






前言
详见第一章上前言
目录
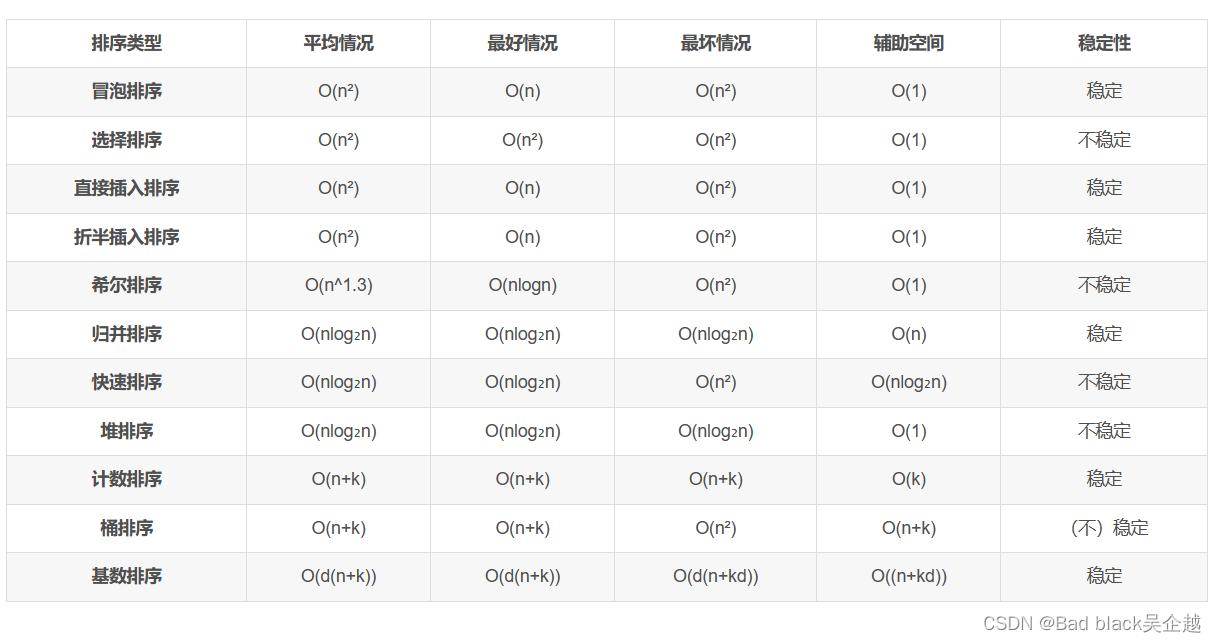
时间复杂度和空间复杂度(铺垫)
简单来说,举个写作业的例子,时间复杂度就是总共作业布置了多少题,空间复杂度就是你每次同时能计算多少道题。
详见:http://t.csdnimg.cn/ckRKm或者http://t.csdnimg.cn/Wo0Y3
排序
冒泡排序
相信学过C语言的都知道,使用两层循环即可
就是每轮循环把一个最大或者最小值推到最后
长度为n,则要循环n-1轮
时间复杂度O(n^2),空间复杂度O(1),稳定
选择排序
同理,学过C的两种排序之二,又称“打擂台”,和冒泡一样也是使用两层循环即可
就是每轮把当轮最值挑出放在前面(从哪边开始哪边就是前边)
所以同理,时间复杂度O(n^2),空间复杂度O(1),稳定
相比冒泡笔者个人更喜欢选择
插入排序
和选择有点像,都是把一个跟多个比
区别是选择是把一个“擂主”跟多个没挑出来的比,插入是把一个“当前位置”跟多个已经挑出来的比
举个例子,相当于按身高排队,老师从第五个位置5号拿出一个,跟前面四个依次比,前面四个已经是从矮到高排好了的,此时5号需要从一个方向依次比(比如从矮的比),直到比到有比5号高的就插入在那个比5号高的同学的前面。678...以此类推(但是相当于5号后面的到已经排好的最后一个都要向后移动一位,事实上要一个个比,居然不能一次全部移动玩,笔者觉得不太好,可能笔者想的是另一种排序吧,不过要是笔者这样的话需要多一次循环,可能时间复杂度更大。。。)
和选择一样,时间复杂度O(n^2),空间复杂度O(1),但是不稳定
具体实现:
有[0,i-1]个从小往大排好的,第i个插入,从后往前比,j为n个之一,在操作i和j比大小时
若a[i]<a[j],则第j个要后移一位,给a[i]留位
若a[i]>=a[j],则就把a[i]放在a[j+1]留出的空位上
eg:
n = int(input()) # 读取整数个数
a = list(map(int, input().split())) # 读取整数列表
for i in range(1, n): # 从第二个元素开始遍历
value = a[i] # 当前要插入的元素
insert_idx = 0 # 初始化插入位置为0(实际上这个初始化是多余的,因为下面会找到正确的插入位置)
for j in range(i - 1, -1, -1): # 逆向遍历已排序的元素(这步是从倒数下标i-1+1=i个到倒数下标第-1+1=0个
if a[j] > value:
a[j + 1] = a[j] # 已排序元素大于当前元素时,已排序元素后移
else:
insert_idx = j + 1 # 找到插入位置
break # 退出内层循环
a[insert_idx] = value # 在正确的位置插入当前元素(注意这里的缩进)
print(' '.join(map(str, a))) # 打印排序后的列表笔者说的方案:三次循环,更慢不好,只能说倒插倒着比确实有道理
n=int(input())
a = list(map(int,input().split()))
for i in range(1,n):
value=a[i]
insert_idx=0
for j in range(0,i):
if a[j]>value:
insert_idx=j
for x in range(j,i):
a[x+1]=a[x]
a[insert_idx] = value
print(' '.join(map(str,a)))快速排序
时间复杂度:O(nlog(n)),空间复杂度:O(nlog(n)),不稳定
简单来说,不断的递归(子问题),把原序列变成三部分:小于x,x,大于x,直到最终序列长度为1
具体代码有很多种写法:比如用三个列表的
def quicksort(arr):
# 如果数组长度小于等于1,则直接返回该数组
if len(arr) <= 1:
return arr
else:
# 选择第一个元素作为基准
pivot = arr[0]
# 构造小于等于基准的元素构成的子数组 less 构造大于基准的元素构成的子数组 greater
less = [x for x in arr[1:] if x <= pivot] # 输出比第一个元素小的列表
greater = [x for x in arr[1:] if x > pivot] # 输出比第一个元素大的列表
print('less-----------', less)
print('greater-----------', greater)
# 递归地对这两个子数组进行快速排序,然后将它们合并起来,并加上基准元素
return quicksort(less) + [pivot] + quicksort(greater)
if __name__ == '__main__':
arr = [3, 5, 2, 8, 1, 4]
sorted_arr = quicksort(arr)
print(sorted_arr)
或者:只动一个
# coding=utf-8
def quick_sort(array, start, end):
if start >= end:
return
mid_data, left, right = array[start], start, end
while left < right:
while array[right] >= mid_data and left < right:
right -= 1
array[left] = array[right]
while array[left] < mid_data and left < right:
left += 1
array[right] = array[left]
array[left] = mid_data
quick_sort(array, start, left-1)
quick_sort(array, left+1, end)
if __name__ == '__main__':
array = [10, 17, 50, 7, 30, 24, 27, 45, 15, 5, 36, 21]
quick_sort(array, 0, len(array)-1)
print(array)归并排序
时间复杂度:O(nlog(n)),空间复杂度:O(n),稳定
引入:
两个已经排好序的列表合并成一个排好序的列表(多个也可以)
简单来说:不断的将两列表的首元素比较,弹出极值,直到一边列表空了,另外一边的列表就直接移动到最后

备注:pop函数删除同时会返回删除值(前面说过)
def Merge(A,B):
result=[]
while len(A)!=0 and len(B)!=0:
if A[0]<=B[0]:
result.append(A.pop(0))
else:
result.append(B.pop(0))
result.extend(A)
result.extend(B)
return result
c=[1,2,4]
d=[3,5]
print(Merge(c,d))所以归并排序就是把列表不断(递归处理!)拆成两半直到有序,然后再像上面那样合起来

a=list(map(int,input().split()))
def Mergesort(A):
if len(A)<2:
return A
mid=len(A)//2
left=Mergesort(A[mid:])
right=Mergesort(A[:mid])
return Merge(left,right)
def Merge(A,B):#用来合并两个列表的
result=[]
while len(A)!=0 and len(B)!=0:
if A[0]<=B[0]:
result.append(A.pop(0))
else:
result.append(B.pop(0))
result.extend(A)
result.extend(B)
return result
#print(Mergesort(a))
print(' '.join(map(str,Mergesort(a))))笔者感觉这个好写一点
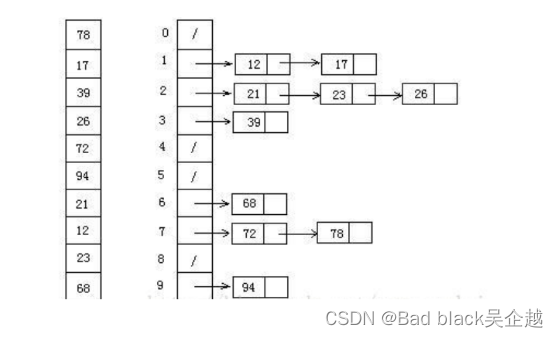
桶排序
更加彻底的归并排序,化整为零


比如按照十位上的数分类:则一个桶负责0-9,10-19...依次类推
from itertools import chain
def Bucket_sort(a,bucketcount):#bucketcount是有多少个数字要排序
minvalue,maxvalue=min(a),max(a)#测量排序的数字的范围
bucketsize=(maxvalue-minvalue+1)//bucketcount#每个桶的大小,注意要加一
res=[[]for i in range(bucketcount+1)]#创建bucketcount个空桶空二维列表,空列表res里面有bucketcount个二维列表
for x in a:
idx=(x-minvalue)//bucketsize#将排序的元素分桶
res[idx].append(x)
for res_x in res:#在每个桶里的res_x分别排序,可以采用其他排序算法
res_x.sort()
return list(chain(*res))#chain还没学到
n=int(input())
a=list(map(int,input().split()))
a=Bucket_sort(a,min(n,10000))#最多10000个桶
print(' '.join(map(str,a)))
总结:
笔者目前认为快速排序最难写
基础算法
时间复杂度
前面铺垫提到过



这里最后的是nlog2(n),但是带回没看明白,不是T(n)=4T(n/4)+2O(n/2)+O(n)吗
枚举
就是所有可能的都试一遍(一般配合循环)
步骤:
1.确定解空间(一维,二维...)
2.确定空间边界(每个变量的最小值,最大值,步长)
3.估算时间复杂度(由前文两次讲时间复杂度)
4.如果超时,则减少枚举空间,变换枚举顺序,重新从1开始
模拟
感觉一般之前做的简单题都是模拟
就是按照题目要求模拟,一般不涉及算法
注意:重复的可以写成函数,分块调试
递归
在C的汉诺塔问题见过
递归:通过自己调用自己把原问题不断变成规模较小的问题,最后层层返回
注意:递归的出口设计(在哪里停止递归哪里就是出口。返回时要能层层返回)和如何把当前问题变成子问题
eg:递归版阶乘函数
def jiecheng(x):
if x<=1:
return 1#递归出口(出口在前)
res=x*jiecheng(x-1)
return res
print(jiecheng(int(input())))eg2:递归版pow(a,b)
def new_pow(a,b):
if b<=1:
return a
result=a*new_pow(a,b-1)
return result
a,b=map(int,input().split())
print(new_pow(a,b))进制转换
在大学计算机这门课上学过,位权和基数
python也有自带的转换函数(见第一章)
基数:表示基本数字符号的个数
eg:16进制:0-9,A-F基数为16
位权(权):每位表示的数值
eg:123十进制1表示1个100,2表示2个10
位权=基数^从右往左的位数下标(从0开始,小数部分则从左往右)
任意进制转十进制
每个位的位权×基数之和
模拟代码:
int_to_char = '0123456789ABCDEF'
char_to_int = {}
for idx,char in enumerate(int_to_char):
char_to_int[char]=idx
print(char_to_int)#用于生成一个最高可用于十六进制的位权表
def K_to_10(k,x):
ans=0
for char in x:
ans = ans*k + char_to_int[char]
return ans
print(K_to_10(8,'11'))
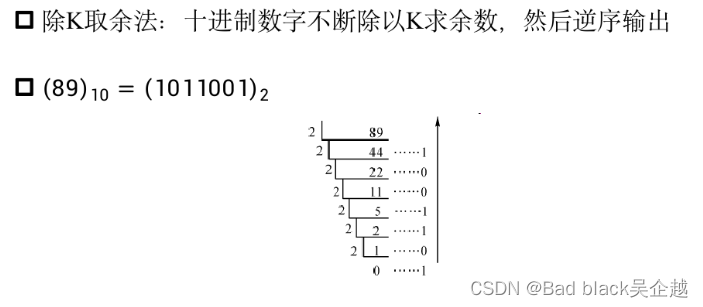
十进制转任意进制
整数部分除K取余法,小数部分乘K取余法

模拟代码:
int_to_char = '0123456789ABCDEF'
def Ten_to_K(k,x):#整数部分才行
ans=''
while x != 0:
ans= ans + int_to_char[x % k]#相当于累加余数
x = x// k#整除k
return ans[::-1]
print(Ten_to_K(8,10))前缀和
前缀和
感觉上就像求总和
前缀和:一般是可迭代的前缀和列表(这里用sum代表),对于一个长度为n的列表a
Sum[i]=a[1]+a[2]+...+a[i]
eg:a=[1,3,4,2,5],sum=[1,4,8,10,15]
前缀和性质:
sum[i]=sum[i-1]+a[i]用于循环得出前缀和
a[left]+...+a[right]=sum[right]-sum[left-1]可以在O(1)时间内求出区间和(前缀和的用途之一)
#求出a的前缀和
def get_presum(a):
n=len(a)
sum=[0]*n
sum[0]=a[0]
for i in range(1,n):
sum[i]=a[i]+sum[i-1]
return sum
#求区间a[l]...a[r]之和
def get_sum(sum,l,r):
if l==0:
return sum[r]
else:
return sum[r]-sum[l-1]
a=[1,2,3,4,5]
sum=get_presum(a)
print(a)
print(sum)
print(get_sum(sum,2,3))或者将求出前缀和改为内置函数:accumulate是个迭代器?可以连续求
#求出a的前缀和
from itertools import accumulate
def get_presum(a):
sum=list(accumulate(a))
return sum二维前缀和
这里比较抽象,故用图片加描述

两个求和符号放在一起的意思其实就跟两层for循环一样,就是遍历这一片区域(先求和x=1,y=1到j再到x=2....一直到底),这一片区域的求和。
eg:sum22=a11+a12+a21+a22

这是因为sumi-1j,sumij-1算了两遍ai-1j-1,所以要减去多出来的一遍,最后在加上右下角的aij就是sumij
同理:(也是减两条边,减多了再补)(意思是在这个x1y1x2y2范围内的前缀和)

具体代码:
def output(a,n):#用来print输出的函数
for i in range(1,n+1):
print(' '.join(map(str,a[i][1:])))#[1:]从下标1开始输出到末尾的a
n,m=map(int,input().split())#输入行数和列数
#下标从1开始
a=[[0]*(m+1) for i in range(n+1)]#建立空的初始二维列表(并且尺寸大1)
sum=[[0]*(m+1) for i in range(n+1)]#建立空的二维前缀和列表
for i in range(1,n+1):#输入二维数组
a[i]=[0]+list(map(int,input().split()))#因为下标是从1开始,故第一位放0占位
output(a,n)#输出初始二维列表
for i in range(1,n+1):
for j in range(1,m+1):
sum[i][j]=sum[i-1][j]+sum[i][j-1]-sum[i-1][j-1]+a[i][j]
output(sum,n)#输出二维前缀和列表看了一会儿写出注释还是可以理解的
def get_quyu_sum(x1,y1,x2,y2):
sum_quyu=sum[x2][y2]-sum[x1-1][y2]-sum[x2][y1-1]+sum[x1-1][y1-1]
print(sum_quyu)
x1,y1,x2,y2=map(int,input().split())#输入x1,y1,x2,y2
get_quyu_sum(x1,y1,x2,y2)这个是对应区域前缀和的模块和调用
差分
相当于求和的逆运算,就求差
差分数组

即后一项减前一项的差
注意:差分数组的第一项diff[1]=a[1]并不是做差
差分数组前缀和求原数组其实就是移项
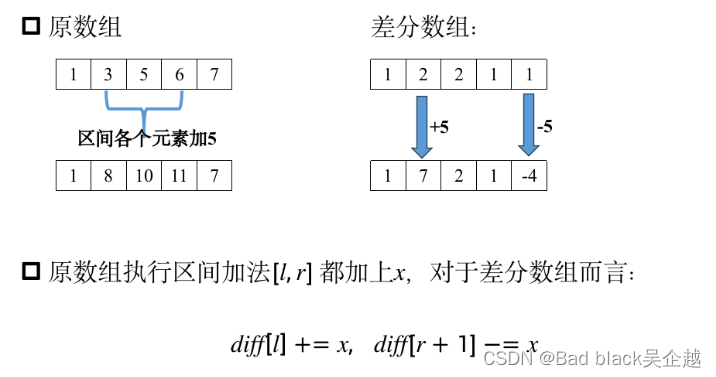
diff[l]=diff[l]+x,diff[r+1]=diff[r+1]-x

注意:第三四点,改变很多原数组数字,但是差分数组只有一位(分别是diff[l]和diff[r+1])发生变化
具体代码:
n,m=map(int,input().split())
a=list(map(int,input().split()))
diff=[0]*(n+1)#构建差分数组,也是从第一位开始所以长一个单位
diff[0]=a[0]
for i in range(1,n):
diff[i]=a[i]-a[i-1]
#区间求和转换成差分数组
for _ in range(m):#这里用不到迭代值所以下划线
x,y,z=map(int,input().split())
x,y=x-1,y-1
diff[x]=diff[x]+z
diff[y+1]=diff[y+1]-z
#对差分数组求前缀和
a[0]=diff[0]
for i in range(1,n):
a[i]=a[i-1]+diff[i]
print(' '.join(map(str,a)))这里笔者还不是很清楚中间的x,y,z和输出是什么
二维差分数组
关键在于一维数组和二维数组都有:差分数组的前缀和=原数组

这是个很有趣的套娃(还有移项)
替换的原因:sum是前缀和,而差分数组的前缀和=原数组。因此差分数组diff(就是a的差分)的前缀和sum就是原数组a
最终的结果:主对角线减副对角线
def output(a,n):#用来print输出的函数
for i in range(1,n+1):
print(' '.join(map(str,a[i][1:])))#[1:]从下标1开始输出到末尾的a
n,m=map(int,input().split())#输入行数和列数
#下标从1开始
a=[[0]*(m+1) for i in range(n+1)]#建立空的初始二维列表(并且尺寸大1)
sum =[[0]*(m+1) for i in range(n+1)]#建立空的二维前缀和列表
#新的:
diff=[[0]*(m+1) for i in range(n+1)]#建立空的二维差分列表
for i in range(1,n+1):#输入二维数组
a[i]=[0]+list(map(int,input().split()))#因为下标是从1开始,故第一位放0占位,同时可以防止第一排第一列out of index
output(a,n)#输出初始二维列表
for i in range(1,n+1):
for j in range(1,m+1):
sum[i][j]=sum[i-1][j]+sum[i][j-1]-sum[i-1][j-1]+a[i][j]
output(sum,n)#输出二维前缀和列表
#新的:二维差分·
for i in range(1,n+1):
for j in range(1,m+1):
diff[i][j]=a[i][j]-a[i-1][j]-a[i][j-1]+a[i-1][j-1]
output(diff,n)
当初始二维列表中间元素改变x后, 差分列表的改变(文字如下图

离散化
离散化:不关注数据的具体大小,只关注大小排名,利用排名代替原数据
本质:一种哈希,将离散的数字,浮点数转化为1-n
eg:[100,200,300,400,500]离散化为[1,2,3,4,5]
用于:仅关注偏序关系的问题,可以先离散化

from bisect import *
def Discrete(a):
b=list(set(a))#对a去重
b.sort()#对b排序,此时b列表的元素就是按照离散化顺序排的,他们的下标就是离散化之后的值(注意是下标!不是他本身)
ans=[]#输入的列表是a,返回的列表是ans
for i in range(len(a)):
ans.append(bisect_left(b,a[i]))#bisect是二分查找,详见第一章下,从左往右查找b中第一个a[i]的位置,返回下标(返回的是位置下标,不是值!即上面提到的离散化之后的值)
#相当于用查找把原列表a元素的顺序和离散化的值列表b合在一起
return ans#返回一个离散化后的列表
a=list(map(int,input().split()))
print(Discrete(a))
解释都在注释里,很巧妙。
贪心
贪心
就是一直选局部最优解




经典贪心
石子合并问题:求最小花费


import heapq
n=int(input())
a=list(map(int,input().split()))
heapq.heapify(a)
ans=0
while len(a)!=1:
x=heapq.heappop(a)
y=heapq.heappop(a)
heapq.heappush(a,x+y)
ans=ans+x+y
print(ans)还有几个例子这里省略
双指针
双指针
好处:降低时间复杂度
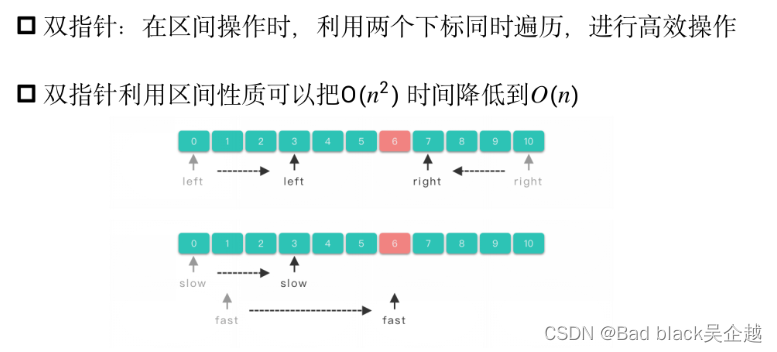
反向扫描

在快速排序(还是某个排序)里用过反向扫描类似的
















 2255
2255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









