










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的输电线路巡检中的目标检测系统
设计思路
一、课题背景与意义
随着电力需求的持续增长,电力基础设施的安全性和可靠性显得尤为重要。电线杆作为输电线路的重要组成部分,其周边环境的安全和障碍物的管理直接关系到电力传输的稳定性与安全性。传统的人工巡检方式不仅效率低下,还容易受到天气、环境和人为因素的影响,导致潜在隐患未能及时发现和处理。基于深度学习的自动检测系统能够通过图像识别技术,实时监测电线杆周围的障碍物,如树木、建筑物和其他物体。这一系统的核心在于利用卷积神经网络(CNN)等深度学习算法,自动提取图像特征并进行分类与识别。通过该系统,可以显著提高障碍物检测的准确性和实时性,降低人工巡检的成本与风险。
二、算法理论原理
2.1 卷积神经网络
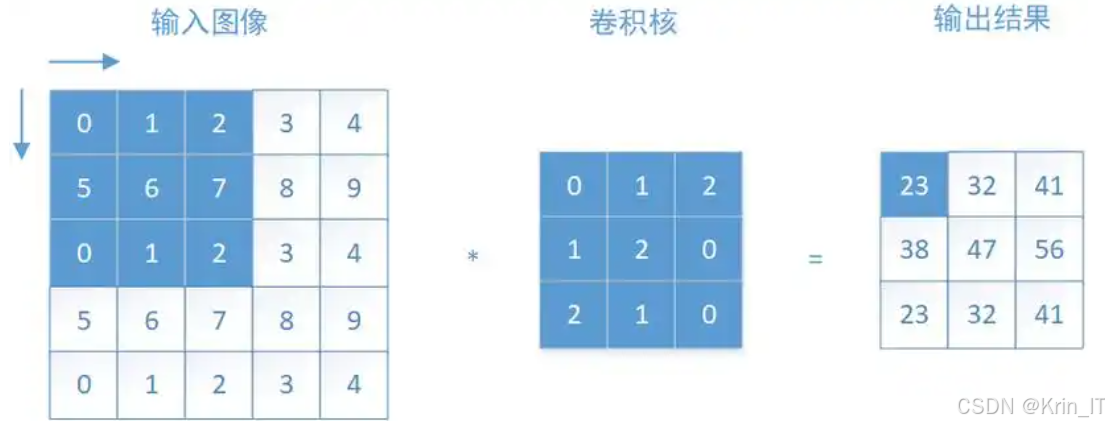
障碍物自动检测系统采用卷积神经网络作为核心模型。卷积神经网络通过局部感受野和参数共享的方式,能够高效地提取图像中的重要特征。在该系统中,卷积层通过多个卷积核对输入的图像进行滑动卷积操作,生成特征图,使得网络能够自动识别电线杆周围的障碍物,例如树木、建筑物和其他物体。这种自动化的特征提取机制显著减少了对人工特征设计的依赖,提升了模型在复杂环境下的识别能力,确保了障碍物检测的准确性。
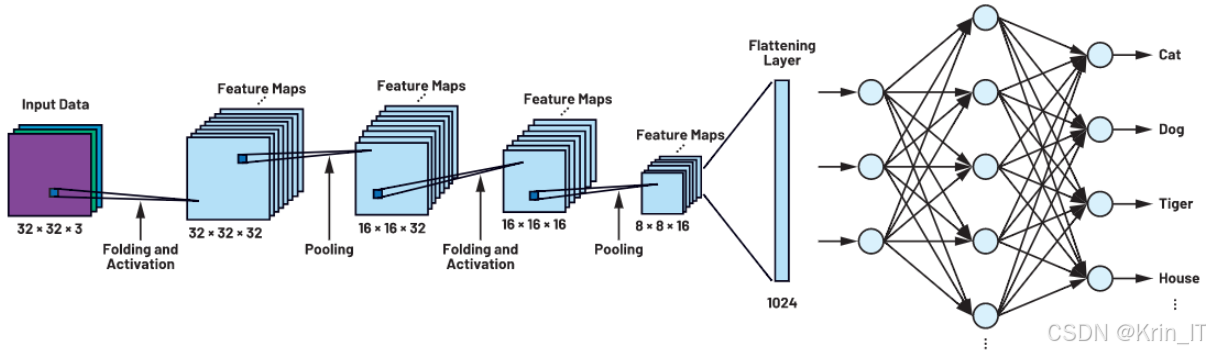
系统的结构包括卷积层、激活层、池化层和全连接层。卷积层提取特征后,激活层通过非线性函数(如修正线性单元)引入非线性因素,提高模型的表达能力。池化层则通过减少特征图的尺寸,降低计算量,并增强模型对不同输入条件的鲁棒性。全连接层将提取到的特征映射到最终的输出结果,提供障碍物的分类和位置信息。通过这些层的组合,卷积神经网络能够有效处理图像数据,实现电线杆输电线路障碍物的自动检测。
高效的特征提取能力使其能够准确识别各种障碍物,大幅提高了巡检效率。优秀的空间不变性确保了系统在不同场景下的可靠性,有助于适应复杂的环境变化。相较于传统的人工巡检方式,基于深度学习的检测系统能够快速处理大规模图像数据,满足实时监测的需求。引入池化层和正则化技术,有效防止过拟合,提高了模型在新数据上的泛化能力,使得系统在面对未知障碍物时仍能保持高效的检测性能。基于深度学习的电线杆输电线路障碍物自动检测系统为电力行业提供了一种智能化、自动化的解决方案,极大地提升了巡检工作的安全性和效率。
2.2 目标检测算法
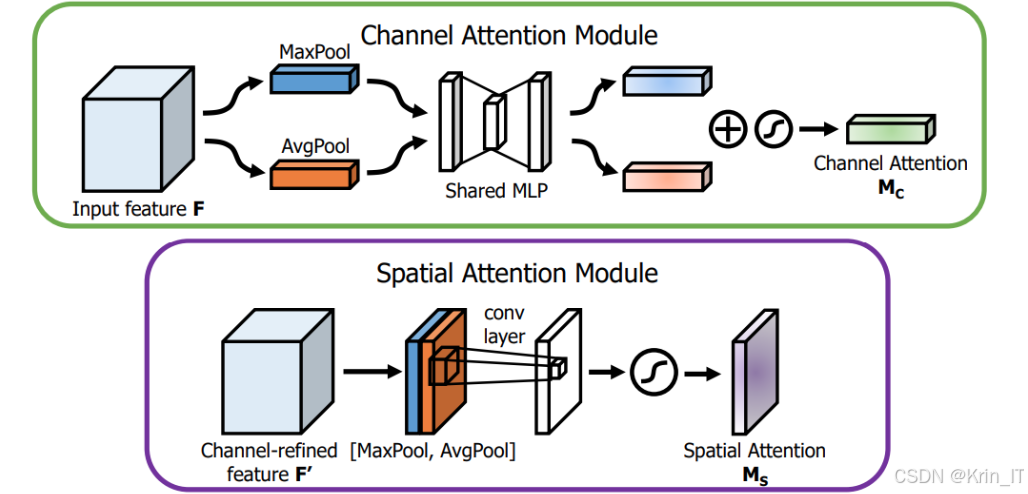
CBMA机制通过对特征通道和空间维度的注意力加权,提高了卷积神经网络对重要特征的敏感性。首先,通道注意力部分通过计算各个特征通道的重要性,动态调整对不同通道的关注程度。模型能够自适应地增强重要通道的特征,同时抑制不重要通道的影响,优化特征表达。其次,空间注意力部分关注输入特征图的空间信息,通过评估特征图中每个位置的重要性,增强对关键区域的关注。引入CBMA机制,进一步增强了特征提取的能力。这一机制使得模型能够更好地捕捉目标的空间信息,提升检测精度。在复杂环境中,CBMA机制帮助模型有效应对噪声影响,从而增强了系统的鲁棒性,使得障碍物检测更加可靠。
传统的IoU损失函数在目标检测任务中虽然广泛应用,但在某些情况下表现出局限性,尤其是在处理目标边界不准确或重叠区域较小的情况时,可能导致模型训练不充分。α-IoU通过引入可调参数α,使得损失函数能在目标检测的精度与召回率之间进行平衡。具体而言,α的不同取值使得损失函数能够自适应地调整对重叠区域的关注程度,从而提升模型在实际应用中的表现。当α取值较大时,模型更倾向于优化预测框与真实框之间的重叠度,确保高精度的目标识别;而当α取值较小时,模型则鼓励尽可能多地检测到目标,增强召回率。这种灵活性使得α-IoU能够在多样化的检测场景中自适应调整,显著提升了模型的整体性能和稳定性。
三、检测的实现
3.1 数据集
数据集采集过程中,首先需要制定详细的采集计划,明确目标区域和障碍物种类。数据采集通常在不同的环境和天气条件下进行,以确保数据的多样性和代表性。使用高分辨率相机或无人机装备进行图像拍摄,捕捉电线杆及其周围障碍物的多角度图像,确保涵盖不同的障碍物类型,如树木、建筑物和其他物体。此外,记录每张图像的采集时间、地点和天气条件等信息,为后续的数据分析提供背景支持。

在数据标注阶段,采用专业的标注工具对采集到的图像进行精确标注。标注团队成员需要为每张图像中的障碍物绘制边界框,并分配相应的标签,如“树木”、“气球”等。为确保标注的准确性,标注过程通常会经过多轮自检和互检,及时修正任何错误和遗漏。完成标注后,将数据导出为标准格式,形成结构化的数据集,为后续的模型训练和验证提供高质量的基础。这一完整的数据采集和标注过程,为电线杆输电线路障碍物的自动检测系统奠定了坚实的基础。

3.2 实验环境搭建
在基于Windows操作系统的深度学习环境中,PyTorch、OpenCV、Pandas和LabelImg是四个重要的软件工具,构成了强大的数据处理和分析平台。PyTorch作为灵活的深度学习框架,提供了动态计算图和丰富的模型库,使得研究人员能够方便地构建和训练复杂的神经网络。OpenCV则是一个开源的计算机视觉库,专注于图像处理和分析,支持多种图像和视频处理算法,非常适合在图像预处理和特征提取阶段使用。Pandas是数据处理和分析的利器,以其强大的数据结构和数据操作功能,使得处理和分析大型数据集变得高效且直观。LabelImg作为图像标注工具,方便用户对数据集中的图像进行精确标注,为训练深度学习模型提供高质量的标注数据。这四个工具的结合,使得在Windows环境下进行电线杆输电线路障碍物自动检测的研究和开发变得更加高效、灵活,为实现自动化检测系统奠定了坚实的基础。
3.3 实验及结果分析
数据集应包括各种环境和条件下的电线杆及其周围障碍物的图像。这些图像需要经过标注,以便模型能够学习到障碍物的特征。常用的标注格式包括Pascal VOC和COCO格式,标注工具如LabelImg可以帮助用户进行精确的标注。
# 安装LabelImg标注工具
!pip install labelImg
# 运行LabelImg标注工具
!labelImg数据预处理是训练过程中的重要步骤,旨在确保输入数据符合模型的要求。预处理步骤通常包括图像缩放、归一化、数据增强等。图像缩放将图像调整到网络输入所需的尺寸,归一化则将像素值调整到特定范围(如0到1),而数据增强通过随机变换(如旋转、翻转、裁剪等)来扩充训练集,增加模型的泛化能力。
from torchvision import transforms
# 定义数据预处理流程
transform = transforms.Compose([
transforms.Resize((256, 256)), # 调整图像大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]), # 归一化
])
# 使用数据增强
data_aug = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
])在训练模型之前,需要将数据集划分为训练集和验证集。通常,训练集占大多数(如80%),验证集占少数(如20%)。训练集用于模型的学习,而验证集用于在训练过程中评估模型的性能,以防止过拟合。
from sklearn.model_selection import train_test_split
# 假设data和labels为图像数据和对应标签
train_data, val_data, train_labels, val_labels = train_test_split(data, labels, test_size=0.2, random_state=42)选择合适的深度学习模型是模型训练流程中的重要步骤。对于电线杆输电线路障碍物检测,常用的模型包括YOLO、SSD和Faster R-CNN等。这些模型在目标检测任务中表现出色。可以使用PyTorch或TensorFlow等框架构建模型,利用预训练模型进行迁移学习可以进一步提升模型的性能。
在训练过程中,将训练数据输入模型,通过前向传播计算损失,并通过反向传播更新模型参数。使用适当的优化器(如Adam或SGD)和损失函数(如交叉熵损失),可以有效地提高模型性能。通过设置合适的学习率和训练轮数,确保模型能够收敛。
import torch.optim as optim
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(num_epochs):
model.train()
for images, targets in train_loader:
optimizer.zero_grad() # 清零梯度
outputs = model(images) # 前向传播
loss = criterion(outputs, targets) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
在训练完成后,使用验证集对模型进行评估。评估指标通常包括准确率、召回率、F1-score和mAP(mean Average Precision)。通过这些指标可以判断模型在未见数据上的表现,进而决定是否需要调整模型结构或训练参数。
from sklearn.metrics import precision_score, recall_score
# 假设val_outputs和val_targets为验证集的预测结果和真实标签
precision = precision_score(val_targets, val_outputs, average='weighted')
recall = recall_score(val_targets, val_outputs, average='weighted')
print(f'Precision: {precision}, Recall: {recall}')创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









