






前言
详见前文
目录
函数
函数定义与使用
函数的定义与使用
除了python自带的函数,需要定义,然后再调用(和C语言一样)
定义:
def 函数名(函数的参数列表):
函数体
调用:
返回值=函数名(输入的参数)
return返回机制和C语言一样
例子:阶乘求和函数gtr
def gtr(x):
total=0
for j in range(x):
count=0
for i in range(j+1):
count=count+i+1
total=total+count
return total
print(gtr(int(input())))传参机制
和C一样,也有实参和形参,也分为传递值和传递“地址”(叫引用传递)
值传递:参数为不可变类型:字符串,数字,元组
引用传递:反之,参数可变:列表,字典
参数列表
可以有几种用法:(和format格式化输出的大括号{}用法类似)
位置参数:
默认形参和实参数量相同时,顺序一一对应
关键字参数:
和{}一样,但是不建议和位置参数一起用,否则只能位置参数填完前面的后后面才能用关键字参数
eg:f(1,2,c=3)才行,f(c=3,1,2)不行
默认参数:
当定义时可以给形参一个默认值,但是默认参数必须放在最后;调用时可以用或者不用默认值
eg:def f(a,b,c=1)
f(1,2,3)不用c=1
f(1,2)用c=1
不定长参数:
在形参前加*,可按位置参数的样子传入多个参数,用元组接收
在形参前加**,可按关键字参数的样子传入多个参数,用字典接收(关键字是key,关键字对应的值是value)
变量作用域
作用域分局部和全局(和C一样)
如何不用return的前提下在函数内修改全局变量:
使用global声明:global+变量名
math
常量类

常用函数
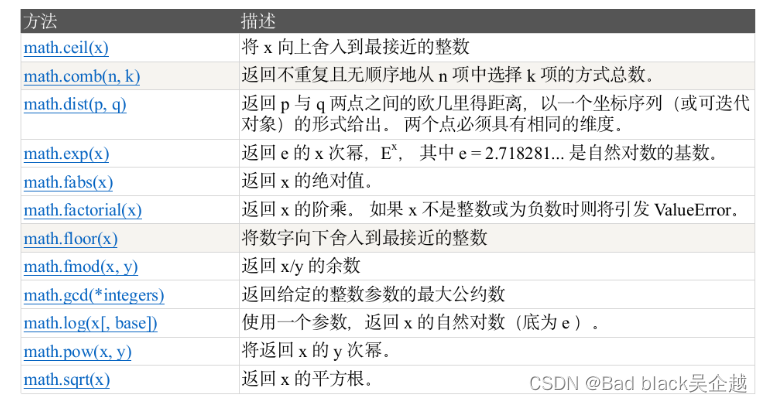
注意:gcd()括号里面可以填多个数
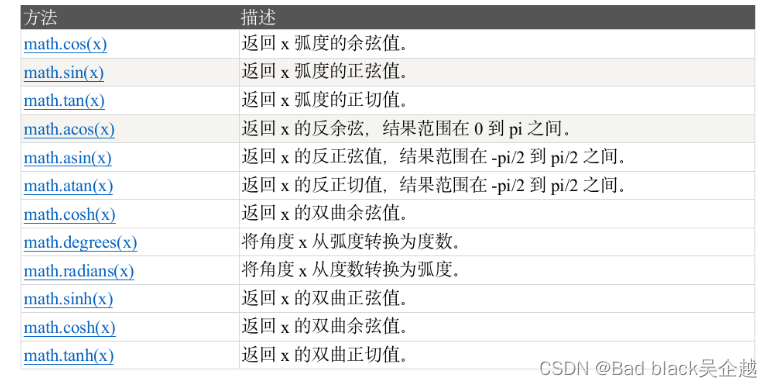
三角函数
collections包
都需要from collections import xxx
counter:计数器
用于计数的dict
定义:
Counter(可迭代对象)(value用于计数)或者Counter(字典)(由于字典本身键值对一一对应,故此时不做计数器,计数位置放value)(大写C)
注意:可迭代对象可以是字符串,counter统计各字符数量
eg:a=Counter([1,2,1,3,1])这里放的是列表
常用函数:
a.most_common(k):筛选频率前k名(同名次从左往右取),返回一个以元组为元素的列表
a.element():返回一个迭代器,每个元素重复对应次数(迭代器还没讲到)
list(element())可以返回一个列表,每个元素重复对应次数(字典Counter需要value是数字)
from collections import Counter
a=Counter(dict([('a',1),('b',2)]))
print(a)
print(list(a.elements()))a.clear():清空
大部分字典的功能Counter也能用(本质上就是一个dict)
计数器可以数学运算:加减,&取每个Counter都有的(交集),|取各个最大的(并集)
deque:双端队列
名字也可以看成,是加强版的list队列
好处是在处理首尾的元素时,有快捷方式,时间复杂度降低
大部分功能和list相同,删除和插入方式更高效


新增了左端操作left系列:appendleft(),popleft(),extendleft()
新增了rotate(),maxlen
注意:maxlen一般在定义时设置
eg:a=deque([1,2],maxlen=3)
defaultdict:有默认值的字典
(这部分有点抽象,等笔者学了后面的可能会写的更好)
由普通的字典
访问字典
通过key得到value,把key看作下标
知道key一定存在时
a[key]返回的是对应的value
key不一定存在时
a.get(key[,x])查key查到返回value查不到默认返回None(可修改为x)
如果访问时没有用get没有设置x
不妨用defaultdict
eg:
from collections import defaultdict
d=defaultdict(int)
d['a']='c'
print(d)
print(type(d))
print(d['x'])关键是一开始的定义:d=defaultdict(int)建的是一个只有默认值的空列表
就像a=dict()
但是括号里需要放“可调用的类型callable”(暂时没学到),一般放int,list,set,dict
然后再添加字典的元素
如果没搜到就会返回相应的"callable"的空值
那么,如何创建好后快速添加字典的元素
from collections import defaultdict
s=[('key1','value1'),('blue',2)]
d=defaultdict(list)
for k,v in s:
d[k].append(v)
print(d)
print(d['x'])用list(不能用int)这样就可以使字典s变成默认值字典d
OrderedDict:有序字典
与字典基本相同,很少用
key按照插入的顺序排序(3.7版本以后的字典也是,所以少用)
popitem()函数:
3.7版本 以上默认删除最后一个键值对然后返回
有序字典可以指定参数last,last默认为最后一个,否则删除第一个(字典不可以)
from collections import OrderedDict
a=[('key1','value1'),('key2','value2'),('key3','value3')]
b=OrderedDict(a)
while len(b) != 0:
print(b.popitem(False))
print(b)move_to_end(key[,last=True])函数:
将key默认移动到最右端,Flase则为左端,key不存在则报错
from collections import OrderedDict
a=[('key1','value1'),('key2','value2'),('key3','value3')]
b=OrderedDict(a)
print(b)
b.move_to_end('key1')
print(b)
b.move_to_end('key3',False)
print(b)heapq
就是堆的英语(heap)加了个q
堆:完全二叉树,每个节点小于等于子节点数(默认为最小堆)(?)
每个节点k都有两个子节点2k+1,2k+2

用list表示一个堆:
将无序list(eg:a)转换成最小堆:heap+ify动词词根
heapq.heapify(a)
最小堆a中添加元素x:push添加
heapq.heappush(a,x)
删除并返回最小的元素:pop
heapq.heappop(a)
删除并返回最小的元素,同时添加元素x:replace代替
heapq.heapreplace(a,x)
但是笔者目前还没有想好怎么print出来堆的结构
functool
全名function+tool即函数工具,应用在高阶函数,即参数、返回值为其他函数的函数
这里只说偏函数(?):partial
用于固定某些函数的参数或者关键字参数,然后返回一个函数
functools.partial(func,*args,**keywords)

关于*args和**kwargs(就是带keyword kw 字典的args)(arg应该是argument参数的缩写),详见http://t.csdnimg.cn/PDUk9
举个例子:
from functools import partial
def Add(a,b,c):
print(a)
print(b)
print(c)
Add(1,2,3)
add_c=partial(Add,c=10)
add_c(1,2)from functools import partial
def add(*args,**kwargs):
for n in args:
print(n)#打印args
for k,v in kwargs.items():
print(k,v)#打印kwargs
add(1,2,3,v1=10,v2=20)#普通调用
add2=partial(add,4,k1=5)#partial
add2()#有已经固定的就可以直接调用
add2(6,v3=30)#也可以再补相比之前的固定参数,不同是可以固定不限个数的参数
itertools
用来创建迭代器的模块
(关于迭代器:迭代器是访问集合的一种方式,可以记住遍历位置的对象,迭代器从集合的第一个元素开始访问,直到所有的元素被访问完才结束,只能往往前,不能后退。详见http://t.csdnimg.cn/8ctgC)
分为无限迭代器,有限迭代器,排列组合迭代器
无限迭代器
创建长度为无限的迭代器
count(start=x,step=y):返回间隔均匀的值
cycle(可迭代对象):循环遍历可迭代对象所有元素
repeat(object[,times]):遍历times次object
有限迭代器
accumulate累计
itertools.accumulate(iterable可迭代对象[,function]):默认不写func返回可迭代对象的累加值,function可以是各种双目运算,最后返回一个累积结果值
eg:

max是取最大值,operator.mul应该是累乘(operator第一次出现)
itertools.chain(*iterable多个可迭代对象):合并多个迭代器(*一般指多个,不限个数的参数)
eg:
import itertools
a=[1,2,3]
b=[4,5]
c=itertools.chain(a,b)
for i in c:
print(i)
print(type(c))排列组合迭代器
用于排列组合
itertools.product(不限量可迭代对象[,repeat=x]):
可迭代对象的笛卡尔积(即各个可迭代对象挑一个元素的全排列)
repeat是重复次数,默认为1,若多次则迭代器多次迭代
注意:只有product是可以对不限量个可迭代对象操作的,下面两个不行
import itertools
a=[1,2,3]
b=[4,5]
c=itertools.product(a,b)
d=itertools.product(a,b,repeat=2)
for i in c:
print(i)
print(type(c))
c=itertools.product(a,b,a)
for i in c:
print(i)itertools.permutations(可迭代对象[,r=x]): (permutations中文是排列
由可迭代序列生成长度为x的排列,r默认为可迭代对象的长度
即元素的全排列(或A右上标x右下标是len(可迭代对象))
itertools.combinations(可迭代对象,r);(combinations中文是组合
同理排列,但是r必须写
即高中数学的组合,一个道理
类的定义和使用
类的定义和使用
这部分比较抽象
类和对象
(面向对象:模拟真实世界的事物)
类:类型,自定义各种类型用于具体情境(C的结构体升级版,可以放函数)
对象:就是变量,类的实例化(实例化就是调用类),用类创建的具体对象(某个特定个体)(实例)
class 类名:
多个类属性
多个类方法(函数)
构造函数(构造方法):
(init是initalize初始化的简写)
__init__(self,...):初始化函数(非常重要,用于大部分通用变量)(注意:是两个下划线_连在一起)
函数名(self,...):普通函数
参数表可以有多个参数,但是必须有self并且self必须放在第一个,self不用手动传递参数(就是个规则)
类的实例化(就是调用类):
同理前面调用自带的函数一样
类名(参数)
class student:
def __init__(self,name,class_idx):#初始化函数init
self.name=name
self.class_idx=class_idx
A=student("小明",'一班')
print(A.name,A.class_idx)类中访问当前对象的属性和方法:通过self
对象访问属性和方法:用"."运算符
class student:
def __init__(self,name,class_idx):
self.name=name
self.class_idx=class_idx#外部输入参数赋值给类
def output(self):#这个方法不用额外的参数,全部都在初始化函数里有
print(self)
print(self.name)
A=student("小明",'一班')
print(A.name,A.class_idx)
b=student('小米',2)
b.output()属性和方法
属性看作变量,方法看作函数
这里概念多
属性
类属性(类里面的变量,自带的):在类体中、但是在所有函数外定义的变量,使用时:类名.变量名
实例属性(实例给的变量,需要赋值):以self.变量名定义的变量,使用时:实例名.变量名 或 self.变量名(在初始化函数内)

方法
实例方法:一般在类中定义的方法默认都是实例方法,使用时:实例名.方法名 或者 self.方法名(在初始化函数内)(就是只有定义过的例子能用
类方法:同理实例方法,也要至少一个参数,不过通常将这个参数命名为cls(和self同理,不过cls对应的是整个class,self对应的是某个对象),并且需要在类方法前加@classmethod修饰符进行修饰,使用时:类名.方法名(整个类都能用
类静态方法:没有self,cls这类特殊参数,不能调用任何类属性和类方法,使用@staticmethod修饰,使用时:类名.方法名


上面这部分比较重要
常用库函数
这部分比较简单
内置模块
模块:就是python文件,包括很多函数,类,变量等
导入方法:

使用方法:
1:模块名称.对应方法
2:别名.对应方法
3:子模块名称.对应方法
4:已将模块所有东西导入,直接使用,不用前缀
常用自带内置函数




实践应用
自定义排序
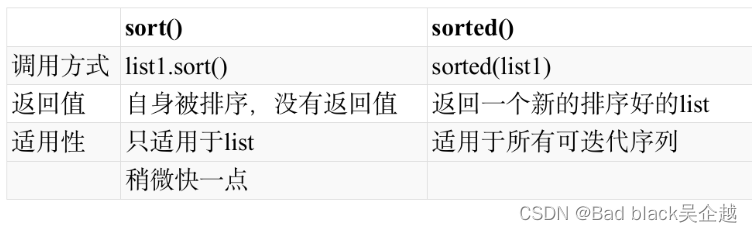
sort
list可以直接使用
a.sort([self,key=None,reverse=False])
同理sorted,默认是升序
a=[1,3,2]
a.sort()#正确调用
print(type(a))
print(a)
#以下是错误的调用,sort不能立刻赋值
b=a.sort()
print(b)sorted
sorted(可迭代对象[,key=None,reverse=False]):
key:用来比较的对象,只有一个参数,指定可迭代对象中的一个元素进行排序
reverse(顺序):默认的False是升序,可改为True降序
自定义函数
一般比纯数字用不着,比
写一个比较函数cmp再套入functools模块中的cmp_to_key
比数字:
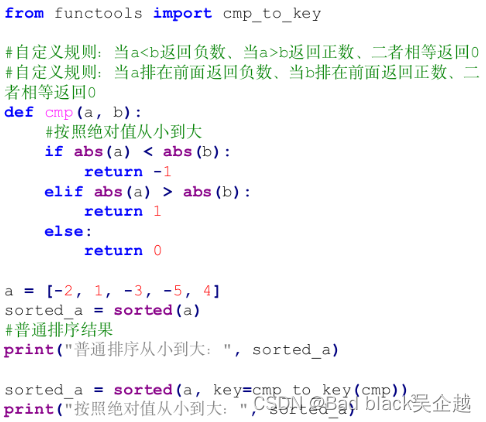
比坐标:

比字符串:

笔者目前还没深究这部分。。
二分查找(插入)
bisect中文意思是平分(就是二分从中间分)
维护一个已排序列表(注意:必须已经排好),支持二分查找,二分插入
注意:这里需要使用第四种导入内置模块方法:from bisect import *
二分查找
bisect_left(a,x[,lo=0,hi=len(a)]):从左往右查找a中第一个x的位置,返回位置下标
bisect_right(a,x[,lo=0,hi=len(a)]):从右往左查找a中第一个x的位置但是返回位置+1
lo 和 hi 为可选参数,分别定义查找范围/返回索引的上限和下限
from bisect import *
a=[1,2,3,4,5,6,7]
x=2
c=bisect_left(a,x)
print(c,type(c))若不存在这个查找的数x:
x比最小的小:返回0
x比最大的大:返回len(a)+1
x介于b,c之间:返回c
二分插入
同理
insort_left(a,x[,lo=0,hi=len(a)]):查找到该位置后插入x,只修改列表不返回列表
insort_right(a,x[,lo=0,hi=len(a)])
from bisect import *
a=[1,2,3,4,5,6,7]
x=5.6
insort_right(a,x)
print(a)结束语
有缘再见















 1752
1752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









