










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的麦田杂草检测算法系统
设计思路
一、课题背景与意义
小麦是我国主要的粮食作物之一。然而,田间杂草的存在严重影响了小麦的生长环境。及时控制和清除杂草对于小麦拥有健康的生长区域和吸收更多的田间养分至关重要。目前,小麦田间的主要除草方式包括手工锄草、除草剂和机械除草。然而,这些方法存在效率低、对环境影响大以及破坏农田结构等问题。因此,使用搭载杂草检测模型的除草装置成为未来发展的趋势。这些检测模型必须具备高效性和精准性。
二、算法理论原理
2.1 卷积神经网络
卷积神经网络(CNN)是一种源于人工神经网络的网络结构,在深度学习中广为应用,并成为最著名的网络结构之一。系统采用了基础网络模型yolov5s作为图像目标检测的CNN模型。起初,CNN主要用于手写数字识别任务,在该任务上取得了领先水平的成果。进入本世纪以来,CNN的出色性能被应用于图像识别、自然语言处理等多个领域。设计一个神经网络最重要的是确定其结构,包括单元、深度和连接方式等。神经网络是由多个层级组成的连锁式结构,每一层都是前一层的函数。优秀的网络结构具有层次深、每层单元数目少、参数较少等特点。
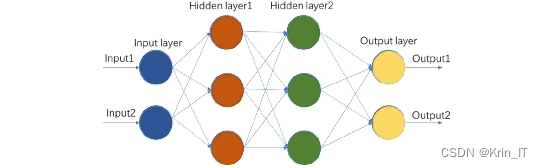
在使用CNN进行图像检测任务时,通常按照以下步骤进行:首先对输入图像进行特征提取,然后经过卷积层和池化层处理,随后利用激活函数得到特征图。最后,特征图通过全连接层进行进一步的检测和识别,得到最终的识别结果。
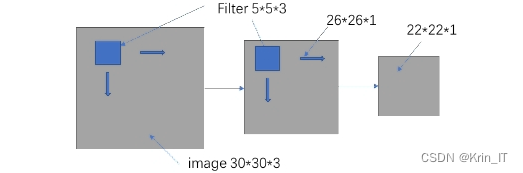
卷积是CNN的基本组成部分,如下所示。输入图像矩阵表示为灰色部分,大小为30×30×3,其中3表示RGB三个通道。卷积核矩阵表示为蓝色部分,大小为5×5×3,即感受野。通过矩阵运算(元素相乘再相加),将卷积核与图像矩阵进行卷积操作,滑动方向为从左至右、从上至下,得到一个大小为26×26×1的特征图。可以将该特征图作为输入图像矩阵,继续使用卷积核进行卷积操作,得到更深层次的特征,如22×22×1特征图。
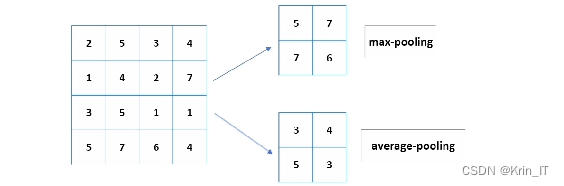
池化层(Pooling)又称为下采样,其功能是压缩特征矩阵的维度尺寸,以简化后续计算的复杂度。池化层通常位于卷积层之后,对卷积层的结果进行进一步压缩,降低图像尺寸并减少参数数量。常用的池化方法有两种:最大值池化(Max-Pooling)和均值池化(Average-Pooling)。池化操作选取图像特征的部分值进行计算,因此具有旋转和平移不变性。最大值池化和均值池化如下所示。经过池化操作后,图像特征的尺寸减小,同时减少了原图的信息量(参数数量减少),但保留了最重要的特征信息,减轻了后续计算的负担。
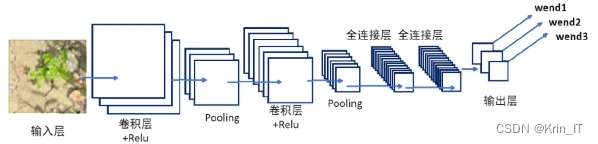
2.2 图像检测
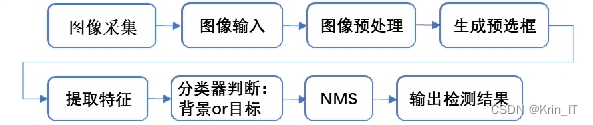
图像检测的一般流程图如下所示。主要包括以下步骤:
1. 图像采集:收集待检测的图像数据。
2. 待测图像输入:将采集到的图像输入到检测系统中。
3. 图像预处理:对输入图像进行预处理,包括去除噪声、增强对比度等操作。
4. 生成候选框:通过算法生成图像中可能包含目标的候选框。
5. 提取特征:从候选框中提取特征,用于后续的分类和识别。
6. 特征分类:对提取到的特征进行分类,判断目标是否存在。
7. 候选框优化:对候选框进行优化,去除冗余或错误的候选框。
8. 输出检测结果:将最终的检测结果输出。
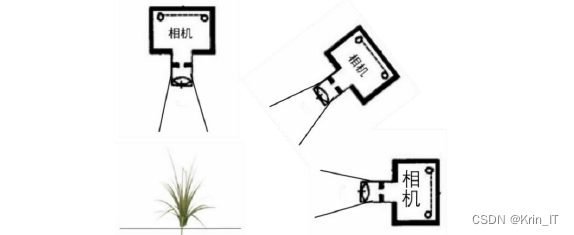
原始小麦和杂草图像均来源于真实的种植环境。杂草图像是以0º、45º和90º的拍摄角度使用智能手机进行拍摄的,具体拍摄细节见下图。
共收集了来自小麦和杂草的8种常见杂草数据集,总共包含1360张图像样本,拍摄周期为三个月。为了增加训练后检测模型的鲁棒性,尽可能多地获取了作物和杂草在不同生长周期下的图像。收集的样本图像分为9类标签,每类杂草的样本保存在同名文件夹中。

采集到的每张图像经过人工筛选,使用LabelImg软件完成标签分类标注。具体标注过程如下所示。最终制作了小麦杂草数据集。由于所有原始图像都是实地拍摄的,因此可能存在杂草外貌不全、图像模糊或与杂草品种不符等问题,这些都是制作数据集时需要删除的干扰项。经过筛选后,图像数据集的数量为1125张。为了增加样本数据的多样性,还对数据集进行了五种常规数据增强操作,包括镜像、高斯噪声、旋转、随机裁剪和灰度。

图像经过预处理不仅恢复对研究内容有用的信息,还去除无用、不感兴趣的信息,提升相关信息的可检测性和最大限度地简化数据,进而提升特征提取、图像分割、分类识别的稳定性。最常用的图像数据预处理操作有归一化和正则化。
图像归一化还会减去均值并除以方差的操作,移除图像的平均亮度值。在机器视觉任务中,一般不考虑样本中的亮度因素,而更关注研究对象的主体。例如,在对杂草进行目标检测时,图像的亮度不会影响到图像中存在哪种杂草。通过对各样本进行亮度统计平均值,可以去除图像的同一成分,突出不同杂草的主体差异。

图像分割是图像检测过程中至关重要的一步,通过适当的分割凸显模型感兴趣的研究对象(如本文研究的各种杂草本体),同时淡化模型不感兴趣的物体(如土壤、杂草周围的环境背景,即噪音部分),以便模型能够准确识别杂草。目前最常见的方法是基于阈值分割。
阈值分割的基本原理是以循环的方式将阈值与输入图像中的每个像素点进行对比,并采用并行方式进行像素对比,从而得到被划分的图像区域。其中,灰度阈值分割法是最常用的方法。在阈值分割法中,给定一个确定的阈值T,能够完整、准确地将图像分割,将属于研究物体的区域标记为1,背景或模型不感兴趣的物体标记为0。

三、麦田杂草检测的实现
3.1 yolov5s目标检测模型
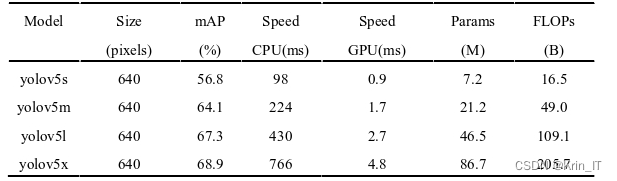
YOLO系列中最新一代的目标检测网络是YOLOv5,在灵活性和速度上有显著提升,具有极强的快速部署优势。YOLOv5s是整个系列中特征图宽度和卷积深度最小的网络,其他三个模型都是在YOLOv5s的基础上逐渐增加卷积深度和特征图宽度。YOLOv5s具有更均衡的综合性能,具有较高的mAP值,训练后的模型内存较小,加载速度快,物体检测速度也快。
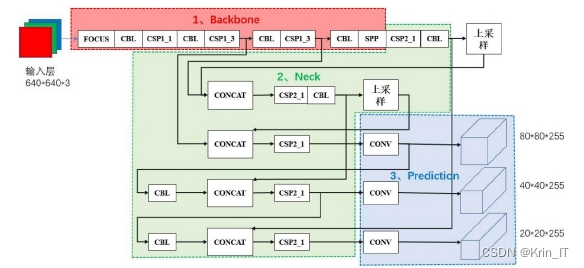
Focus结构的主要功能是进行分割,它将尺寸为3*608*608的输入图像经过一次Focus切片运算,转换为尺寸为12*304*304的特征图。YOLOv4网络模型在BackBone网络中只使用CSP结构,而YOLOv5网络模型创新地引入了两种全新的CSP_X结构,BackBone采用CSP1_1结构和CSP1_3结构,Neck采用CSP2_1结构,加强了网络之间的特征融合。
3.2 CBMA注意力机制
注意力机制是一种能够在整体中聚焦于局部信息的机制,其在神经网络的隐藏层中实现,通过增加特征的加权来引入注意力。可以将注意力机制和池化操作进行类比比较。在CNN中,池化可以看作是一种特殊的平均加权注意力机制,反之亦然,注意力机制也可以被视为一种通用的基于参数的池化方法(包含参数的池化方法)。
在目标检测任务中,注意力机制的作用是让模型学会忽略无关信息,找到对检测任务最有用的信息。随着研究任务的变化,注意力机制会在不同的区域发挥作用,并对关注的方向和加权模型进行调整。下图展示了在一个杂草叶片图像样本上使用注意力机制生成的注意力图。图中颜色越深表示对该区域的关注程度越高,其权重也越大。

3.3 改进后的yolov5s目标检测模型
在FPN中,信息从顶部流向下层,逐层传递。每一层的proposal只负责对应金字塔的一层,这导致了超长的传递路径和巨大的计算量。为了解决这个问题,提出了PANet。PANet的模块结构如图所示,它在FPN的基础上进行了三个方面的改进。
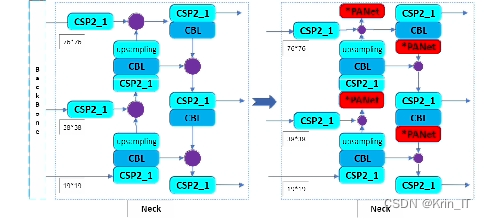
在yolov5s网络结构中,BackBone使用CSP_1来提取输入图像的特征,提取到的特征图传递到Neck端的Concat,然后经过CSP2_1进行特征融合。在Concat和CSP2_1之间引入PANet网络,PANet能够结合更多的上层和下层特征信息,确保信息传递、准确保持空间信息和像素位置,并增强网络特征的融合能力。PANet-yolov5s改进模型结构如图所示。PANet是对FPN的改进设计,通过添加自顶向下的路径解决了FPN的单向传递结构的缺陷,目前将FPN替换为PANet是一种主流做法。
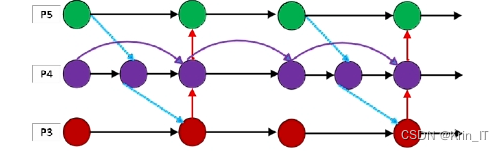
BiFPN是在PANet的基础上进行改进的。由于PANet中每个节点只有一个输入边,所以在输入后没有进行特征融合,对基于多个特征对象的特征网络的贡献较少,因此BiFPN去除了PANet中只有一条输入边的节点。在其他FPN模块中,不同特征尺度的融合直接相加,但它们对最终检测的贡献不同。BiFPN通过学习不同输入特征的权重,在网络中为不同特征层设置不同的权重大小,得到最佳的权重设置参数,并减少不必要的层节点连接。在BiFPN中,当两个节点处于相同层级时,从原始输入节点到输出节点新增一条边,以进一步减少计算量,在不增加模型计算成本的情况下实现更多特征的融合。整个BiFPN结构中,每条双向通道被视为一个特征网络层,通过多次合并可以实现更高层次的特征融合。
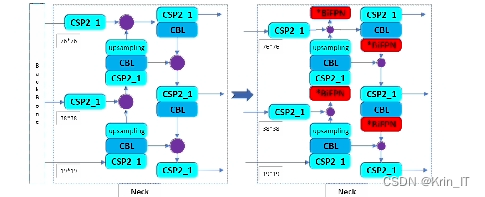
BiFPN的引入位置也是在Concat和CSP2之间,在PANet的基础上以较低的成本融合更多特征,通过添加额外的权重,不同特征的贡献量不同,使网络学习到每个特征层的重要性,从而在杂草检测中提供更好的性能。
部分代码如下:
# 加载训练好的模型
model = load_model('weed_detection_model.h5')
# 定义类别标签
class_labels = ['weed', 'non-weed']
# 加载图像
image = cv2.imread('field_image.jpg')
# 对图像进行预处理
image = cv2.resize(image, (224, 224))
image = image.astype('float') / 255.0
image = np.expand_dims(image, axis=0)
# 使用模型进行预测
predictions = model.predict(image)
predicted_class = np.argmax(predictions)
# 获取预测结果
class_label = class_labels[predicted_class]
confidence = predictions[0][predicted_class] * 100
# 在图像上绘制结果
cv2.putText(image, f'{class_label}: {confidence:.2f}%', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Weed Detection', image)
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









