tekken
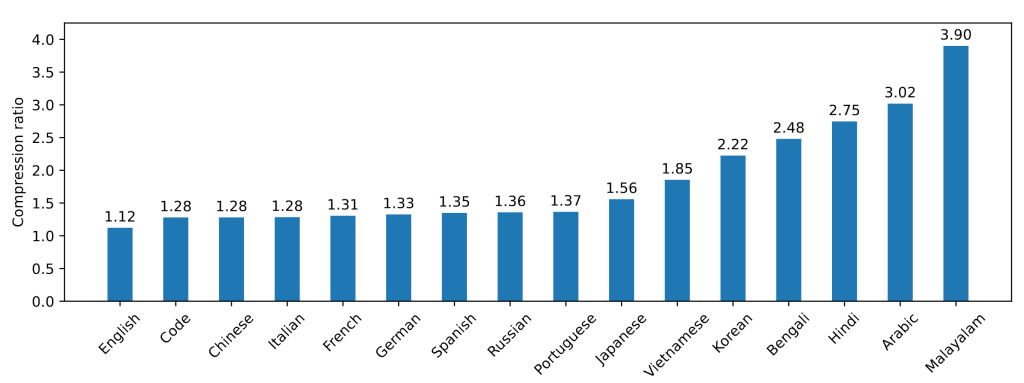
Mistral NeMo使用了新的分词器Tekken,基于Tiktoken训练,覆盖100多种语言,比之前的Mistral模型使用的SentencePiece分词器更有效地压缩自然语言文本和源代码。特别是在压缩源代码、中文、意大利语、法语、德语、西班牙语和俄语方面,其效率提升了约30%;在压缩韩语和阿拉伯语方面,其效率分别提升了2倍和3倍。与Llama 3的分词器相比,Tekken在约85%的语言中表现更佳。
Tekken压缩率
图2:Tekken压缩率。
指令微调
Mistral NeMo经历了高级微调和对齐阶段。与Mistral 7B相比,它在遵循精确指令、推理、处理多轮对话和生成代码方面表现更佳。
Mistral NeMo指令调优模型的准确性
表2:Mistral NeMo指令调优模型的准确性。评估由GPT4o在官方参考资料上进行。

链接
基础模型 (https://huggingface.co/mistralai/Mistral-Nemo-Base-2407)和指令模型(https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407)的权重托管在HuggingFace。现在可以通过mistral-inference试用Mistral NeMo,并通过mistral-finetune进行适配。Mistral NeMo在la Plateforme上以open-mistral-nemo-2407的名称展示,还作为NVIDIA NIM推理微服务打包在容器中,可在ai.nvidia.com获取。















 5305
5305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









