







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的流浪动物(猫、狗)检测与分类系统研究
设计思路
一、课题背景与意义
随着城市化进程的加速,流浪动物问题日益严重,特别是流浪猫和流浪狗的数量不断增加,给城市管理、公共安全和动物保护带来了挑战。流浪动物不仅可能威胁公共卫生,还可能导致交通事故、生态失衡等社会问题。因此,及时、准确地识别和分类流浪动物,成为社会治理和动物救助的重要任务。传统的流浪动物监测方法往往依赖人工巡查,效率低下且难以实现实时监控。结合深度学习模型,能够实现对流浪猫和流浪狗的自动识别,从而提供数据支持,帮助相关机构制定更有效的救助和管理策略。
二、算法理论原理
2.1 神经网络
传统图像识别技术提取图像特征,如颜色、形状、纹理等。当待识别特征过多时,建立特征库的难度增加,识别难度也随之增大,故传统图像识别技术仍需改进。使用基于深度学习的卷积神经网络(CNN)进行图像识别,可以有效克服上述问题。深度神经网络内部的参数大小通过反向传播算法获得,无需人工设定。经过训练的网络模型能够完成对数据集中复杂特征的提取和分类。卷积神经网络源于哺乳动物的视觉认知机制,是目前表现良好的深度模型之一,在深度学习的发展中占据了重要地位。其权值共享网络结构降低了模型的复杂度,减少了参数的数量。
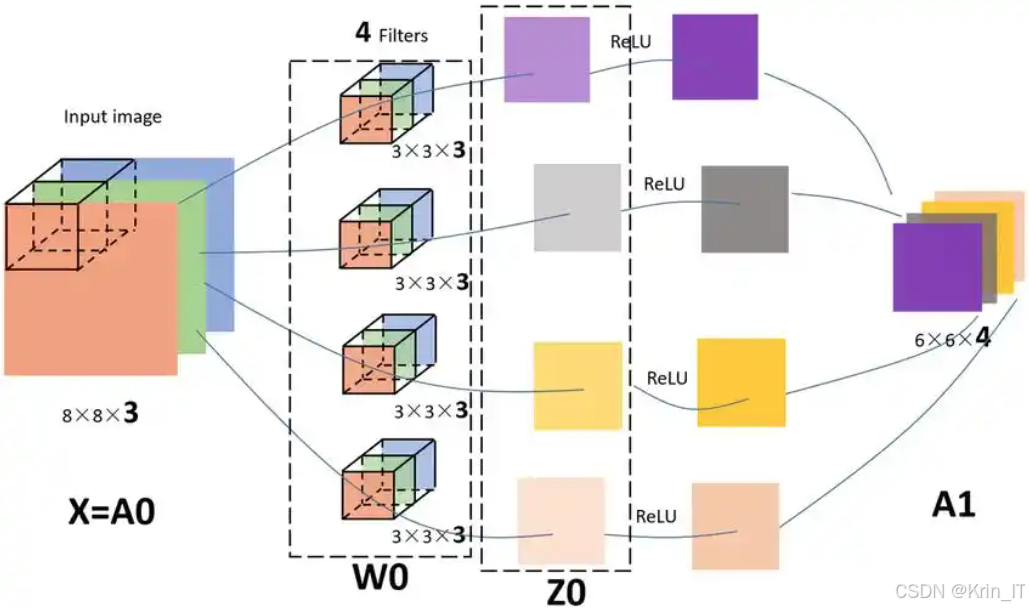
卷积神经网络(CNN)是一种深度学习模型,广泛用于图像识别和处理任务,其结构通常由多个主要组成部分构成。首先,输入层负责接收原始图像数据,通常为多维数组,彩色图像的维度通常为宽度×高度×通道数。这一层的主要任务是将图像数据传递给后续的卷积层。
- 卷积层是CNN的核心部分,主要功能是提取图像特征。通过使用多个卷积核(过滤器)对输入图像进行卷积操作,生成特征图。每个卷积核会扫描输入图像,并计算局部区域的加权和,从而捕捉到图像中的边缘、纹理等低级特征。卷积操作通常伴随有激活函数(如ReLU),以引入非线性特性。
- 激活层通常紧随卷积层之后,用于引入非线性因素。最常用的激活函数是ReLU(Rectified Linear Unit),其能够有效地解决梯度消失问题,提升网络的学习能力。池化层的主要作用是对特征图进行下采样,减少特征图的尺寸,降低计算复杂度和内存消耗,同时保留主要特征。常用的池化操作包括最大池化和平均池化,其中最大池化通过取局部区域的最大值来生成新的特征图。
- 在卷积层和池化层之后,通常会有一个或多个全连接层。这些层将提取到的特征进行汇总,最终输出分类结果。全连接层的每个神经元与前一层的所有神经元相连接,其主要功能是对提取到的特征进行综合分析。输出层一般是一个全连接层,负责将网络的最终特征映射到目标类别上。在分类任务中,输出层通常使用Softmax激活函数来计算每个类别的概率。
2.2 机器学习
支持向量机(SVM)是Vapnik等人提出的基于结构风险最小化原则的分类算法。支持向量机算法的决策只由支持向量决定,因此冗余样本很少影响分类结果,所得到模型的鲁棒性和泛化性良好。SVM常用于模式识别、分类及回归分析,能够有效解决高维数识别和非线性问题。支持向量机属于二分类算法,将区分不同种类数据的界限定义为超平面,距离该超平面最近的点定义为支持向量。SVM以寻找距离支持向量最远的超平面为目标,保证两者间的间隔尽量最大,使得分类算法的误差最小,从而确保算法具备良好的健壮性。支持向量机进行分类的步骤包括:对样本进行训练,创建分类器;使用训练好的分类器对待测样本分类;得到分类结果。
K最近邻算法(KNN)是一种直观且易于实现的非参数分类方法,广泛应用于模式识别、数据挖掘和机器学习等领域。由于KNN不依赖于数据的分布假设,它能够有效处理各种类型的数据集,尤其是当数据具有较高的维度和复杂的结构时。KNN的基本思路是通过测量样本之间的距离来进行分类,具体而言,它通过计算待分类样本与训练样本之间的距离来找到最近的K个邻居,然后根据这些邻居的类别进行投票,最终确定待分类样本的类别。
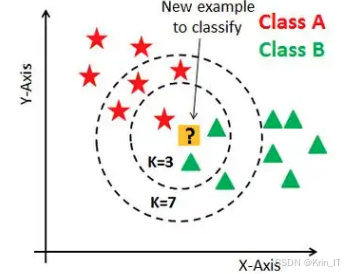
KNN的优势在于其简单性和灵活性。由于没有训练阶段,KNN能够迅速适应新数据,这使得它在动态环境中表现出色。此外,KNN算法也容易扩展到多分类问题,只需在投票过程中考虑每个类别的出现频率即可。
三、检测的实现
3.1 数据集
数据集的制作过程首先涉及图像采集可以选择自主拍摄和互联网采集相结合的方式。自主拍摄可以确保获得高质量、真实场景下的图像,能够捕捉到不同角度、光照和环境下的流浪动物特征。与此同时,互联网采集则可以丰富数据集,通过公开的图像库、社交媒体和动物保护组织的网站,获取大量多样化的流浪动物图像。使用标签工具LabelImg对收集到的图像进行标注。标注过程包括为每张图像中的流浪动物绘制边界框,并为其分配相应的类别标签(如“猫”或“狗”)。

数据集的划分与扩展是制作过程中的最后一步。通常将数据集划分为训练集、验证集和测试集,常见的比例为70%用于训练,15%用于验证,15%用于测试。此外,为了增强模型的鲁棒性和泛化能力,可以采用数据扩展技术,如图像旋转、翻转、裁剪、缩放和颜色调整等。
3.2 实验环境搭建

3.3 实验及结果分析
在训练模型之前,需要收集流浪动物的图像数据,并进行相应的预处理。预处理步骤包括数据清理、标签标注以及图像的标准化处理。数据集应包含多样化的样本,以确保模型能够学习到不同种类、不同角度和不同环境下的流浪动物特征。常见的预处理步骤包括调整图像大小、数据增强(如翻转、旋转、裁剪)和标准化像素值。
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
# 假设images和labels是已经加载好的图像和相应标签
images_resized = [cv2.resize(img, (224, 224)) for img in images] # 调整图像大小
images_normalized = np.array(images_resized) / 255.0 # 归一化处理
X_train, X_val, y_train, y_val = train_test_split(images_normalized, labels, test_size=0.2)使用了两种常用的分类器:支持向量机(SVM)和K最近邻(KNN)。KNN分类器采用十折交叉验证的方法来评估模型性能。由于分类器的参数设置对模型效果影响显著,因此使用网格搜索(Grid Search)结合十折交叉验证来自动评估不同参数组合的性能,以找到最佳配置。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
param_grid = {'n_neighbors': [3, 5, 7, 9], 'weights': ['uniform', 'distance']}
knn = KNeighborsClassifier()
grid_search = GridSearchCV(knn, param_grid, cv=10)
grid_search.fit(X_train, y_train)
best_knn = grid_search.best_estimator_使用预训练的卷积神经网络(CNN)模型,通常选择在ImageNet上训练成功的模型,如AlexNet。通过迁移学习,可以快速适应新的任务。首先,需要修改模型的最后一层,使其适应流浪动物的分类标签,然后通过微调网络的部分层,使模型在特定任务上获得更好的性能。训练模型的过程中,需要设定合适的超参数,如学习率、批处理大小和训练轮数。使用Adam优化器作为梯度下降算法。通过训练集进行训练,并使用验证集监控模型性能,防止过拟合。
from keras.applications import AlexNet
from keras.models import Model
from keras.layers import Dense, Flatten
base_model = AlexNet(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
x = Flatten()(base_model.output)
x = Dense(2, activation='softmax')(x) # 假设有两类:猫和狗
model = Model(inputs=base_model.input, outputs=x)
for layer in base_model.layers:
layer.trainable = False # 冻结预训练层
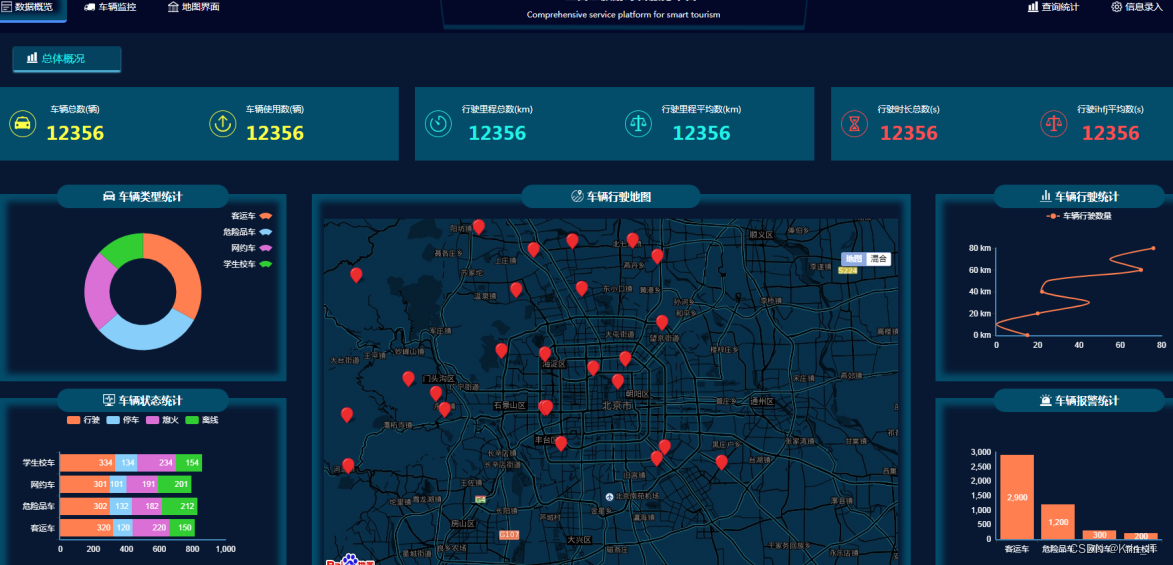
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])实现效果图样例:



创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 2150
2150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









