







 本文探讨了一个计算机专业的毕设课题,即开发一个旅游数据可视化与分析系统,利用Python和多种算法(如随机森林、支持向量机、LSTM和KNN)进行客流量预测和游客评论分析。通过数据集构建和实验,展示了如何运用这些算法实现数据预处理、预测模型和结果评价。
本文探讨了一个计算机专业的毕设课题,即开发一个旅游数据可视化与分析系统,利用Python和多种算法(如随机森林、支持向量机、LSTM和KNN)进行客流量预测和游客评论分析。通过数据集构建和实验,展示了如何运用这些算法实现数据预处理、预测模型和结果评价。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于python的旅游数据可视化与分析系统
设计思路
一、课题背景与意义
随着旅游业的迅速发展,对旅游数据进行有效的分析和可视化成为了提升旅游业竞争力的关键。然而,传统的数据处理和分析方法往往无法满足日益增长的数据规模和复杂的分析需求。旅游数据可视化与分析系统,能够高效处理旅游数据,提取有价值的信息,并通过直观的可视化方式呈现给用户,为旅游行业决策、市场调研和旅游规划提供准确全面的数据支持,推动旅游业的健康发展。
二、算法理论原理
2.1 客流量预测
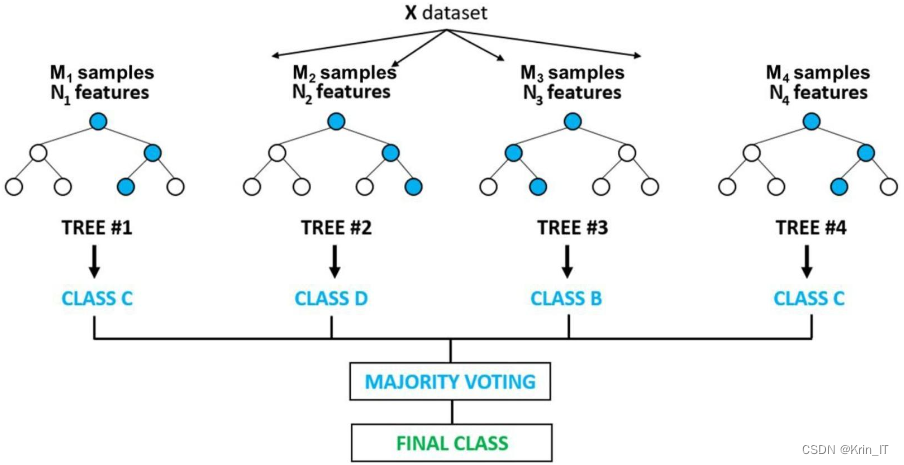
随机森林是一种集成学习算法,通过构建多棵基于CART决策树的弱学习器,并将其集成以提高预测的稳定性和准确性。在训练过程中,随机森林使用有放回的随机抽样来创建不同的训练集,并对每个样本集独立地训练决策树。这些树在节点分裂时会随机选择特征和最佳分割点。最终,对于分类问题,随机森林通过多数投票确定类标签;对于回归问题,它通过平均预测值来预测结果。这种方法因其鲁棒性和较高的准确性而在许多领域得到广泛应用。
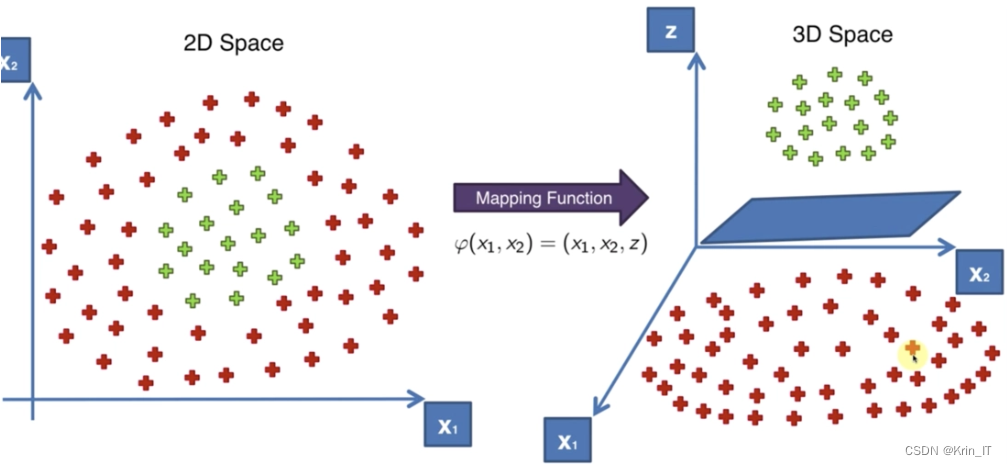
支持向量机(SVM)是一种强大的监督学习算法,由Vapnik等人于1995年提出。它特别适用于处理小样本数据集,并且能够处理非线性和高维数据。SVM通过寻找一个最优的超平面来实现数据的二元分类,这个超平面能够最大化分类边界的间隔,从而提高分类的准确性。此外,SVM也可以应用于回归问题,通过寻找一个最优的超平面来拟合数据。SVM的这些特性使其在模式识别、函数拟合以及其他机器学习问题中成为一种非常有用的工具。
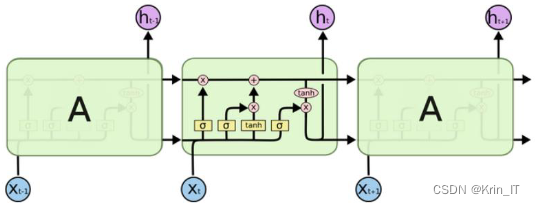
长短时记忆神经网络(LSTM)是一种特殊的循环神经网络(RNN),它通过设计输入门、遗忘门和输出门以及细胞状态,有效地解决了传统RNN在处理长序列数据时遇到的梯度消失和梯度爆炸问题。LSTM的这些门和细胞状态使得网络能够有选择地记住或遗忘信息,从而能够捕捉到长序列数据中的长期依赖关系。因此,LSTM在各种序列处理任务中表现优异,如自然语言处理、时间序列分析和语音识别等。
2.2 游客评论分析
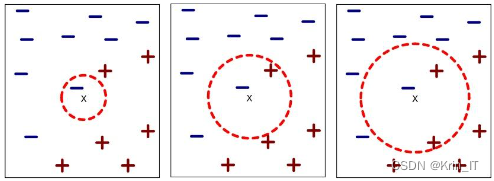
K最近邻算法(KNN)是一种简单有效的机器学习算法,主要用于分类任务。它的基本思想是,给定一个训练数据集,对于新的输入实例,算法会计算其与训练集中每个实例的距离,并找出与其最近的k个实例。然后,根据这k个邻近实例的标签来预测新实例的类别。KNN算法的性能很大程度上取决于超参数k的选择、距离度量方法以及分类决策规则。
距离度量是KNN算法的另一个关键因素,它用于评估两个实例之间的相似性。常见的距离度量包括欧氏距离、曼哈顿距离、夹角余弦、pL距离和明科夫斯基距离等。对于文本数据挖掘等任务,夹角余弦距离因其能够有效表示向量特征的方向性而常用。
极端梯度提升算法(XGBoost)是一种强大的机器学习算法,它在众多数据科学竞赛和实际应用中表现卓越。XGBoost的核心优势在于其高效性、灵活性和准确性。首先,它采用了梯度提升框架,通过迭代地训练决策树来优化损失函数,从而提高了模型的预测性能。同时,引入正则化项有助于避免过拟合,使模型在未知数据上的泛化能力更强。XGBoost在每次迭代中使用梯度下降来最小化损失函数,同时限制模型的复杂度。它采用了一阶导数来更新模型,并引入了二阶导数来优化损失函数。通过不断地迭代训练,XGBoost能够逐步提升模型的性能,最终得到一个高性能的预测模型。
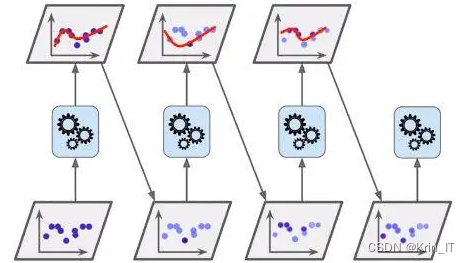
三、检测的实现
3.1 数据集
由于网络上缺乏现有的合适旅游数据集,本研究决定自行进行数据收集。通过网络爬取各大旅游网站、社交媒体平台和公共数据源,获取相关的旅游数据,包括旅游景点的评分、评论、游客数量等信息。这个自制的数据集包含了真实的旅游行业数据和丰富的用户反馈,为研究提供了更准确、可靠的数据基础。
3.2 实验及结果分析
在预测结果评价中,选取了四个指标:平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)作为评价指标。MAE衡量了预测值和观测值之间的平均绝对误差,MSE衡量了预测值和观测值之间的平方误差的平均值,RMSE是MSE的平方根,表示预测值和观测值之间的平方误差的均方根,而MAPE计算了绝对误差和真实值之间的百分比误差的平均值。这些指标能够全面评估预测结果的准确度、误差程度和相对误差,从而帮助评估和比较模型的性能。
相关代码示例:
# 绘制柱状图,显示各地区的游客数量
plt.figure(figsize=(10, 6))
sns.barplot(x='Region', y='Visitor Count', data=data)
plt.title('Visitor Count by Region')
plt.xlabel('Region')
plt.ylabel('Visitor Count')
plt.show()
# 绘制折线图,显示某个地区的游客数量变化趋势
region_data = data[data['Region'] == 'Region A']
plt.figure(figsize=(10, 6))
plt.plot(region_data['Year'], region_data['Visitor Count'], marker='o')
plt.title('Visitor Count Trend in Region A')
plt.xlabel('Year')
plt.ylabel('Visitor Count')
plt.show()实现效果图样例:




创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









