







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于关联规则的图书馆图书个性化推荐系统
设计思路
一、课题背景与意义
图书馆作为知识传播和学术研究的重要场所,拥有大量的图书资源。然而,由于图书馆的图书数量庞大,读者在找到适合自己的图书时常常感到困惑。图书馆图书个性化推荐系统能够根据读者的兴趣和阅读历史,通过挖掘图书之间的关联规则,为读者提供个性化的图书推荐,帮助他们更有效地选择适合自己的图书。这不仅能提高读者的阅读体验,还能促进图书馆资源的更好利用,推动图书馆的服务水平提升。
二、算法理论原理
2.1 基于内容的推荐算法
基于内容的推荐算法(CB)是一种利用项目的内容信息进行推荐的方法。它的核心思想是通过机器学习方法从项目的特征描述中提取用户的兴趣信息,而不是直接依赖用户对项目的评价意见来进行推荐。该算法考虑项目之间的关联性和项目本身所包含的信息,从而更准确地反映用户对物品的兴趣。基于内容的推荐算法通过计算推荐项目之间的相关性,并结合用户的偏好信息,向用户推荐与其兴趣高度契合的物品。
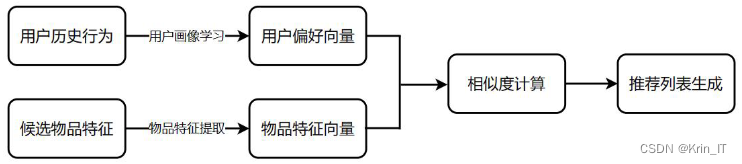
基于内容的推荐算法通过利用项目的特征属性来对项目或用户进行定义。它根据用户对项目特征的评价,理解并构建用户的兴趣模型,并与待预测项目进行匹配度检验。用户兴趣模型的构建可以使用不同的学习方法,如决策树、神经网络或基于向量的表示方法等。这种算法具有直观性,能够处理非结构化或半结构化数据,并且不存在冷启动问题。
2.2 协同过滤推荐算法
协同过滤算法( CF)是一种经典且广泛应用的推荐算法,完全基于用户与物品之间的行为关系来进行推荐。协同过滤算法利用数据挖掘技术对用户的历史行为进行深入挖掘,以获得用户的偏好,并根据这些偏好对用户进行分类,并将兴趣属性相近的项目推荐给用户。
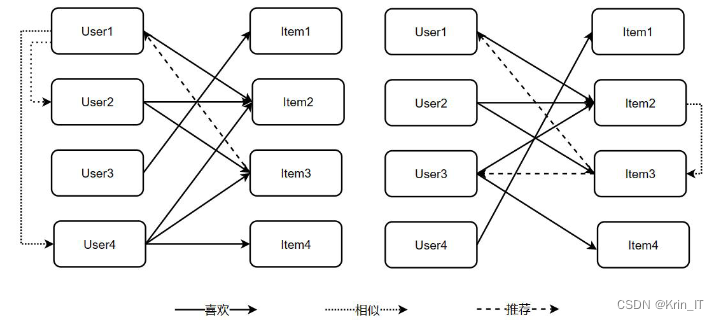
协同过滤算法主要分为两类:基于项目的协同过滤算法(Item-Based CF, ICF)和基于用户的协同过滤算法(User-Based CF, UCF)。基于项目的协同过滤算法向用户推荐与其之前"喜欢"的项目相似的项目,而基于用户的协同过滤算法则向目标用户推荐其相似用户所喜欢的项目。基于用户的协同过滤算法主要研究用户之间的相似性,它查找与目标用户相似的用户所喜欢的物品,并相应地预测目标用户对这些物品的评分,然后将评分最高的几个物品推荐给目标用户。而基于项目的协同过滤算法类似于基于用户的协同过滤算法,但不同之处在于它寻找项目与项目之间的相似性,并将相似度最高的项目推荐给用户。
2.3 关联规则推荐算法
在大规模推荐系统中,由于用户无法对所有物品进行评价和评分,导致评分数据十分稀疏,这会影响推荐结果的准确性。为了解决这个问题,可以采用融合属性综合相似度的混合预填充算法来尽可能填充原本稀疏的评分矩阵。该算法利用物品的属性信息和相似度计算方法,预测用户对物品的评分。在预填充后的评分矩阵基础上,可以使用协同过滤算法来进一步预测用户对物品的评分。协同过滤算法利用用户之间的行为关系,通过找到相似用户或相似物品来进行推荐。然而,单独使用协同过滤算法可能会存在数据稀疏性的问题。强关联规则可以有效表达物品之间的潜在关联关系,而且只需使用较少数量的强关联规则就能表示所有有效的关联信息。通过将协同过滤与关联规则所获得的预测评分进行加权混合,可以得到最终的预测评分,并生成Top-N推荐结果。这种混合方法可以更好地发挥协同过滤和关联规则的优势,提高推荐结果的准确性。
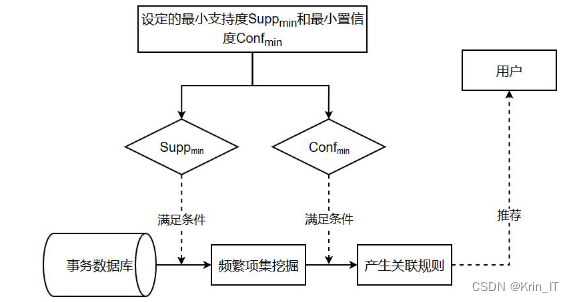
混合推荐算法通过多个步骤来提高推荐结果的准确性和个性化程度。首先,使用混合预填充方法对评分数据进行填补,得到稀疏度较低的用户-项目评分矩阵,并构建项目-属性矩阵。然后,计算项目的属性相似度和基于用户评分的项目属性相似度,并将它们加权混合得到项目的综合相似度。接着,选择最近邻的项目,并利用其评分预测用户对项目的评分。同时,建立项目属性集和用户-项目属性矩阵,记录项目属性的关联信息。最终,综合利用预填充的评分矩阵和关联规则的信息,生成最终的推荐结果。
三、检测的实现
3.1 数据集
由于网络上没有现有的合适的数据集,我决定自己进行网络爬取,收集了大量的图书馆相关数据,并制作了一个全新的数据集。这个数据集包含了图书馆的图书信息、读者的借阅记录以及读者的兴趣标签等多种数据。通过网络爬取和数据整理,我能够获取真实的图书馆数据,这将为我的研究提供更准确、可靠的数据。对数据集进行了数据标注,为每本图书添加了相应的标签和分类信息,以便系统能够更准确地推荐符合读者兴趣的图书。数据标注的过程中,我结合了领域专家的知识和算法模型的辅助,确保了数据的准确性和质量。
3.2 实验环境搭建

3.3 实验及结果分析
图书馆图书个性化推荐系统的设计思路如下:
-
数据收集与预处理:首先,收集图书馆的读者借阅记录、图书属性信息和读者个人信息等数据。对数据进行预处理,包括去除噪声数据、填补缺失值和标准化处理,以便后续的分析和建模。
-
关联规则挖掘:使用关联规则挖掘算法(如Apriori算法)对读者借阅记录进行分析,发现图书之间的关联关系。通过设置最小支持度和最小置信度阈值,筛选出频繁项集和相关的关联规则。这些关联规则可以揭示图书之间的隐含关系,例如频繁共同借阅的图书或者相似主题的图书。
-
个性化推荐模型构建:基于挖掘到的关联规则,构建个性化推荐模型。一个常用的方法是基于关联规则的推荐算法,通过将读者已借阅的图书作为条件,推荐与这些图书相关的其他图书。根据关联规则的置信度和支持度,筛选出符合要求的推荐图书列表。
-
评估与优化:使用评估指标(如准确率、召回率和覆盖率)对个性化推荐模型进行评估。根据评估结果,进行模型的优化和调整,例如调整关联规则挖掘的参数或改进推荐算法的策略,以提高推荐的准确性和用户满意度。
相关代码示例:
def calculate_user_based_similarity(ratings, attribute_similarity):
user_based_similarity = ...
return user_based_similarity
def blend_similarity(attribute_similarity, user_based_similarity, alpha):
blended_similarity = alpha * attribute_similarity + (1 - alpha) * user_based_similarity
return blended_similarity
def select_neighbors(blended_similarity, k):
neighbors = ...
return neighbors
def predict_ratings(ratings, neighbors):
predicted_ratings = ...
return predicted_ratings
def hybrid_recommendation(ratings, items, alpha, k):
filled_ratings = prefill(ratings)
attribute_similarity = calculate_attribute_similarity(items)
user_based_similarity = calculate_user_based_similarity(filled_ratings, attribute_similarity)
blended_similarity = blend_similarity(attribute_similarity, user_based_similarity, alpha)
neighbors = select_neighbors(blended_similarity, k)
predicted_ratings = predict_ratings(filled_ratings, neighbors)
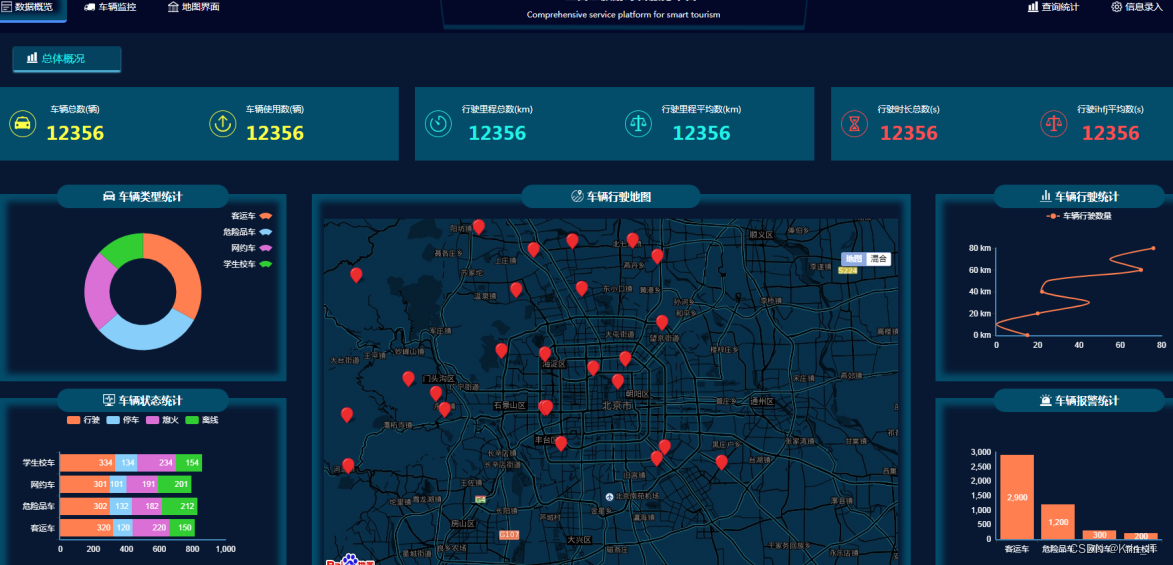
return predicted_ratings实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 2454
2454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









